 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling in the Mechanisms: How do LMs Learn Filler-Gap Dependencies under Developmental Constraints?
Apr 15, 2026For humans, filler-gap dependencies require a shared representation across different syntactic constructions. Although causal analyses suggest this may also be true for LLMs (Boguraev et al., 2025), it is still unclear if such a representation also exists for language models trained on developmentally feasible quantities of data. We applied Distributed Alignment Search (DAS, Geiger et al. (2024)) to LMs trained on varying amounts of data from the BabyLM challenge (Warstadt et al., 2023), to evaluate whether representations of filler-gap dependencies transfer between wh-questions and topicalization, which greatly vary in terms of their input frequency. Our results suggest shared, yet item-sensitive mechanisms may develop with limited training data. More importantly, LMs still require far more data than humans to learn comparable generalizations, highlighting the need for language-specific biases in models of language acquisition.
Across the Levels of Analysis: Explaining Predictive Processing in Humans Requires More Than Machine-Estimated Probabilities
Apr 10, 2026Under the lens of Marr's levels of analysis, we critique and extend two claims about language models (LMs) and language processing: first, that predicting upcoming linguistic information based on context is central to language processing, and second, that many advances in psycholinguistics would be impossible without large language models (LLMs). We further outline future directions that combine the strengths of LLMs with psycholinguistic models.
Clozing the Gap: Exploring Why Language Model Surprisal Outperforms Cloze Surprisal
Jan 14, 2026How predictable a word is can be quantified in two ways: using human responses to the cloze task or using probabilities from language models (LMs).When used as predictors of processing effort, LM probabilities outperform probabilities derived from cloze data. However, it is important to establish that LM probabilities do so for the right reasons, since different predictors can lead to different scientific conclusions about the role of prediction in language comprehension. We present evidence for three hypotheses about the advantage of LM probabilities: not suffering from low resolution, distinguishing semantically similar words, and accurately assigning probabilities to low-frequency words. These results call for efforts to improve the resolution of cloze studies, coupled with experiments on whether human-like prediction is also as sensitive to the fine-grained distinctions made by LM probabilities.
Generalizations across filler-gap dependencies in neural language models
Oct 23, 2024



Humans develop their grammars by making structural generalizations from finite input. We ask how filler-gap dependencies, which share a structural generalization despite diverse surface forms, might arise from the input. We explicitly control the input to a neural language model (NLM) to uncover whether the model posits a shared representation for filler-gap dependencies. We show that while NLMs do have success differentiating grammatical from ungrammatical filler-gap dependencies, they rely on superficial properties of the input, rather than on a shared generalization. Our work highlights the need for specific linguistic inductive biases to model language acquisition.
A Psycholinguistic Evaluation of Language Models' Sensitivity to Argument Roles
Oct 21, 2024
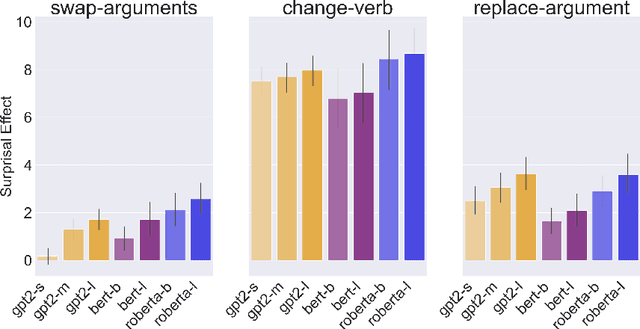
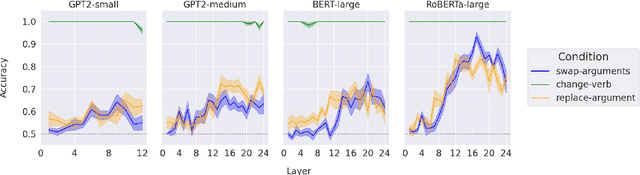

We present a systematic evaluation of large language models' sensitivity to argument roles, i.e., who did what to whom, by replicating psycholinguistic studies on human argument role processing. In three experiments, we find that language models are able to distinguish verbs that appear in plausible and implausible contexts, where plausibility is determined through the relation between the verb and its preceding arguments. However, none of the models capture the same selective patterns that human comprehenders exhibit during real-time verb prediction. This indicates that language models' capacity to detect verb plausibility does not arise from the same mechanism that underlies human real-time sentence processing.
