 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard negative examples are hard, but useful
Paper and Code
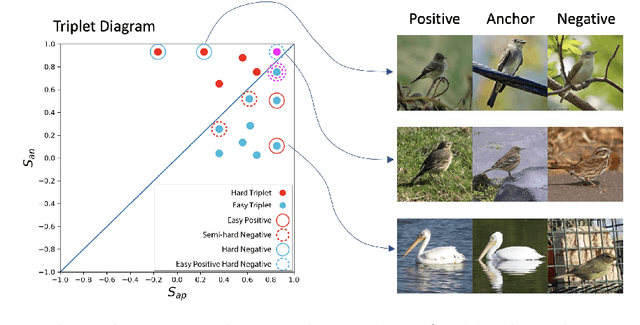
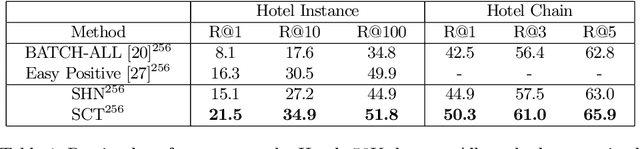
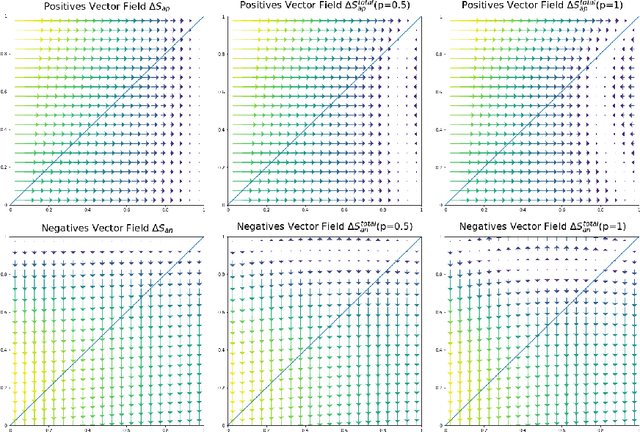
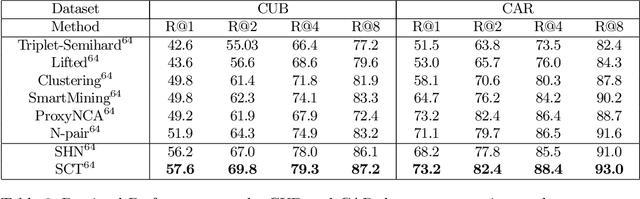
Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.