 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammar-Based Grounded Lexicon Learning
Feb 17, 2022
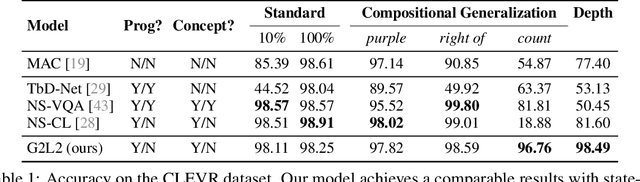
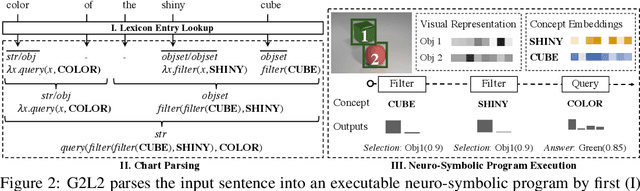
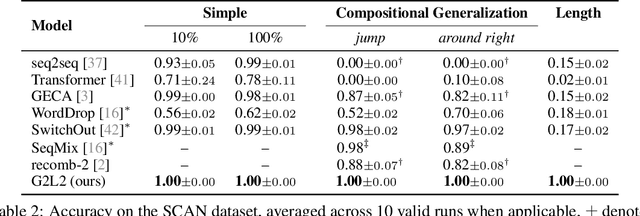
We present Grammar-Based Grounded Lexicon Learning (G2L2), a lexicalist approach toward learning a compositional and grounded meaning representation of language from grounded data, such as paired images and texts. At the core of G2L2 is a collection of lexicon entries, which map each word to a tuple of a syntactic type and a neuro-symbolic semantic program. For example, the word shiny has a syntactic type of adjective; its neuro-symbolic semantic program has the symbolic form {\lambda}x. filter(x, SHINY), where the concept SHINY is associated with a neural network embedding, which will be used to classify shiny objects. Given an input sentence, G2L2 first looks up the lexicon entries associated with each token. It then derives the meaning of the sentence as an executable neuro-symbolic program by composing lexical meanings based on syntax. The recovered meaning programs can be executed on grounded inputs. To facilitate learning in an exponentially-growing compositional space, we introduce a joint parsing and expected execution algorithm, which does local marginalization over derivations to reduce the training time. We evaluate G2L2 on two domains: visual reasoning and language-driven navigation. Results show that G2L2 can generalize from small amounts of data to novel compositions of words.