 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Input Aids a Bayesian Model of Phonetic Learning
Jul 22, 2024
One of the many tasks facing the typically-developing child language learner is learning to discriminate between the distinctive sounds that make up words in their native language. Here we investigate whether multimodal information--specifically adult speech coupled with video frames of speakers' faces--benefits a computational model of phonetic learning. We introduce a method for creating high-quality synthetic videos of speakers' faces for an existing audio corpus. Our learning model, when both trained and tested on audiovisual inputs, achieves up to a 8.1% relative improvement on a phoneme discrimination battery compared to a model trained and tested on audio-only input. It also outperforms the audio model by up to 3.9% when both are tested on audio-only data, suggesting that visual information facilitates the acquisition of acoustic distinctions. Visual information is especially beneficial in noisy audio environments, where an audiovisual model closes 67% of the loss in discrimination performance of the audio model in noise relative to a non-noisy environment. These results demonstrate that visual information benefits an ideal learner and illustrate some of the ways that children might be able to leverage visual cues when learning to discriminate speech sounds.
How Adults Understand What Young Children Say
Jun 15, 2022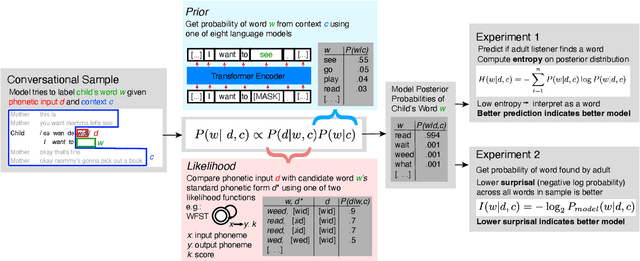
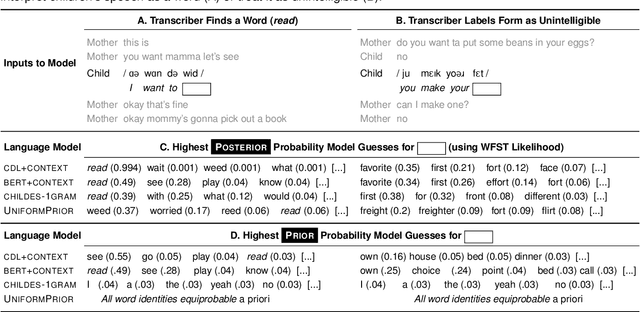
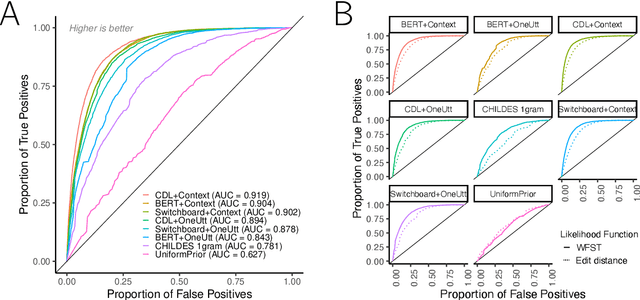
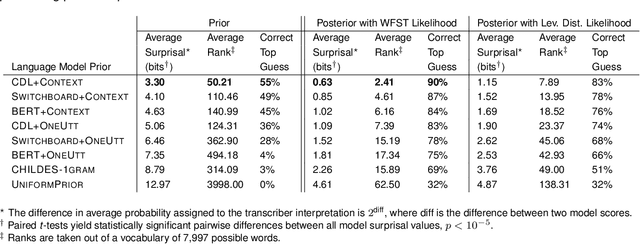
Children's early speech often bears little resemblance to adult speech in form or content, and yet caregivers often find meaning in young children's utterances. Precisely how caregivers are able to do this remains poorly understood. We propose that successful early communication (an essential building block of language development) relies not just on children's growing linguistic knowledge, but also on adults' sophisticated inferences. These inferences, we further propose, are optimized for fine-grained details of how children speak. We evaluate these ideas using a set of candidate computational models of spoken word recognition based on deep learning and Bayesian inference, which instantiate competing hypotheses regarding the information sources used by adults to understand children. We find that the best-performing models (evaluated on datasets of adult interpretations of child speech) are those that have strong prior expectations about what children are likely to want to communicate, rather than the actual phonetic contents of what children say. We further find that adults' behavior is best characterized as well-tuned to specific children: the more closely a word recognition model is tuned to the particulars of an individual child's actual linguistic behavior, the better it predicts adults' inferences about what the child has said. These results offer a comprehensive investigation into the role of caregivers as child-directed listeners, with broader consequences for theories of language acquisition.
