 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
TGC-Net: A Structure-Aware and Semantically-Aligned Framework for Text-Guided Medical Image Segmentation
Dec 24, 2025Text-guided medical segmentation enhances segmentation accuracy by utilizing clinical reports as auxiliary information. However, existing methods typically rely on unaligned image and text encoders, which necessitate complex interaction modules for multimodal fusion. While CLIP provides a pre-aligned multimodal feature space, its direct application to medical imaging is limited by three main issues: insufficient preservation of fine-grained anatomical structures, inadequate modeling of complex clinical descriptions, and domain-specific semantic misalignment. To tackle these challenges, we propose TGC-Net, a CLIP-based framework focusing on parameter-efficient, task-specific adaptations. Specifically, it incorporates a Semantic-Structural Synergy Encoder (SSE) that augments CLIP's ViT with a CNN branch for multi-scale structural refinement, a Domain-Augmented Text Encoder (DATE) that injects large-language-model-derived medical knowledge, and a Vision-Language Calibration Module (VLCM) that refines cross-modal correspondence in a unified feature space. Experiments on five datasets across chest X-ray and thoracic CT modalities demonstrate that TGC-Net achieves state-of-the-art performance with substantially fewer trainable parameters, including notable Dice gains on challenging benchmarks.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025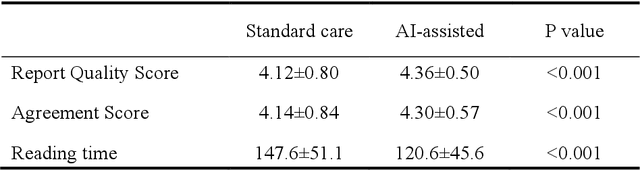
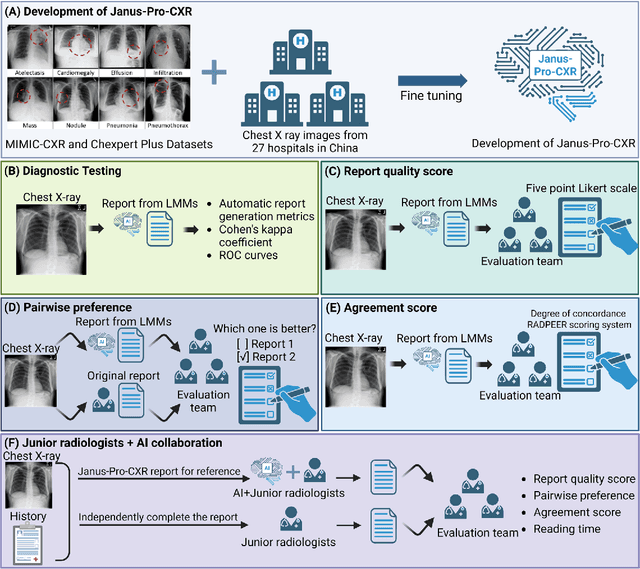
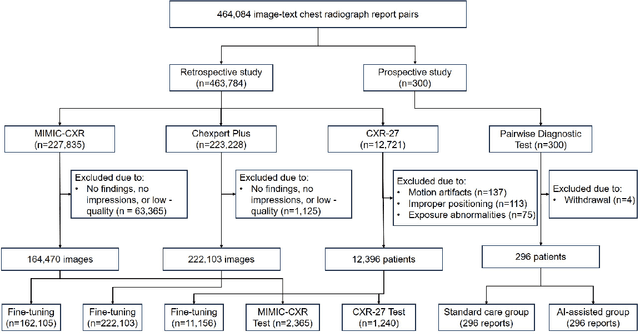
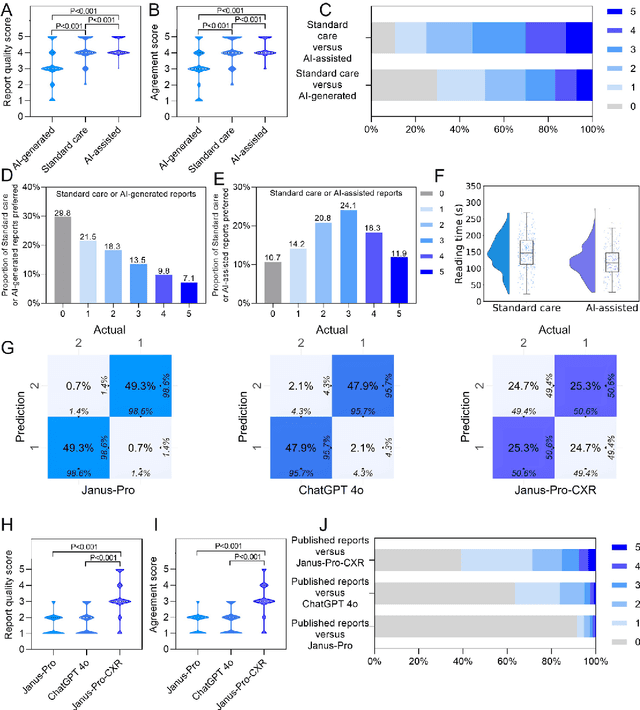
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
DINOv3-Guided Cross Fusion Framework for Semantic-aware CT generation from MRI and CBCT
Nov 15, 2025



