 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaMIL: Gated Memory Integration for Efficient and Discriminative Whole Slide Image Analysis
Dec 22, 2025



Whole Slide Images (WSIs) are typically analyzed using multiple instance learning (MIL) methods. However, the scale and heterogeneity of WSIs generate highly redundant and dispersed information, making it difficult to identify and integrate discriminative signals. Existing MIL methods either fail to discard uninformative cues effectively or have limited ability to consolidate relevant features from multiple patches, which restricts their performance on large and heterogeneous WSIs. To address this issue, we propose DeltaMIL, a novel MIL framework that explicitly selects semantically relevant regions and integrates the discriminative information from WSIs. Our method leverages the gated delta rule to efficiently filter and integrate information through a block combining forgetting and memory mechanisms. The delta mechanism dynamically updates the memory by removing old values and inserting new ones according to their correlation with the current patch. The gating mechanism further enables rapid forgetting of irrelevant signals. Additionally, DeltaMIL integrates a complementary local pattern mixing mechanism to retain fine-grained pathological locality. Our design enhances the extraction of meaningful cues and suppresses redundant or noisy information, which improves the model's robustness and discriminative power. Experiments demonstrate that DeltaMIL achieves state-of-the-art performance. Specifically, for survival prediction, DeltaMIL improves performance by 3.69\% using ResNet-50 features and 2.36\% using UNI features. For slide-level classification, it increases accuracy by 3.09\% with ResNet-50 features and 3.75\% with UNI features. These results demonstrate the strong and consistent performance of DeltaMIL across diverse WSI tasks.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025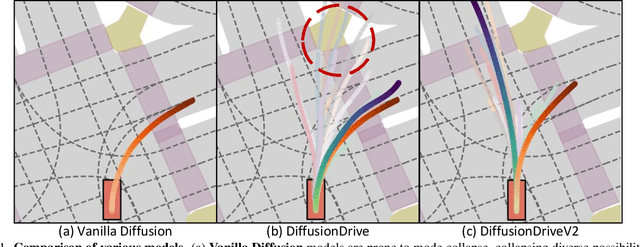
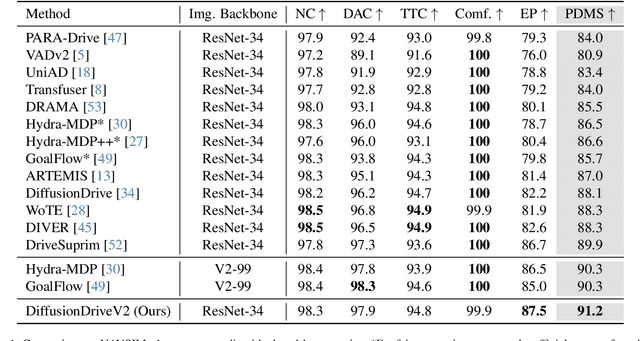
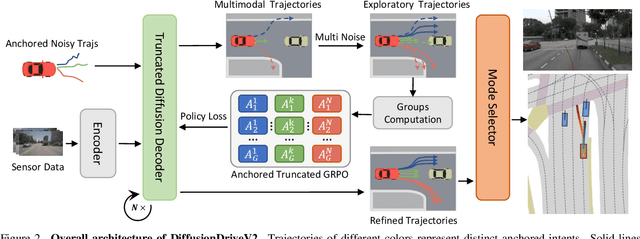
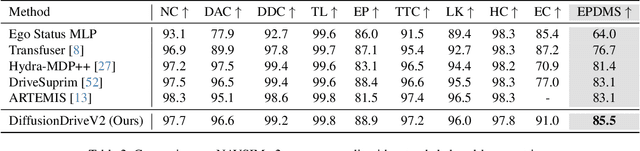
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
EVA-X: A Foundation Model for General Chest X-ray Analysis with Self-supervised Learning
May 08, 2024The diagnosis and treatment of chest diseases play a crucial role in maintaining human health. X-ray examination has become the most common clinical examination means due to its efficiency and cost-effectiveness. Artificial intelligence analysis methods for chest X-ray images are limited by insufficient annotation data and varying levels of annotation, resulting in weak generalization ability and difficulty in clinical dissemination. Here we present EVA-X, an innovative foundational model based on X-ray images with broad applicability to various chest disease detection tasks. EVA-X is the first X-ray image based self-supervised learning method capable of capturing both semantic and geometric information from unlabeled images for universal X-ray image representation. Through extensive experimentation, EVA-X has demonstrated exceptional performance in chest disease analysis and localization, becoming the first model capable of spanning over 20 different chest diseases and achieving leading results in over 11 different detection tasks in the medical field. Additionally, EVA-X significantly reduces the burden of data annotation in the medical AI field, showcasing strong potential in the domain of few-shot learning. The emergence of EVA-X will greatly propel the development and application of foundational medical models, bringing about revolutionary changes in future medical research and clinical practice. Our codes and models are available at: https://github.com/hustvl/EVA-X.
ViTGaze: Gaze Following with Interaction Features in Vision Transformers
Mar 19, 2024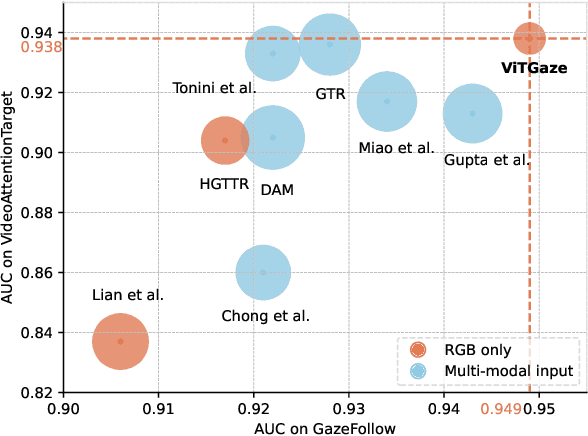

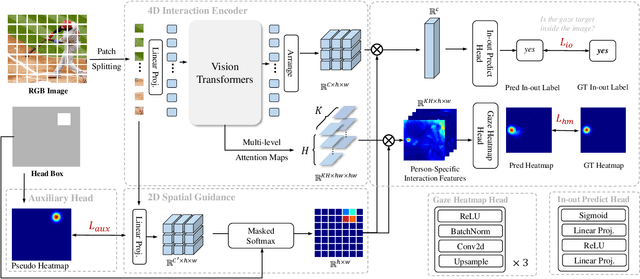

Gaze following aims to interpret human-scene interactions by predicting the person's focal point of gaze. Prevailing approaches often use multi-modality inputs, most of which adopt a two-stage framework. Hence their performance highly depends on the previous prediction accuracy. Others use a single-modality approach with complex decoders, increasing network computational load. Inspired by the remarkable success of pre-trained plain Vision Transformers (ViTs), we introduce a novel single-modality gaze following framework, ViTGaze. In contrast to previous methods, ViTGaze creates a brand new gaze following framework based mainly on powerful encoders (dec. param. less than 1%). Our principal insight lies in that the inter-token interactions within self-attention can be transferred to interactions between humans and scenes. Leveraging this presumption, we formulate a framework consisting of a 4D interaction encoder and a 2D spatial guidance module to extract human-scene interaction information from self-attention maps. Furthermore, our investigation reveals that ViT with self-supervised pre-training exhibits an enhanced ability to extract correlated information. A large number of experiments have been conducted to demonstrate the performance of the proposed method. Our method achieves state-of-the-art (SOTA) performance among all single-modality methods (3.4% improvement on AUC, 5.1% improvement on AP) and very comparable performance against multi-modality methods with 59% number of parameters less.