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Substructure Distribution Projection for Zero-Shot Cross-Lingual Dependency Parsing
Oct 16, 2021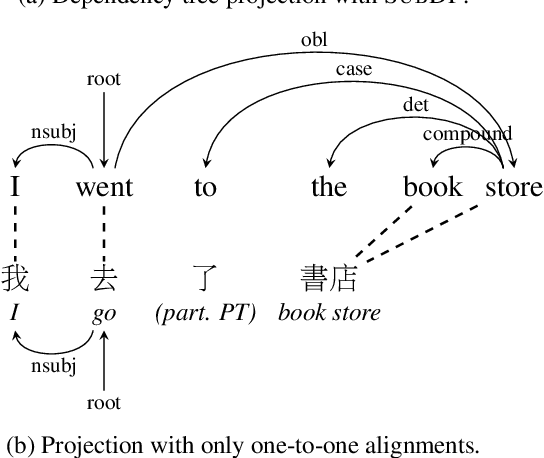
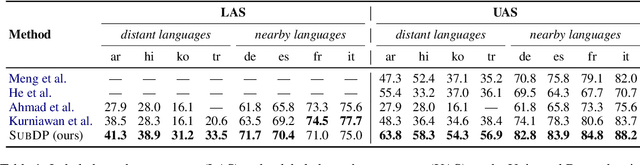
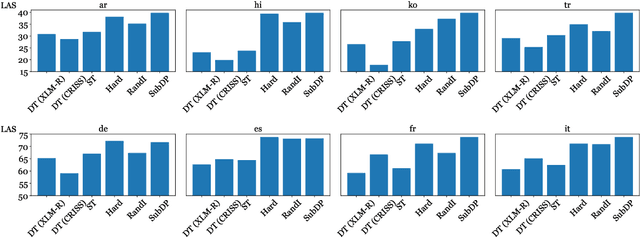
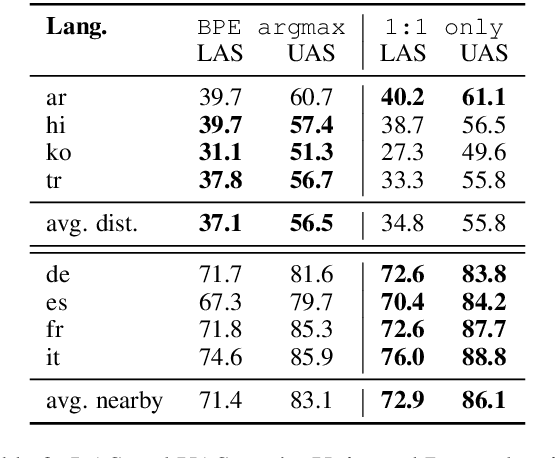
We present substructure distribution projection (SubDP), a technique that projects a distribution over structures in one domain to another, by projecting substructure distributions separately. Models for the target domains can be then trained, using the projected distributions as soft silver labels. We evaluate SubDP on zero-shot cross-lingual dependency parsing, taking dependency arcs as substructures: we project the predicted dependency arc distributions in the source language(s) to target language(s), and train a target language parser to fit the resulting distributions. When an English treebank is the only annotation that involves human effort, SubDP achieves better unlabeled attachment score than all prior work on the Universal Dependencies v2.2 (Nivre et al., 2020) test set across eight diverse target languages, as well as the best