Child-directed Listening: How Caregiver Inference Enables Children's Early Verbal Communication
Feb 09, 2021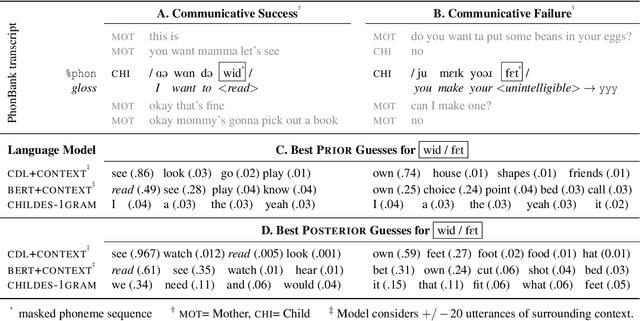
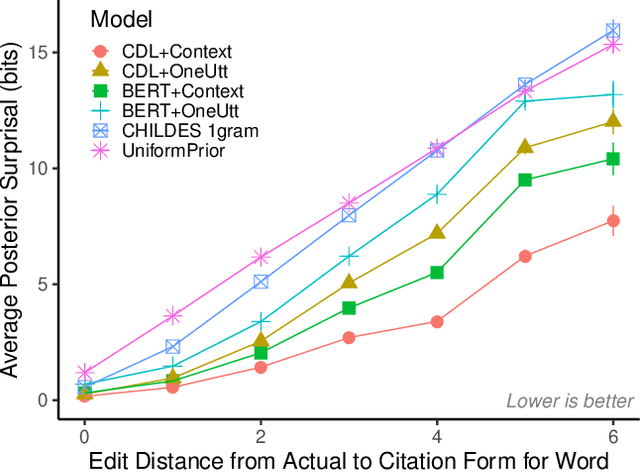
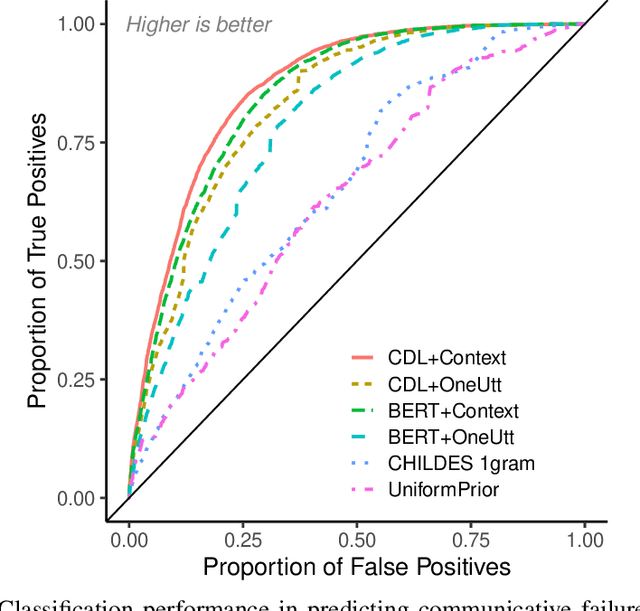
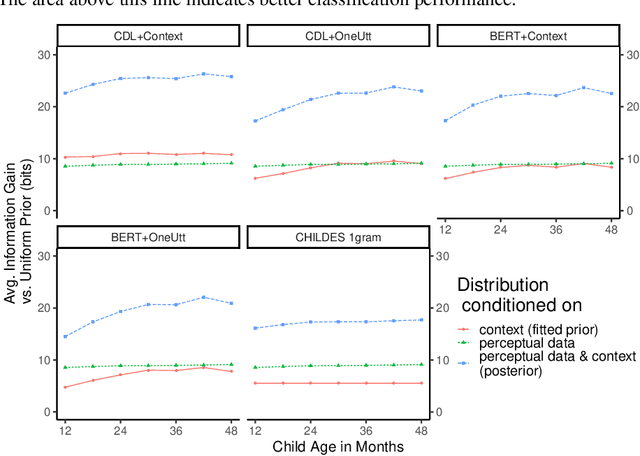
How do adults understand children's speech? Children's productions over the course of language development often bear little resemblance to typical adult pronunciations, yet caregivers nonetheless reliably recover meaning from them. Here, we employ a suite of Bayesian models of spoken word recognition to understand how adults overcome the noisiness of child language, showing that communicative success between children and adults relies heavily on adult inferential processes. By evaluating competing models on phonetically-annotated corpora, we show that adults' recovered meanings are best predicted by prior expectations fitted specifically to the child language environment, rather than to typical adult-adult language. After quantifying the contribution of this "child-directed listening" over developmental time, we discuss the consequences for theories of language acquisition, as well as the implications for commonly-used methods for assessing children's linguistic proficiency.
