 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning User Simulators with Turing Rewards
Jun 17, 2026Learning to simulate human users in interactive settings could advance the training of agent assistants, evaluation of personalization systems, research in the social sciences, and more. Existing approaches generally do so by training a large language model (LLM) to match a single ground truth response, either by maximizing the log probability or by using a similarity reward. We instead propose {Turing-RL}: a Turing-Test-based reinforcement learning approach for training user simulator models. {Turing-RL} uses a discriminative Turing reward with an LLM judge to score how indistinguishable a generated response is from the real user's given the user's history, and the user simulator LLM learns to produce responses indistinguishable from what the user could have said with such rewards. Across two different domains--conversational chat and Reddit forum discussion--we find that {Turing-RL} consistently outperforms baseline methods on both LLM and human evaluation metrics. Our study suggests that optimizing for indistinguishability, rather than response matching, is effective for learning user simulators.
Implicit Representations of Grammaticality in Language Models
May 06, 2026Grammaticality and likelihood are distinct notions in human language. Pretrained language models (LMs), which are probabilistic models of language fitted to maximize corpus likelihood, generate grammatically well-formed text and discriminate well between grammatical and ungrammatical sentences in tightly controlled minimal pairs. However, their string probabilities do not sharply discriminate between grammatical and ungrammatical sentences overall. But do LMs implicitly acquire a grammaticality distinction distinct from string probability? We explore this question through studying internal representations of LMs, by training a linear probe on a dataset of grammatical and (synthetic) ungrammatical sentences obtained by applying perturbations to a naturalistic text corpus. We find that this simple grammaticality probe generalizes to human-curated grammaticality judgment benchmarks and outperforms LM probability-based grammaticality judgments. When applied to semantic plausibility benchmarks, in which both members of a minimal pair are grammatical and differ in only plausibility, the probe however performs worse than string probability. The English-trained probe also exhibits nontrivial cross-lingual generalization, outperforming string probabilities on grammaticality benchmarks in numerous other languages. Additionally, probe scores correlate only weakly with string probabilities. These results collectively suggest that LMs acquire to some extent an implicit grammaticality distinction within their hidden layers.
How Open Must Language Models be to Enable Reliable Scientific Inference?
Mar 27, 2026How does the extent to which a model is open or closed impact the scientific inferences that can be drawn from research that involves it? In this paper, we analyze how restrictions on information about model construction and deployment threaten reliable inference. We argue that current closed models are generally ill-suited for scientific purposes, with some notable exceptions, and discuss ways in which the issues they present to reliable inference can be resolved or mitigated. We recommend that when models are used in research, potential threats to inference should be systematically identified along with the steps taken to mitigate them, and that specific justifications for model selection should be provided.
N-gram-like Language Models Predict Reading Time Best
Mar 10, 2026Recent work has found that contemporary language models such as transformers can become so good at next-word prediction that the probabilities they calculate become worse for predicting reading time. In this paper, we propose that this can be explained by reading time being sensitive to simple n-gram statistics rather than the more complex statistics learned by state-of-the-art transformer language models. We demonstrate that the neural language models whose predictions are most correlated with n-gram probability are also those that calculate probabilities that are the most correlated with eye-tracking-based metrics of reading time on naturalistic text.