Generating synthetic CT images from CBCT or MRI has a potential for efficient radiation dose planning and adaptive radiotherapy. However, existing CNN-based models lack global semantic understanding, while Transformers often overfit small medical datasets due to high model capacity and weak inductive bias. To address these limitations, we propose a DINOv3-Guided Cross Fusion (DGCF) framework that integrates a frozen self-supervised DINOv3 Transformer with a trainable CNN encoder-decoder. It hierarchically fuses global representation of Transformer and local features of CNN via a learnable cross fusion module, achieving balanced local appearance and contextual representation. Furthermore, we introduce a Multi-Level DINOv3 Perceptual (MLDP) loss that encourages semantic similarity between synthetic CT and the ground truth in DINOv3's feature space. Experiments on the SynthRAD2023 pelvic dataset demonstrate that DGCF achieved state-of-the-art performance in terms of MS-SSIM, PSNR and segmentation-based metrics on both MRI$\rightarrow$CT and CBCT$\rightarrow$CT translation tasks. To the best of our knowledge, this is the first work to employ DINOv3 representations for medical image translation, highlighting the potential of self-supervised Transformer guidance for semantic-aware CT synthesis. The code is available at https://github.com/HiLab-git/DGCF.
Refining Few-Step Text-to-Multiview Diffusion via Reinforcement Learning
May 26, 2025Text-to-multiview (T2MV) generation, which produces coherent multiview images from a single text prompt, remains computationally intensive, while accelerated T2MV methods using few-step diffusion models often sacrifice image fidelity and view consistency. To address this, we propose a novel reinforcement learning (RL) finetuning framework tailored for few-step T2MV diffusion models to jointly optimize per-view fidelity and cross-view consistency. Specifically, we first reformulate T2MV denoising across all views as a single unified Markov decision process, enabling multiview-aware policy optimization driven by a joint-view reward objective. Next, we introduce ZMV-Sampling, a test-time T2MV sampling technique that adds an inversion-denoising pass to reinforce both viewpoint and text conditioning, resulting in improved T2MV generation at the cost of inference time. To internalize its performance gains into the base sampling policy, we develop MV-ZigAL, a novel policy optimization strategy that uses reward advantages of ZMV-Sampling over standard sampling as learning signals for policy updates. Finally, noting that the joint-view reward objective under-optimizes per-view fidelity but naively optimizing single-view metrics neglects cross-view alignment, we reframe RL finetuning for T2MV diffusion models as a constrained optimization problem that maximizes per-view fidelity subject to an explicit joint-view constraint, thereby enabling more efficient and balanced policy updates. By integrating this constrained optimization paradigm with MV-ZigAL, we establish our complete RL finetuning framework, referred to as MVC-ZigAL, which effectively refines the few-step T2MV diffusion baseline in both fidelity and consistency while preserving its few-step efficiency.
GLFC: Unified Global-Local Feature and Contrast Learning with Mamba-Enhanced UNet for Synthetic CT Generation from CBCT
Jan 06, 2025