Words, Subwords, and Morphemes: What Really Matters in the Surprisal-Reading Time Relationship?
Oct 26, 2023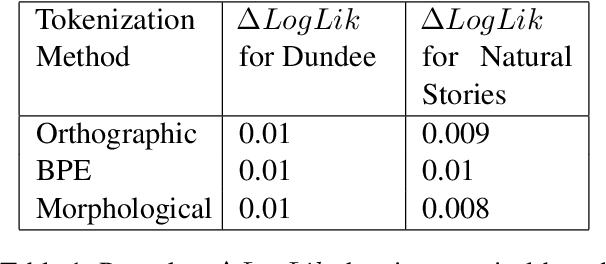
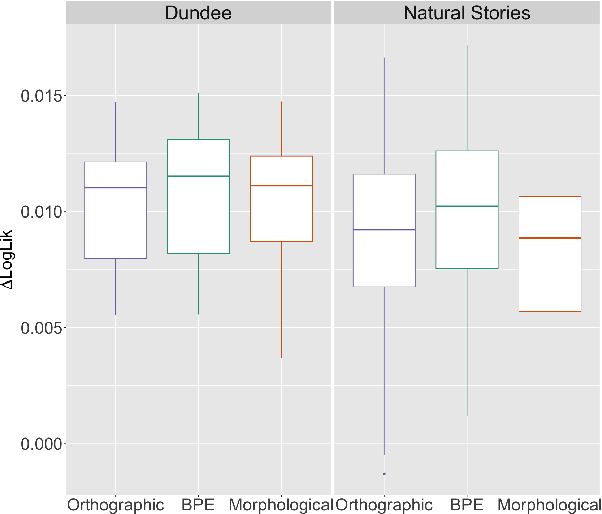
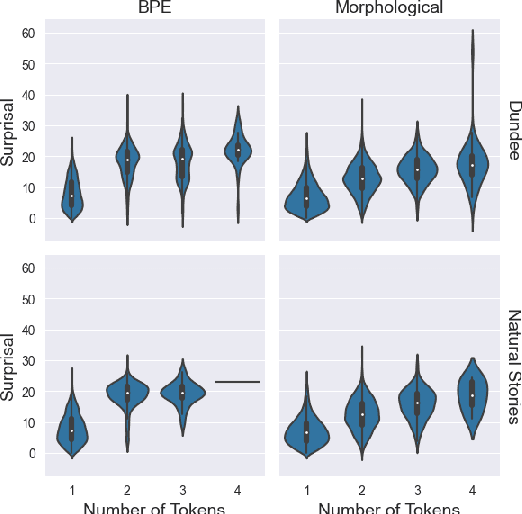
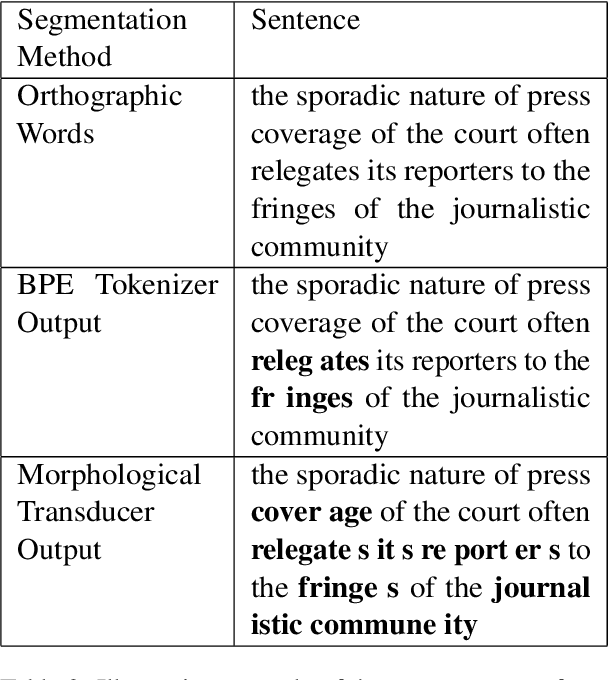
An important assumption that comes with using LLMs on psycholinguistic data has gone unverified. LLM-based predictions are based on subword tokenization, not decomposition of words into morphemes. Does that matter? We carefully test this by comparing surprisal estimates using orthographic, morphological, and BPE tokenization against reading time data. Our results replicate previous findings and provide evidence that in the aggregate, predictions using BPE tokenization do not suffer relative to morphological and orthographic segmentation. However, a finer-grained analysis points to potential issues with relying on BPE-based tokenization, as well as providing promising results involving morphologically-aware surprisal estimates and suggesting a new method for evaluating morphological prediction.
