 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Targeted Assessment of Incremental Processing in Neural LanguageModels and Humans
Jun 06, 2021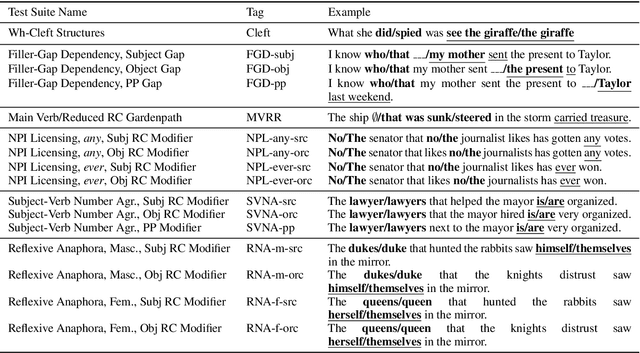
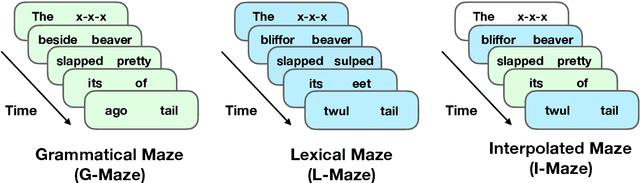
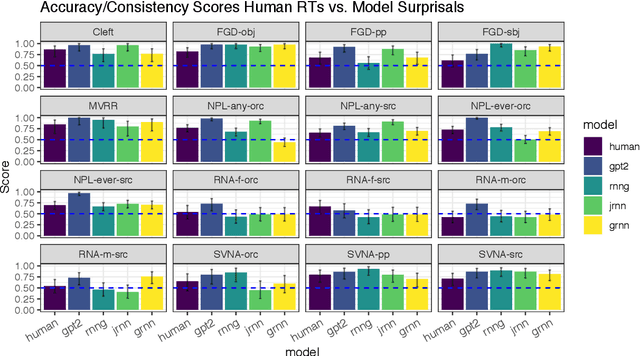
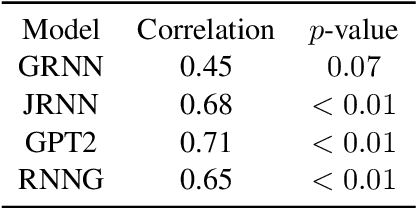
We present a targeted, scaled-up comparison of incremental processing in humans and neural language models by collecting by-word reaction time data for sixteen different syntactic test suites across a range of structural phenomena. Human reaction time data comes from a novel online experimental paradigm called the Interpolated Maze task. We compare human reaction times to by-word probabilities for four contemporary language models, with different architectures and trained on a range of data set sizes. We find that across many phenomena, both humans and language models show increased processing difficulty in ungrammatical sentence regions with human and model `accuracy' scores (a la Marvin and Linzen(2018)) about equal. However, although language model outputs match humans in direction, we show that models systematically under-predict the difference in magnitude of incremental processing difficulty between grammatical and ungrammatical sentences. Specifically, when models encounter syntactic violations they fail to accurately predict the longer reaction times observed in the human data. These results call into question whether contemporary language models are approaching human-like performance for sensitivity to syntactic violations.