Generating synthetic Computed Tomography (CT) images from Cone Beam Computed Tomography (CBCT) is desirable for improving the image quality of CBCT. Existing synthetic CT (sCT) generation methods using Convolutional Neural Networks (CNN) and Transformers often face difficulties in effectively capturing both global and local features and contrasts for high-quality sCT generation. In this work, we propose a Global-Local Feature and Contrast learning (GLFC) framework for sCT generation. First, a Mamba-Enhanced UNet (MEUNet) is introduced by integrating Mamba blocks into the skip connections of a high-resolution UNet for effective global and local feature learning. Second, we propose a Multiple Contrast Loss (MCL) that calculates synthetic loss at different intensity windows to improve quality for both soft tissues and bone regions. Experiments on the SynthRAD2023 dataset demonstrate that GLFC improved the SSIM of sCT from 77.91% to 91.50% compared with the original CBCT, and significantly outperformed several existing methods for sCT generation. The code is available at https://github.com/intelland/GLFC
GaraMoSt: Parallel Multi-Granularity Motion and Structural Modeling for Efficient Multi-Frame Interpolation in DSA Images
Dec 19, 2024



The rapid and accurate direct multi-frame interpolation method for Digital Subtraction Angiography (DSA) images is crucial for reducing radiation and providing real-time assistance to physicians for precise diagnostics and treatment. DSA images contain complex vascular structures and various motions. Applying natural scene Video Frame Interpolation (VFI) methods results in motion artifacts, structural dissipation, and blurriness. Recently, MoSt-DSA has specifically addressed these issues for the first time and achieved SOTA results. However, MoSt-DSA's focus on real-time performance leads to insufficient suppression of high-frequency noise and incomplete filtering of low-frequency noise in the generated images. To address these issues within the same computational time scale, we propose GaraMoSt. Specifically, we optimize the network pipeline with a parallel design and propose a module named MG-MSFE. MG-MSFE extracts frame-relative motion and structural features at various granularities in a fully convolutional parallel manner and supports independent, flexible adjustment of context-aware granularity at different scales, thus enhancing computational efficiency and accuracy. Extensive experiments demonstrate that GaraMoSt achieves the SOTA performance in accuracy, robustness, visual effects, and noise suppression, comprehensively surpassing MoSt-DSA and other natural scene VFI methods. The code and models are available at https://github.com/ZyoungXu/GaraMoSt.
4DRGS: 4D Radiative Gaussian Splatting for Efficient 3D Vessel Reconstruction from Sparse-View Dynamic DSA Images
Dec 17, 2024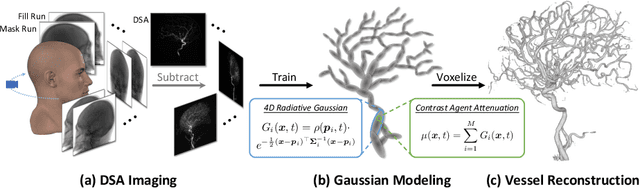

