 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
DiffusionVL: Translating Any Autoregressive Models into Diffusion Vision Language Models
Dec 24, 2025In recent multimodal research, the diffusion paradigm has emerged as a promising alternative to the autoregressive paradigm (AR), owing to its unique decoding advantages. However, due to the capability limitations of the base diffusion language model, the performance of the diffusion vision language model (dVLM) still lags significantly behind that of mainstream models. This leads to a simple yet fundamental question: Is it possible to construct dVLMs based on existing powerful AR models? In response, we propose DiffusionVL, a dVLM family that could be translated from any powerful AR models. Through simple fine-tuning, we successfully adapt AR pre-trained models into the diffusion paradigm. This approach yields two key observations: (1) The paradigm shift from AR-based multimodal models to diffusion is remarkably effective. (2) Direct conversion of an AR language model to a dVLM is also feasible, achieving performance competitive with LLaVA-style visual-instruction-tuning. Further, we introduce a block-decoding design into dVLMs that supports arbitrary-length generation and KV cache reuse, achieving a significant inference speedup. We conduct a large number of experiments. Despite training with less than 5% of the data required by prior methods, DiffusionVL achieves a comprehensive performance improvement-a 34.4% gain on the MMMU-Pro (vision) bench and 37.5% gain on the MME (Cog.) bench-alongside a 2x inference speedup. The model and code are released at https://github.com/hustvl/DiffusionVL.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025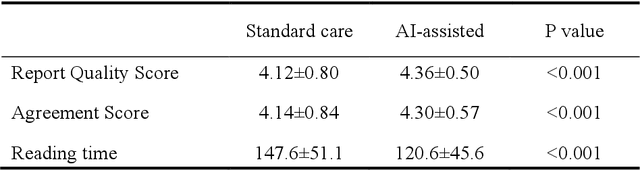
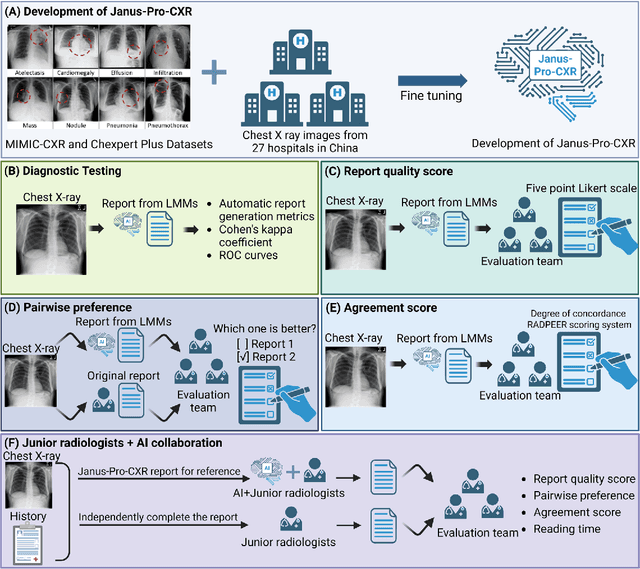
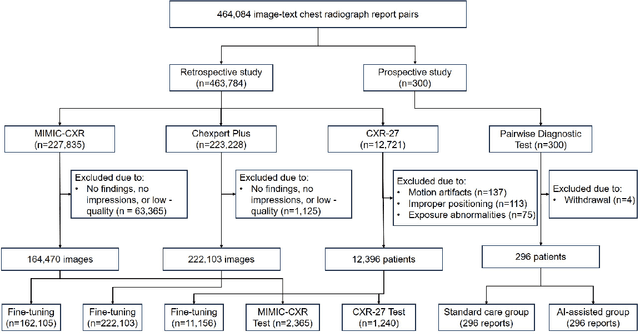
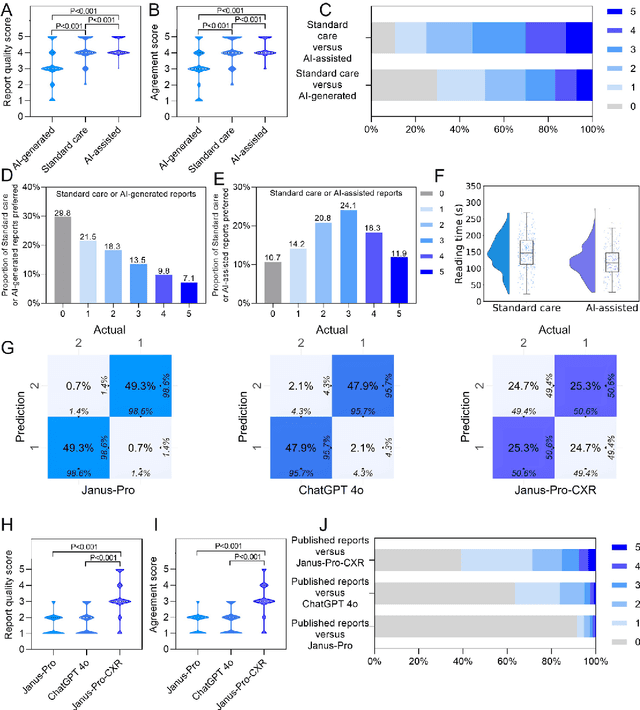
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
Towards Scalable Pre-training of Visual Tokenizers for Generation
Dec 15, 2025The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the ``pre-training scaling problem`` and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers
Oct 08, 2025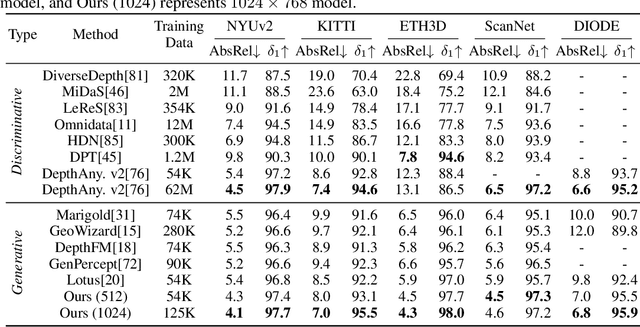

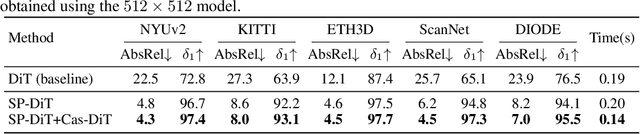
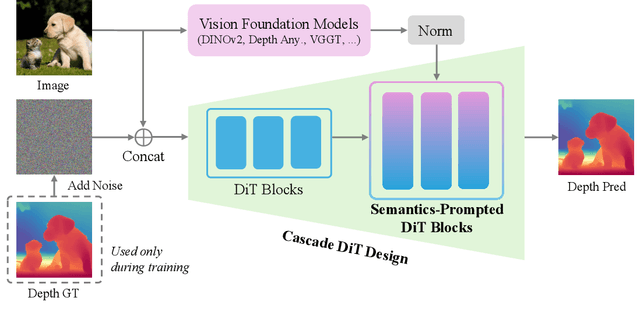
This paper presents Pixel-Perfect Depth, a monocular depth estimation model based on pixel-space diffusion generation that produces high-quality, flying-pixel-free point clouds from estimated depth maps. Current generative depth estimation models fine-tune Stable Diffusion and achieve impressive performance. However, they require a VAE to compress depth maps into latent space, which inevitably introduces \textit{flying pixels} at edges and