labeled attachment score on six out of eight languages. In addition, SubDP improves zero-shot cross-lingual dependency parsing with very few (e.g., 50) supervised bitext pairs, across a broader range of target languages.
Substructure Substitution: Structured Data Augmentation for NLP
Jan 02, 2021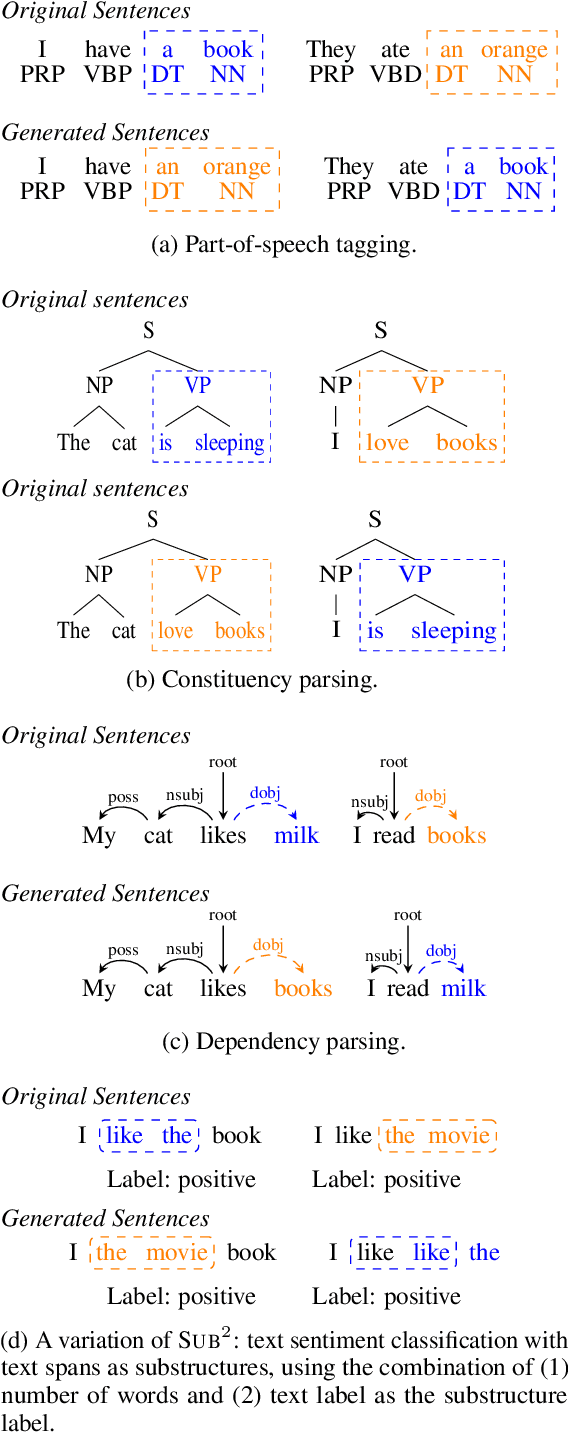
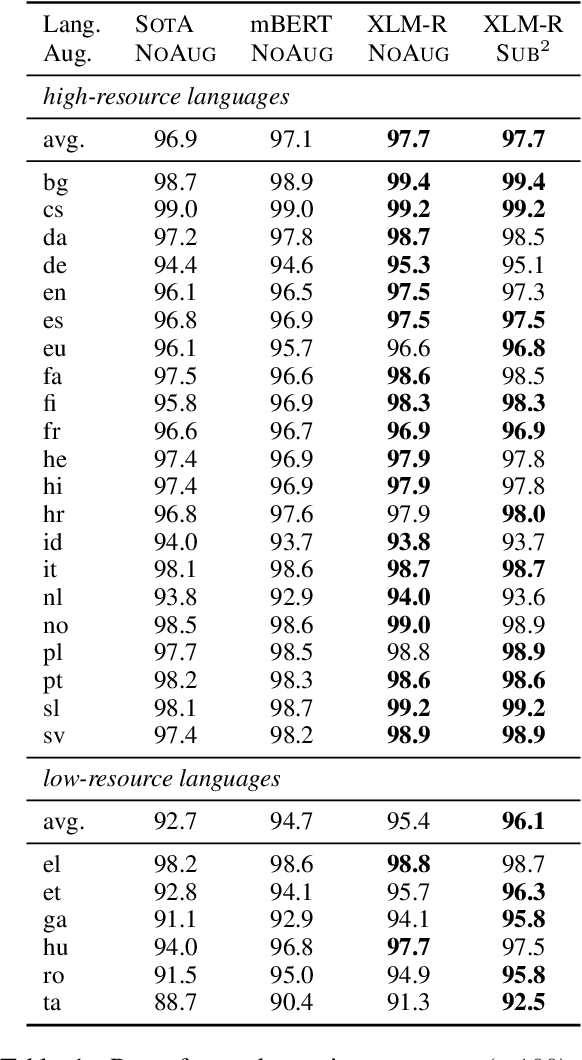
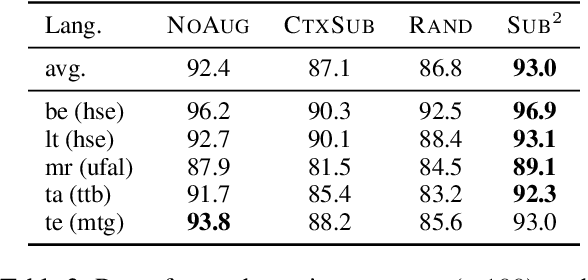
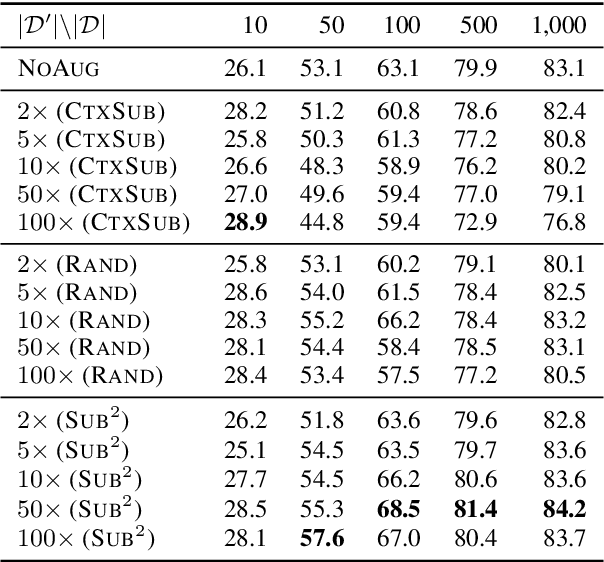
We study a family of data augmentation methods, substructure substitution (SUB2), for natural language processing (NLP) tasks. SUB2 generates new examples by substituting substructures (e.g., subtrees or subsequences) with ones with the same label, which can be applied to many structured NLP tasks such as part-of-speech tagging and parsing. For more general tasks (e.g., text classification) which do not have explicitly annotated substructures, we present variations of SUB2 based on constituency parse trees, introducing structure-aware data augmentation methods to general NLP tasks. For most cases, training with the augmented dataset by SUB2 achieves better performance than training with the original training set. Further experiments show that SUB2 has more consistent performance than other investigated augmentation methods, across different tasks and sizes of the seed dataset.