Evaluating Models of Robust Word Recognition with Serial Reproduction
Jan 24, 2021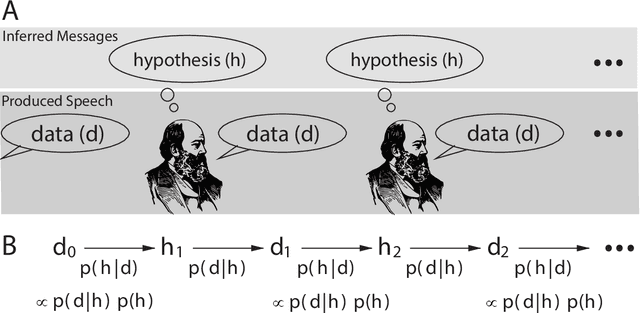

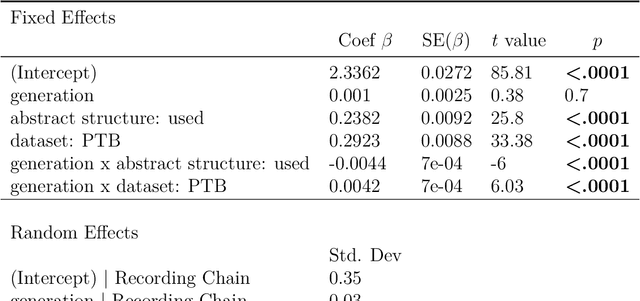
Spoken communication occurs in a "noisy channel" characterized by high levels of environmental noise, variability within and between speakers, and lexical and syntactic ambiguity. Given these properties of the received linguistic input, robust spoken word recognition -- and language processing more generally -- relies heavily on listeners' prior knowledge to evaluate whether candidate interpretations of that input are more or less likely. Here we compare several broad-coverage probabilistic generative language models in their ability to capture human linguistic expectations. Serial reproduction, an experimental paradigm where spoken utterances are reproduced by successive participants similar to the children's game of "Telephone," is used to elicit a sample that reflects the linguistic expectations of English-speaking adults. When we evaluate a suite of probabilistic generative language models against the yielded chains of utterances, we find that those models that make use of abstract representations of preceding linguistic context (i.e., phrase structure) best predict the changes made by people in the course of serial reproduction. A logistic regression model predicting which words in an utterance are most likely to be lost or changed in the course of spoken transmission corroborates this result. We interpret these findings in light of research highlighting the interaction of memory-based constraints and representations in language processing.
Contextualized Word Embeddings Encode Aspects of Human-Like Word Sense Knowledge
Oct 25, 2020
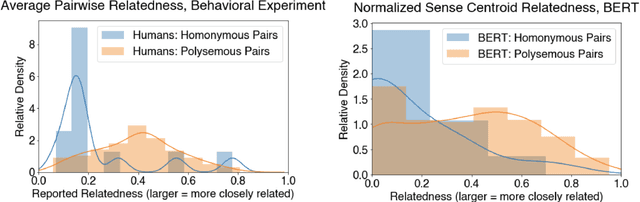

Understanding context-dependent variation in word meanings is a key aspect of human language comprehension supported by the lexicon. Lexicographic resources (e.g., WordNet) capture only some of this context-dependent variation; for example, they often do not encode how closely senses, or discretized word meanings, are related to one another. Our work investigates whether recent advances in NLP, specifically contextualized word embeddings, capture human-like distinctions between English word senses, such as polysemy and homonymy. We collect data from a behavioral, web-based experiment, in which participants provide judgments of the relatedness of multiple WordNet senses of a word in a two-dimensional spatial arrangement task. We find that participants' judgments of the relatedness between senses are correlated with distances between senses in the BERT embedding space. Homonymous senses (e.g., bat as mammal vs. bat as sports equipment) are reliably more distant from one another in the embedding space than polysemous ones (e.g., chicken as animal vs. chicken as meat). Our findings point towards the potential utility of continuous-space representations of sense meanings.