Evaluating Models of Robust Word Recognition with Serial Reproduction
Jan 24, 2021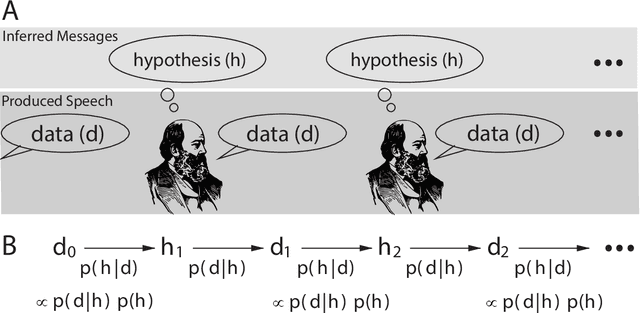
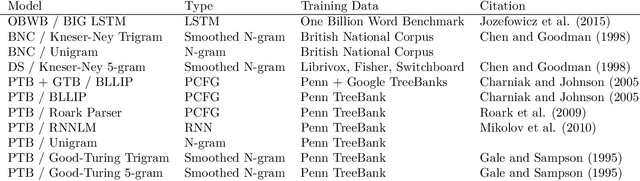

Spoken communication occurs in a "noisy channel" characterized by high levels of environmental noise, variability within and between speakers, and lexical and syntactic ambiguity. Given these properties of the received linguistic input, robust spoken word recognition -- and language processing more generally -- relies heavily on listeners' prior knowledge to evaluate whether candidate interpretations of that input are more or less likely. Here we compare several broad-coverage probabilistic generative language models in their ability to capture human linguistic expectations. Serial reproduction, an experimental paradigm where spoken utterances are reproduced by successive participants similar to the children's game of "Telephone," is used to elicit a sample that reflects the linguistic expectations of English-speaking adults. When we evaluate a suite of probabilistic generative language models against the yielded chains of utterances, we find that those models that make use of abstract representations of preceding linguistic context (i.e., phrase structure) best predict the changes made by people in the course of serial reproduction. A logistic regression model predicting which words in an utterance are most likely to be lost or changed in the course of spoken transmission corroborates this result. We interpret these findings in light of research highlighting the interaction of memory-based constraints and representations in language processing.