Bilingual Lexicon Induction via Unsupervised Bitext Construction and Word Alignment
Jan 01, 2021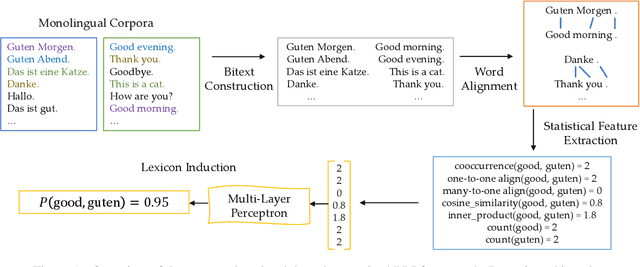
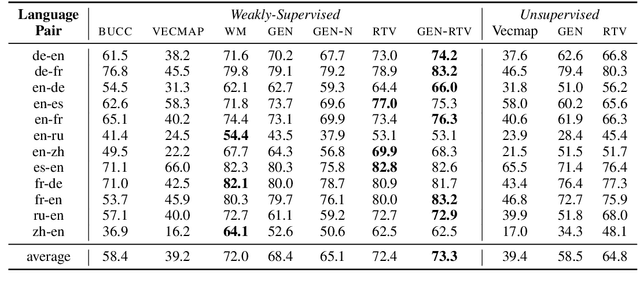
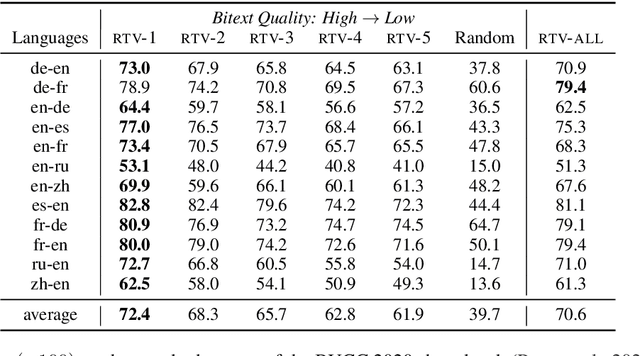
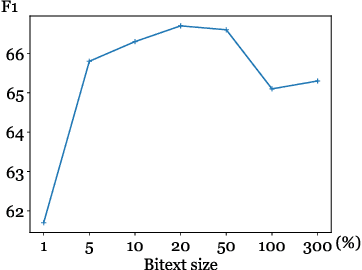
Bilingual lexicons map words in one language to their translations in another, and are typically induced by learning linear projections to align monolingual word embedding spaces. In this paper, we show it is possible to produce much higher quality lexicons with methods that combine (1) unsupervised bitext mining and (2) unsupervised word alignment. Directly applying a pipeline that uses recent algorithms for both subproblems significantly improves induced lexicon quality and further gains are possible by learning to filter the resulting lexical entries, with both unsupervised and semi-supervised schemes. Our final model outperforms the state of the art on the BUCC 2020 shared task by 14 $F_1$ points averaged over 12 language pairs, while also providing a more interpretable approach that allows for rich reasoning of word meaning in context.
Clustering Contextualized Representations of Text for Unsupervised Syntax Induction
Oct 24, 2020
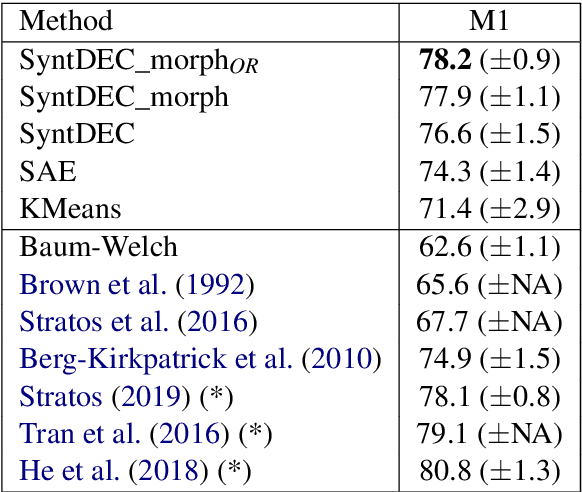
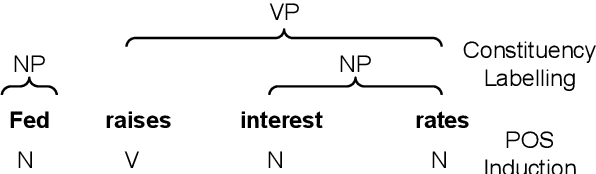
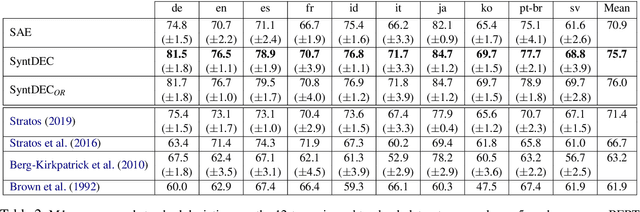
We explore clustering of contextualized text representations for two unsupervised syntax induction tasks: part of speech induction (POSI) and constituency labelling (CoLab). We propose a deep embedded clustering approach which jointly transforms these representations into a lower dimension cluster friendly space and clusters them. We further enhance these representations by augmenting them with task-specific representations. We also explore the effectiveness of multilingual representations for different tasks and languages. With this work, we establish the first strong baselines for unsupervised syntax induction using contextualized text representations. We report competitive performance on 45-tag POSI, state-of-the-art performance on 12-tag POSI across 10 languages, and competitive results on CoLab.