On the Same Wavelength? Evaluating Pragmatic Reasoning in Language Models across Broad Concepts
Sep 08, 2025

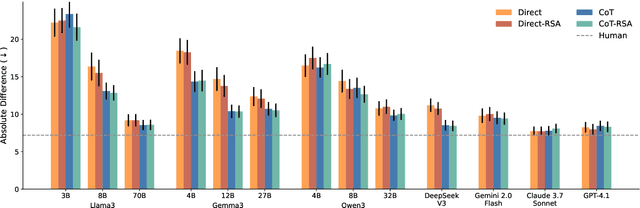
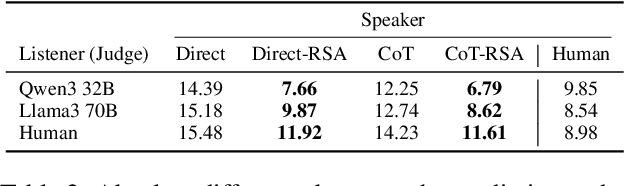
Language use is shaped by pragmatics -- i.e., reasoning about communicative goals and norms in context. As language models (LMs) are increasingly used as conversational agents, it becomes ever more important to understand their pragmatic reasoning abilities. We propose an evaluation framework derived from Wavelength, a popular communication game where a speaker and a listener communicate about a broad range of concepts in a granular manner. We study a range of LMs on both language comprehension and language production using direct and Chain-of-Thought (CoT) prompting, and further explore a Rational Speech Act (RSA) approach to incorporating Bayesian pragmatic reasoning into LM inference. We find that state-of-the-art LMs, but not smaller ones, achieve strong performance on language comprehension, obtaining similar-to-human accuracy and exhibiting high correlations with human judgments even without CoT prompting or RSA. On language production, CoT can outperform direct prompting, and using RSA provides significant improvements over both approaches. Our study helps identify the strengths and limitations in LMs' pragmatic reasoning abilities and demonstrates the potential for improving them with RSA, opening up future avenues for understanding conceptual representation, language understanding, and social reasoning in LMs and humans.
Multimodal Input Aids a Bayesian Model of Phonetic Learning
Jul 22, 2024
One of the many tasks facing the typically-developing child language learner is learning to discriminate between the distinctive sounds that make up words in their native language. Here we investigate whether multimodal information--specifically adult speech coupled with video frames of speakers' faces--benefits a computational model of phonetic learning. We introduce a method for creating high-quality synthetic videos of speakers' faces for an existing audio corpus. Our learning model, when both trained and tested on audiovisual inputs, achieves up to a 8.1% relative improvement on a phoneme discrimination battery compared to a model trained and tested on audio-only input. It also outperforms the audio model by up to 3.9% when both are tested on audio-only data, suggesting that visual information facilitates the acquisition of acoustic distinctions. Visual information is especially beneficial in noisy audio environments, where an audiovisual model closes 67% of the loss in discrimination performance of the audio model in noise relative to a non-noisy environment. These results demonstrate that visual information benefits an ideal learner and illustrate some of the ways that children might be able to leverage visual cues when learning to discriminate speech sounds.
Finding structure in logographic writing with library learning
May 11, 2024One hallmark of human language is its combinatoriality -- reusing a relatively small inventory of building blocks to create a far larger inventory of increasingly complex structures. In this paper, we explore the idea that combinatoriality in language reflects a human inductive bias toward representational efficiency in symbol systems. We develop a computational framework for discovering structure in a writing system. Built on top of state-of-the-art library learning and program synthesis techniques, our computational framework discovers known linguistic structures in the Chinese writing system and reveals how the system evolves towards simplification under pressures for representational efficiency. We demonstrate how a library learning approach, utilizing learned abstractions and compression, may help reveal the fundamental computational principles that underlie the creation of combinatorial structures in human cognition, and offer broader insights into the evolution of efficient communication systems.
Testing the Predictions of Surprisal Theory in 11 Languages
Jul 10, 2023A fundamental result in psycholinguistics is that less predictable words take a longer time to process. One theoretical explanation for this finding is Surprisal Theory (Hale, 2001; Levy, 2008), which quantifies a word's predictability as its surprisal, i.e. its negative log-probability given a context. While evidence supporting the predictions of Surprisal Theory have been replicated widely, most have focused on a very narrow slice of data: native English speakers reading English texts. Indeed, no comprehensive multilingual analysis exists. We address this gap in the current literature by investigating the relationship between surprisal and reading times in eleven different languages, distributed across five language families. Deriving estimates from language models trained on monolingual and multilingual corpora, we test three predictions associated with surprisal theory: (i) whether surprisal is predictive of reading times; (ii) whether expected surprisal, i.e. contextual entropy, is predictive of reading times; (iii) and whether the linking function between surprisal and reading times is linear. We find that all three predictions are borne out crosslinguistically. By focusing on a more diverse set of languages, we argue that these results offer the most robust link to-date between information theory and incremental language processing across languages.
