 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Models of Robust Word Recognition with Serial Reproduction
Paper and Code
Jan 24, 2021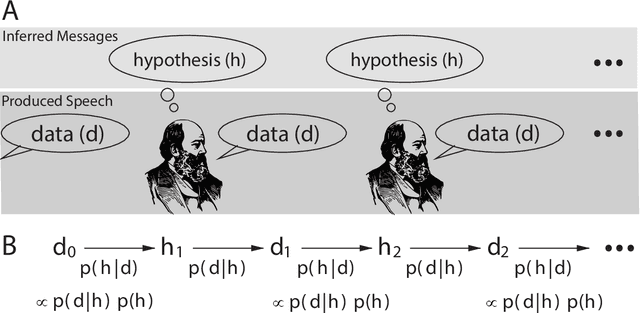
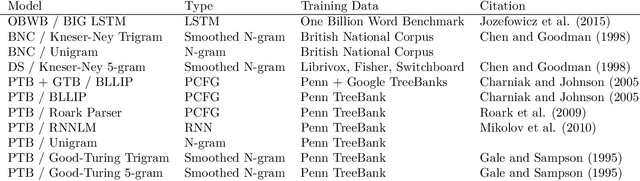

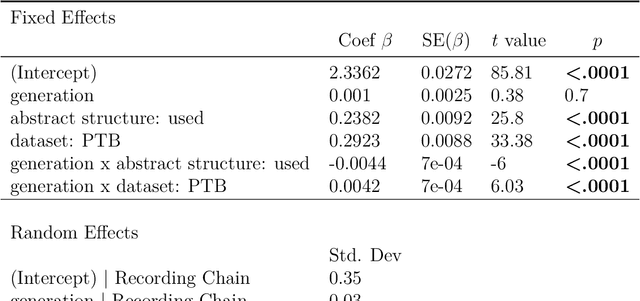
Spoken communication occurs in a "noisy channel" characterized by high levels of environmental noise, variability within and between speakers, and lexical and syntactic ambiguity. Given these properties of the received linguistic input, robust spoken word recognition -- and language processing more generally -- relies heavily on listeners' prior knowledge to evaluate whether candidate interpretations of that input are more or less likely. Here we compare several broad-coverage probabilistic generative language models in their ability to capture human linguistic expectations. Serial reproduction, an experimental paradigm where spoken utterances are reproduced by successive participants similar to the children's game of "Telephone," is used to elicit a sample that reflects the linguistic expectations of English-speaking adults. When we evaluate a suite of probabilistic generative language models against the yielded chains of utterances, we find that those models that make use of abstract representations of preceding linguistic context (i.e., phrase structure) best predict the changes made by people in the course of serial reproduction. A logistic regression model predicting which words in an utterance are most likely to be lost or changed in the course of spoken transmission corroborates this result. We interpret these findings in light of research highlighting the interaction of memory-based constraints and representations in language processing.