On the Role of Supervision in Unsupervised Constituency Parsing
Oct 07, 2020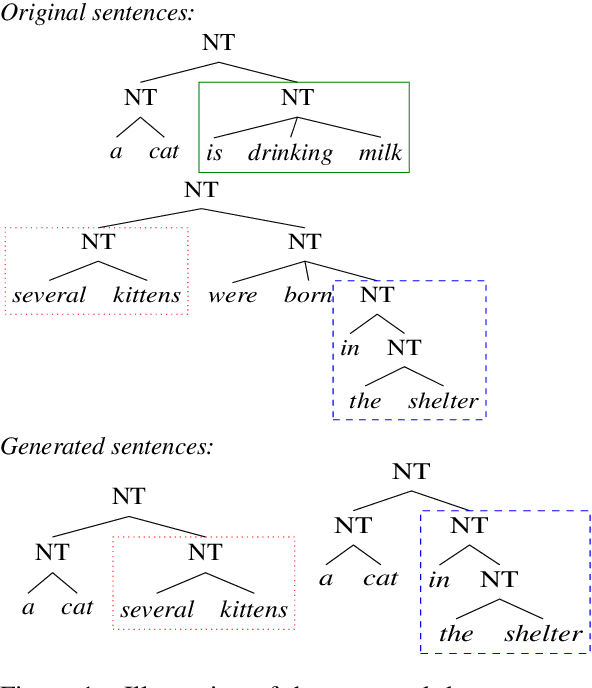
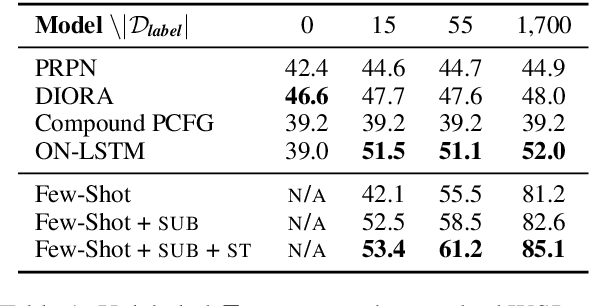
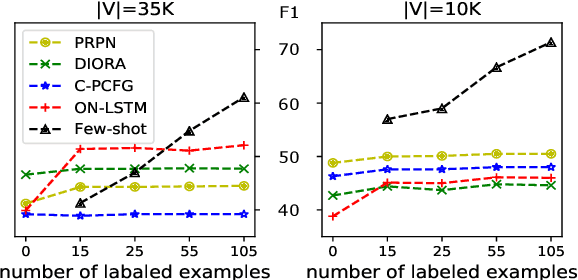
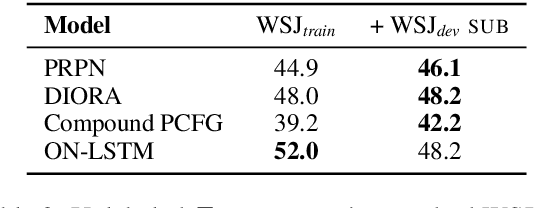
We analyze several recent unsupervised constituency parsing models, which are tuned with respect to the parsing $F_1$ score on the Wall Street Journal (WSJ) development set (1,700 sentences). We introduce strong baselines for them, by training an existing supervised parsing model (Kitaev and Klein, 2018) on the same labeled examples they access. When training on the 1,700 examples, or even when using only 50 examples for training and 5 for development, such a few-shot parsing approach can outperform all the unsupervised parsing methods by a significant margin. Few-shot parsing can be further improved by a simple data augmentation method and self-training. This suggests that, in order to arrive at fair conclusions, we should carefully consider the amount of labeled data used for model development. We propose two protocols for future work on unsupervised parsing: (i) use fully unsupervised criteria for hyperparameter tuning and model selection; (ii) use as few labeled examples as possible for model development, and compare to few-shot parsing trained on the same labeled examples.