Unsupervised Discontinuous Constituency Parsing with Mildly Context-Sensitive Grammars
Dec 18, 2022



We study grammar induction with mildly context-sensitive grammars for unsupervised discontinuous parsing. Using the probabilistic linear context-free rewriting system (LCFRS) formalism, our approach fixes the rule structure in advance and focuses on parameter learning with maximum likelihood. To reduce the computational complexity of both parsing and parameter estimation, we restrict the grammar formalism to LCFRS-2 (i.e., binary LCFRS with fan-out two) and further discard rules that require O(n^6) time to parse, reducing inference to O(n^5). We find that using a large number of nonterminals is beneficial and thus make use of tensor decomposition-based rank-space dynamic programming with an embedding-based parameterization of rule probabilities to scale up the number of nonterminals. Experiments on German and Dutch show that our approach is able to induce linguistically meaningful trees with continuous and discontinuous structures
Probing for Incremental Parse States in Autoregressive Language Models
Nov 17, 2022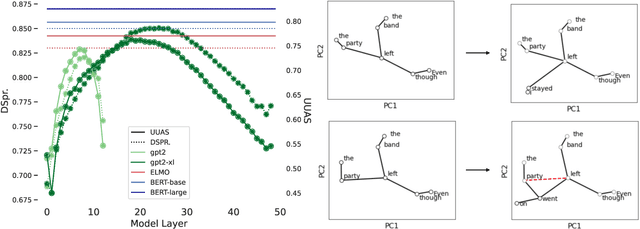
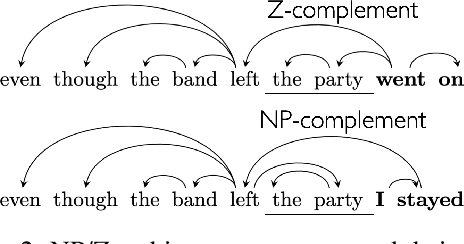
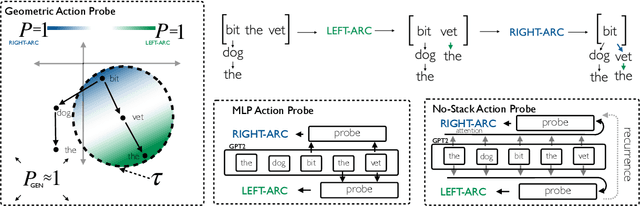
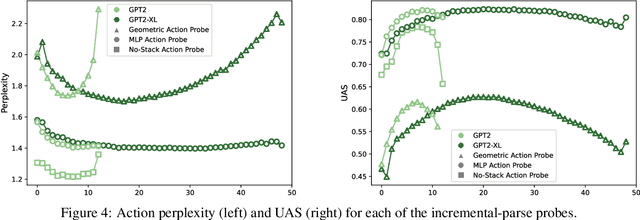
Next-word predictions from autoregressive neural language models show remarkable sensitivity to syntax. This work evaluates the extent to which this behavior arises as a result of a learned ability to maintain implicit representations of incremental syntactic structures. We extend work in syntactic probing to the incremental setting and present several probes for extracting incomplete syntactic structure (operationalized through parse states from a stack-based parser) from autoregressive language models. We find that our probes can be used to predict model preferences on ambiguous sentence prefixes and causally intervene on model representations and steer model behavior. This suggests implicit incremental syntactic inferences underlie next-word predictions in autoregressive neural language models.