details. Our model addresses this challenge by directly performing diffusion generation in the pixel space, avoiding VAE-induced artifacts. To overcome the high complexity associated with pixel-space generation, we introduce two novel designs: 1) Semantics-Prompted Diffusion Transformers (SP-DiT), which incorporate semantic representations from vision foundation models into DiT to prompt the diffusion process, thereby preserving global semantic consistency while enhancing fine-grained visual details; and 2) Cascade DiT Design that progressively increases the number of tokens to further enhance efficiency and accuracy. Our model achieves the best performance among all published generative models across five benchmarks, and significantly outperforms all other models in edge-aware point cloud evaluation.
Turbo-VAED: Fast and Stable Transfer of Video-VAEs to Mobile Devices
Aug 12, 2025There is a growing demand for deploying large generative AI models on mobile devices. For recent popular video generative models, however, the Variational AutoEncoder (VAE) represents one of the major computational bottlenecks. Both large parameter sizes and mismatched kernels cause out-of-memory errors or extremely slow inference on mobile devices. To address this, we propose a low-cost solution that efficiently transfers widely used video VAEs to mobile devices. (1) We analyze redundancy in existing VAE architectures and get empirical design insights. By integrating 3D depthwise separable convolutions into our model, we significantly reduce the number of parameters. (2) We observe that the upsampling techniques in mainstream video VAEs are poorly suited to mobile hardware and form the main bottleneck. In response, we propose a decoupled 3D pixel shuffle scheme that slashes end-to-end delay. Building upon these, we develop a universal mobile-oriented VAE decoder, Turbo-VAED. (3) We propose an efficient VAE decoder training method. Since only the decoder is used during deployment, we distill it to Turbo-VAED instead of retraining the full VAE, enabling fast mobile adaptation with minimal performance loss. To our knowledge, our method enables real-time 720p video VAE decoding on mobile devices for the first time. This approach is widely applicable to most video VAEs. When integrated into four representative models, with training cost as low as $95, it accelerates original VAEs by up to 84.5x at 720p resolution on GPUs, uses as low as 17.5% of original parameter count, and retains 96.9% of the original reconstruction quality. Compared to mobile-optimized VAEs, Turbo-VAED achieves a 2.9x speedup in FPS and better reconstruction quality on the iPhone 16 Pro. The code and models will soon be available at https://github.com/hustvl/Turbo-VAED.