A Cross-Task Analysis of Text Span Representations
Jun 06, 2020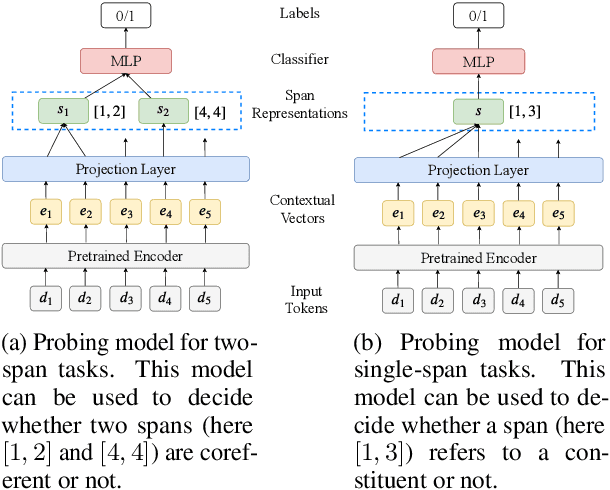
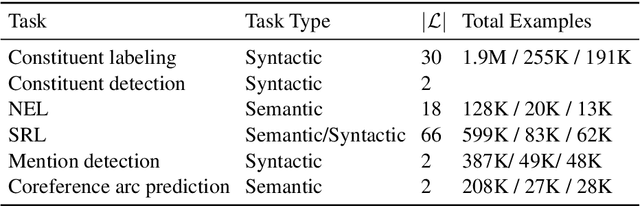
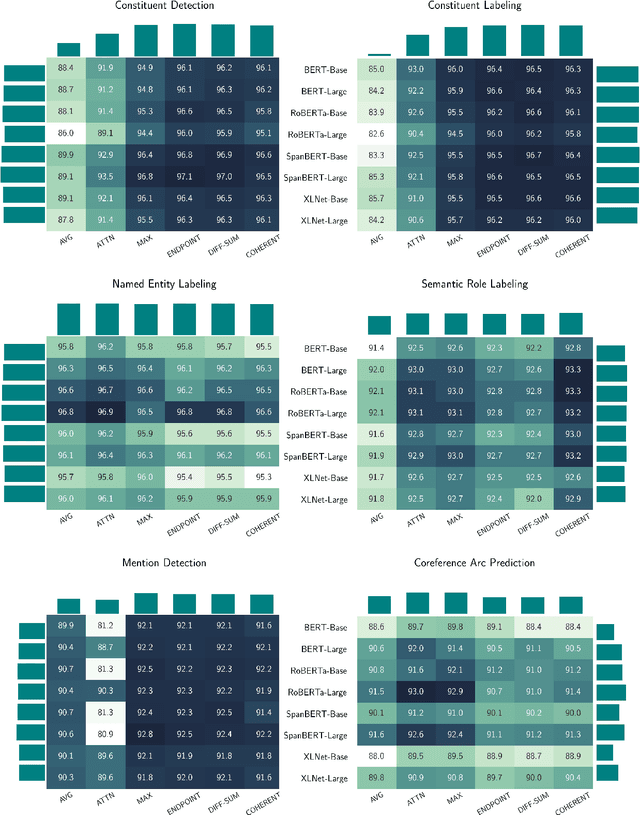
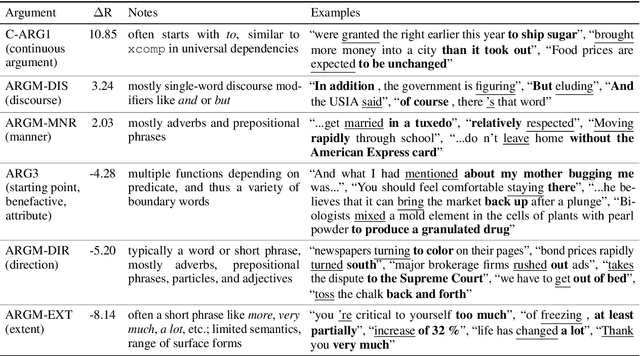
Many natural language processing (NLP) tasks involve reasoning with textual spans, including question answering, entity recognition, and coreference resolution. While extensive research has focused on functional architectures for representing words and sentences, there is less work on representing arbitrary spans of text within sentences. In this paper, we conduct a comprehensive empirical evaluation of six span representation methods using eight pretrained language representation models across six tasks, including two tasks that we introduce. We find that, although some simple span representations are fairly reliable across tasks, in general the optimal span representation varies by task, and can also vary within different facets of individual tasks. We also find that the choice of span representation has a bigger impact with a fixed pretrained encoder than with a fine-tuned encoder.