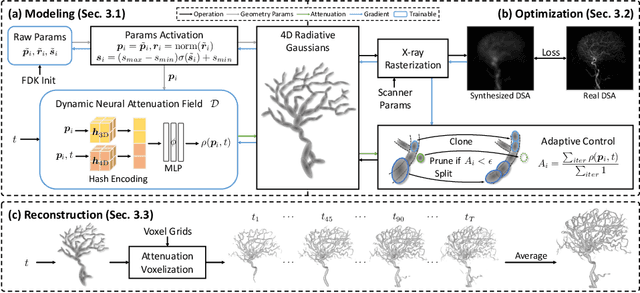

Reconstructing 3D vessel structures from sparse-view dynamic digital subtraction angiography (DSA) images enables accurate medical assessment while reducing radiation exposure. Existing methods often produce suboptimal results or require excessive computation time. In this work, we propose 4D radiative Gaussian splatting (4DRGS) to achieve high-quality reconstruction efficiently. In detail, we represent the vessels with 4D radiative Gaussian kernels. Each kernel has time-invariant geometry parameters, including position, rotation, and scale, to model static vessel structures. The time-dependent central attenuation of each kernel is predicted from a compact neural network to capture the temporal varying response of contrast agent flow. We splat these Gaussian kernels to synthesize DSA images via X-ray rasterization and optimize the model with real captured ones. The final 3D vessel volume is voxelized from the well-trained kernels. Moreover, we introduce accumulated attenuation pruning and bounded scaling activation to improve reconstruction quality. Extensive experiments on real-world patient data demonstrate that 4DRGS achieves impressive results in 5 minutes training, which is 32x faster than the state-of-the-art method. This underscores the potential of 4DRGS for real-world clinics.
MoSt-DSA: Modeling Motion and Structural Interactions for Direct Multi-Frame Interpolation in DSA Images
Jul 09, 2024



Artificial intelligence has become a crucial tool for medical image analysis. As an advanced cerebral angiography technique, Digital Subtraction Angiography (DSA) poses a challenge where the radiation dose to humans is proportional to the image count. By reducing images and using AI interpolation instead, the radiation can be cut significantly. However, DSA images present more complex motion and structural features than natural scenes, making interpolation more challenging. We propose MoSt-DSA, the first work that uses deep learning for DSA frame interpolation. Unlike natural scene Video Frame Interpolation (VFI) methods that extract unclear or coarse-grained features, we devise a general module that models motion and structural context interactions between frames in an efficient full convolution manner by adjusting optimal context range and transforming contexts into linear functions. Benefiting from this, MoSt-DSA is also the first method that directly achieves any number of interpolations at any time steps with just one forward pass during both training and testing. We conduct extensive comparisons with 7 representative VFI models for interpolating 1 to 3 frames, MoSt-DSA demonstrates robust results across 470 DSA image sequences (each typically 152 images), with average SSIM over 0.93, average PSNR over 38 (standard deviations of less than 0.030 and 3.6, respectively), comprehensively achieving state-of-the-art performance in accuracy, speed, visual effect, and memory usage. Our code is available at https://github.com/ZyoungXu/MoSt-DSA.
3D Vessel Reconstruction from Sparse-View Dynamic DSA Images via Vessel Probability Guided Attenuation Learning
May 17, 2024



Digital Subtraction Angiography (DSA) is one of the gold standards in vascular disease diagnosing. With the help of contrast agent, time-resolved 2D DSA images deliver comprehensive insights into blood flow information and can be utilized to reconstruct 3D vessel structures. Current commercial DSA systems typically demand hundreds of scanning views to perform reconstruction, resulting in substantial radiation exposure. However, sparse-view DSA reconstruction, aimed at reducing radiation dosage, is still underexplored in the research community. The dynamic blood flow and insufficient input of sparse-view DSA images present significant challenges to the 3D vessel reconstruction task. In this study, we propose to use a time-agnostic vessel probability field to solve this problem effectively. Our approach, termed as vessel probability guided attenuation learning, represents the DSA imaging as a complementary weighted combination of static and dynamic attenuation fields, with the weights derived from the vessel probability field. Functioning as a dynamic mask, vessel probability provides proper gradients for both static and dynamic fields adaptive to different scene types. This mechanism facilitates a self-supervised decomposition between static backgrounds and dynamic contrast agent flow, and significantly improves the reconstruction quality. Our model is trained by minimizing the disparity between synthesized projections and real captured DSA images. We further employ two training strategies to improve our reconstruction quality: (1) coarse-to-fine progressive training to achieve better geometry and (2) temporal perturbed rendering loss to enforce temporal consistency. Experimental results have demonstrated superior quality on both 3D vessel reconstruction and 2D view synthesis.