 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGISpeech 2.0: Transcribed multi-speaker financial audio for speaker-tagged transcription
Aug 07, 2025
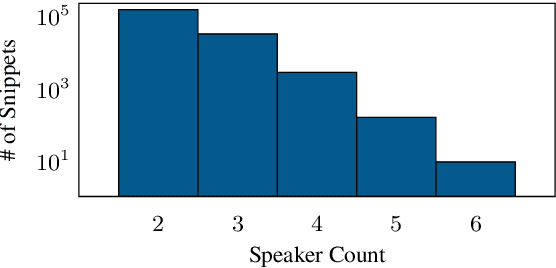
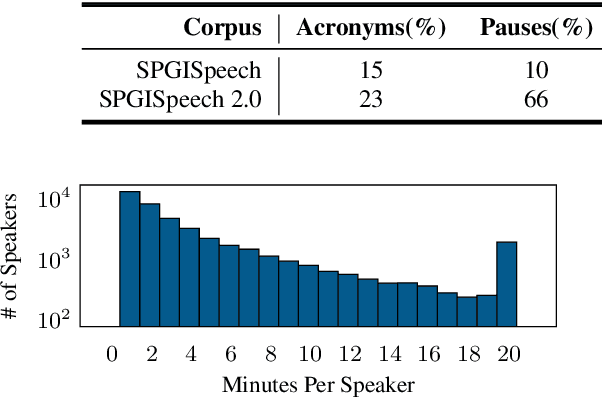
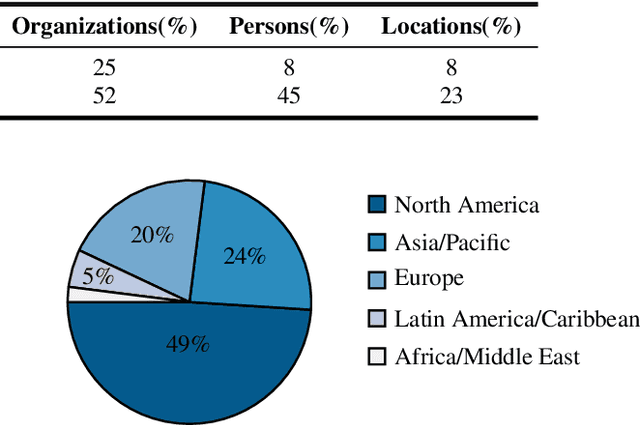
We introduce SPGISpeech 2.0, a dataset suitable for speaker-tagged transcription in the financial domain. SPGISpeech 2.0 improves the diversity of applicable modeling tasks while maintaining the core characteristic of the original SPGISpeech dataset: audio snippets and their corresponding fully formatted text transcriptions, usable for end-to-end automatic speech recognition (ASR). SPGISpeech 2.0 consists of 3,780 additional hours of professionally transcribed earnings calls. Furthermore, the dataset contains call and speaker information for each audio snippet facilitating multi-talker ASR. We validate the utility of SPGISpeech 2.0 through improvements in speaker-tagged ASR performance of popular speech recognition models after fine-tuning on SPGISpeech 2.0. Released free for non-commercial use, we expect SPGISpeech 2.0 to foster advancements in speech recognition technologies and inspire a wide range of research applications.
Multimodal Input Aids a Bayesian Model of Phonetic Learning
Jul 22, 2024
One of the many tasks facing the typically-developing child language learner is learning to discriminate between the distinctive sounds that make up words in their native language. Here we investigate whether multimodal information--specifically adult speech coupled with video frames of speakers' faces--benefits a computational model of phonetic learning. We introduce a method for creating high-quality synthetic videos of speakers' faces for an existing audio corpus. Our learning model, when both trained and tested on audiovisual inputs, achieves up to a 8.1% relative improvement on a phoneme discrimination battery compared to a model trained and tested on audio-only input. It also outperforms the audio model by up to 3.9% when both are tested on audio-only data, suggesting that visual information facilitates the acquisition of acoustic distinctions. Visual information is especially beneficial in noisy audio environments, where an audiovisual model closes 67% of the loss in discrimination performance of the audio model in noise relative to a non-noisy environment. These results demonstrate that visual information benefits an ideal learner and illustrate some of the ways that children might be able to leverage visual cues when learning to discriminate speech sounds.