Visually Grounded Neural Syntax Acquisition
Jun 07, 2019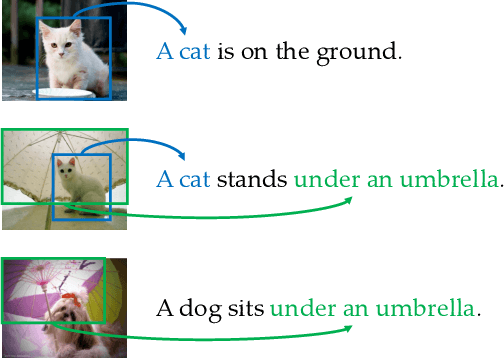
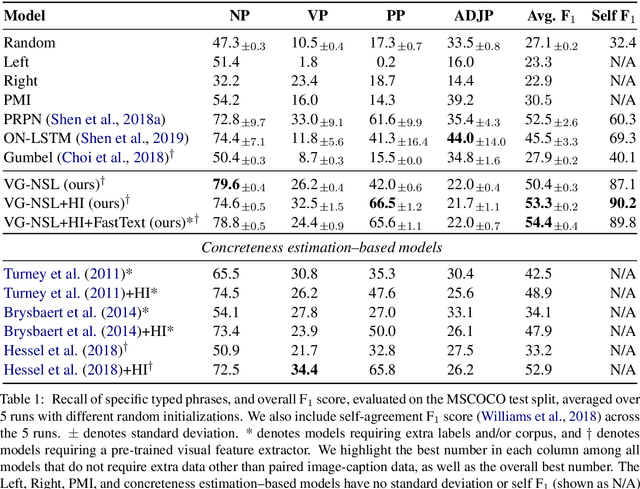
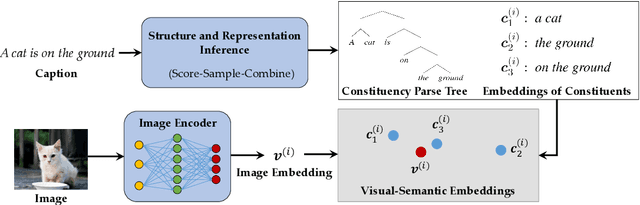
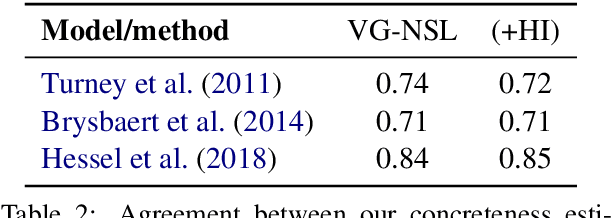
We present the Visually Grounded Neural Syntax Learner (VG-NSL), an approach for learning syntactic representations and structures without any explicit supervision. The model learns by looking at natural images and reading paired captions. VG-NSL generates constituency parse trees of texts, recursively composes representations for constituents, and matches them with images. We define concreteness of constituents by their matching scores with images, and use it to guide the parsing of text. Experiments on the MSCOCO data set show that VG-NSL outperforms various unsupervised parsing approaches that do not use visual grounding, in terms of F1 scores against gold parse trees. We find that VGNSL is much more stable with respect to the choice of random initialization and the amount of training data. We also find that the concreteness acquired by VG-NSL correlates well with a similar measure defined by linguists. Finally, we also apply VG-NSL to multiple languages in the Multi30K data set, showing that our model consistently outperforms prior unsupervised approaches.