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
Jan 06, 2025



Latent diffusion models with Transformer architectures excel at generating high-fidelity images. However, recent studies reveal an optimization dilemma in this two-stage design: while increasing the per-token feature dimension in visual tokenizers improves reconstruction quality, it requires substantially larger diffusion models and more training iterations to achieve comparable generation performance. Consequently, existing systems often settle for sub-optimal solutions, either producing visual artifacts due to information loss within tokenizers or failing to converge fully due to expensive computation costs. We argue that this dilemma stems from the inherent difficulty in learning unconstrained high-dimensional latent spaces. To address this, we propose aligning the latent space with pre-trained vision foundation models when training the visual tokenizers. Our proposed VA-VAE (Vision foundation model Aligned Variational AutoEncoder) significantly expands the reconstruction-generation frontier of latent diffusion models, enabling faster convergence of Diffusion Transformers (DiT) in high-dimensional latent spaces. To exploit the full potential of VA-VAE, we build an enhanced DiT baseline with improved training strategies and architecture designs, termed LightningDiT. The integrated system achieves state-of-the-art (SOTA) performance on ImageNet 256x256 generation with an FID score of 1.35 while demonstrating remarkable training efficiency by reaching an FID score of 2.11 in just 64 epochs--representing an over 21 times convergence speedup compared to the original DiT. Models and codes are available at: https://github.com/hustvl/LightningDiT.
FasterDiT: Towards Faster Diffusion Transformers Training without Architecture Modification
Oct 14, 2024Diffusion Transformers (DiT) have attracted significant attention in research. However, they suffer from a slow convergence rate. In this paper, we aim to accelerate DiT training without any architectural modification. We identify the following issues in the training process: firstly, certain training strategies do not consistently perform well across different data. Secondly, the effectiveness of supervision at specific timesteps is limited. In response, we propose the following contributions: (1) We introduce a new perspective for interpreting the failure of the strategies. Specifically, we slightly extend the definition of Signal-to-Noise Ratio (SNR) and suggest observing the Probability Density Function (PDF) of SNR to understand the essence of the data robustness of the strategy. (2) We conduct numerous experiments and report over one hundred experimental results to empirically summarize a unified accelerating strategy from the perspective of PDF. (3) We develop a new supervision method that further accelerates the training process of DiT. Based on them, we propose FasterDiT, an exceedingly simple and practicable design strategy. With few lines of code modifications, it achieves 2.30 FID on ImageNet 256 resolution at 1000k iterations, which is comparable to DiT (2.27 FID) but 7 times faster in training.
LKCell: Efficient Cell Nuclei Instance Segmentation with Large Convolution Kernels
Jul 25, 2024


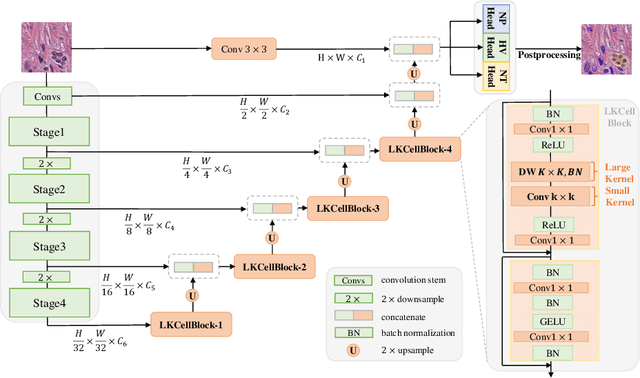
The segmentation of cell nuclei in tissue images stained with the blood dye hematoxylin and eosin (H$\&$E) is essential for various clinical applications and analyses. Due to the complex characteristics of cellular morphology, a large receptive field is considered crucial for generating high-quality segmentation. However, previous methods face challenges in achieving a balance between the receptive field and computational burden. To address this issue, we propose LKCell, a high-accuracy and efficient cell segmentation method. Its core insight lies in unleashing the potential of large convolution kernels to achieve computationally efficient large receptive fields. Specifically, (1) We transfer pre-trained large convolution kernel models to the medical domain for the first time, demonstrating their effectiveness in cell segmentation. (2) We analyze the redundancy of previous methods and design a new segmentation decoder based on large convolution kernels. It achieves higher performance while significantly reducing the number of parameters. We evaluate our method on the most challenging benchmark and achieve state-of-the-art results (0.5080 mPQ) in cell nuclei instance segmentation with only 21.6% FLOPs compared with the previous leading method. Our source code and models are available at https://github.com/hustvl/LKCell.