Word forms - not just their lengths- are optimized for efficient communication
May 31, 2017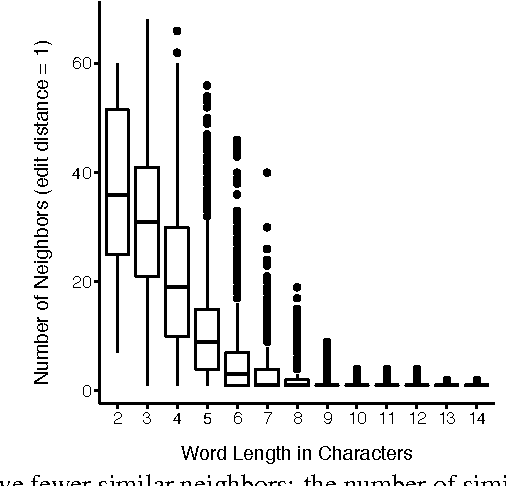
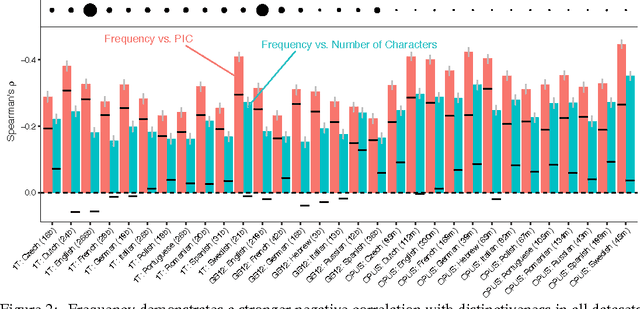
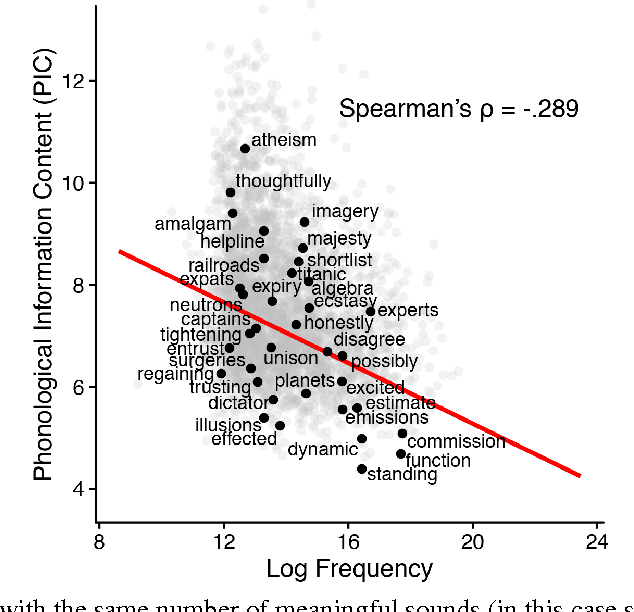
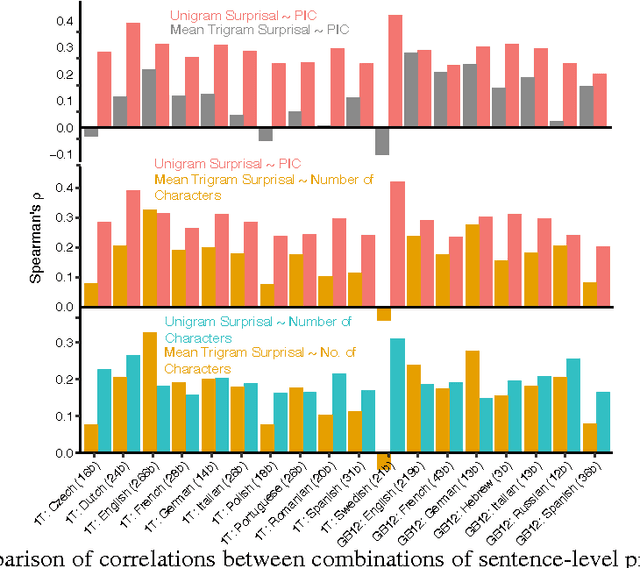
The inverse relationship between the length of a word and the frequency of its use, first identified by G.K. Zipf in 1935, is a classic empirical law that holds across a wide range of human languages. We demonstrate that length is one aspect of a much more general property of words: how distinctive they are with respect to other words in a language. Distinctiveness plays a critical role in recognizing words in fluent speech, in that it reflects the strength of potential competitors when selecting the best candidate for an ambiguous signal. Phonological information content, a measure of a word's string probability under a statistical model of a language's sound or character sequences, concisely captures distinctiveness. Examining large-scale corpora from 13 languages, we find that distinctiveness significantly outperforms word length as a predictor of frequency. This finding provides evidence that listeners' processing constraints shape fine-grained aspects of word forms across languages.