On Tree-Based Neural Sentence Modeling
Aug 29, 2018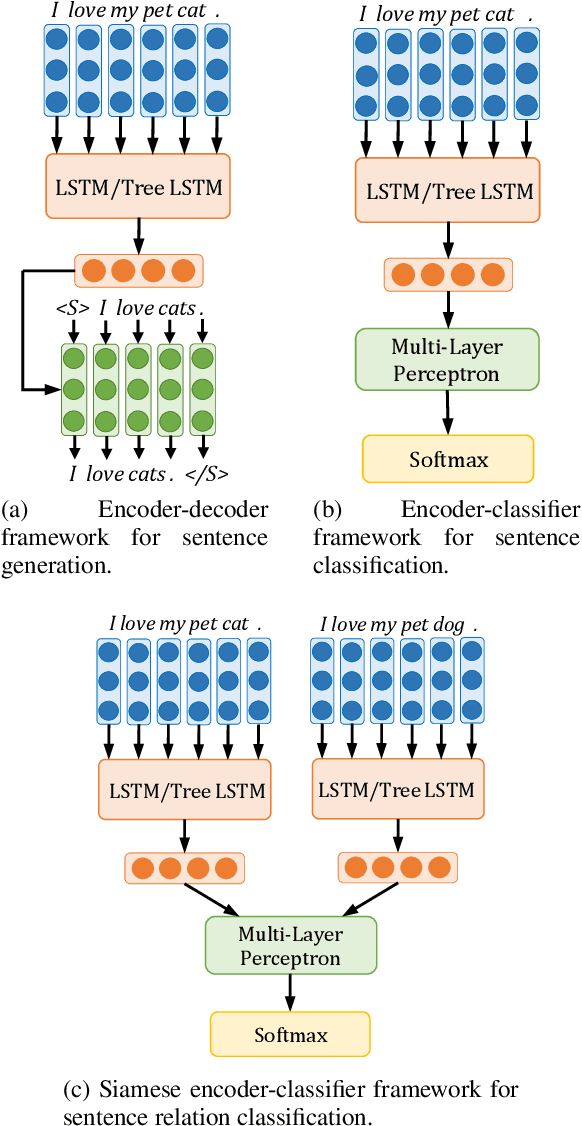
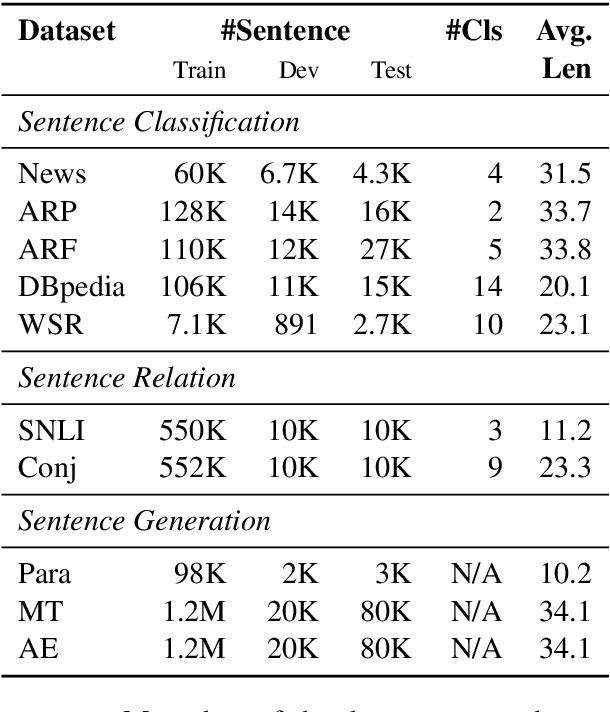

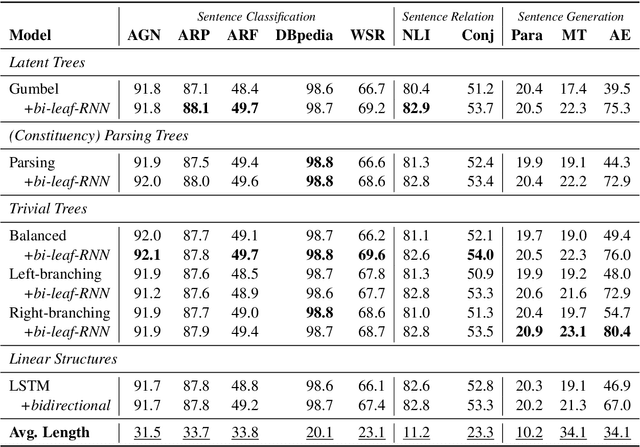
Neural networks with tree-based sentence encoders have shown better results on many downstream tasks. Most of existing tree-based encoders adopt syntactic parsing trees as the explicit structure prior. To study the effectiveness of different tree structures, we replace the parsing trees with trivial trees (i.e., binary balanced tree, left-branching tree and right-branching tree) in the encoders. Though trivial trees contain no syntactic information, those encoders get competitive or even better results on all of the ten downstream tasks we investigated. This surprising result indicates that explicit syntax guidance may not be the main contributor to the superior performances of tree-based neural sentence modeling. Further analysis show that tree modeling gives better results when crucial words are closer to the final representation. Additional experiments give more clues on how to design an effective tree-based encoder. Our code is open-source and available at https://github.com/ExplorerFreda/TreeEnc.