 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord forms - not just their lengths- are optimized for efficient communication
Paper and Code
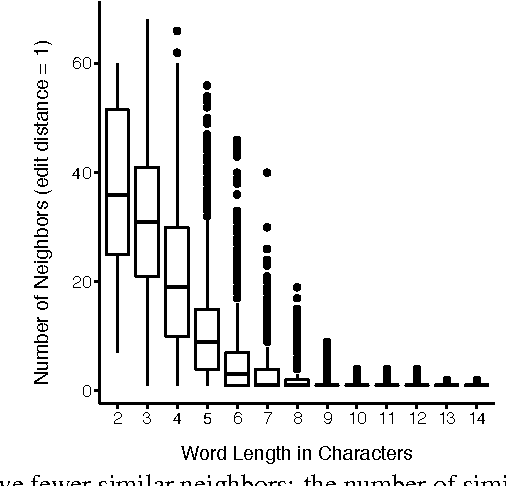
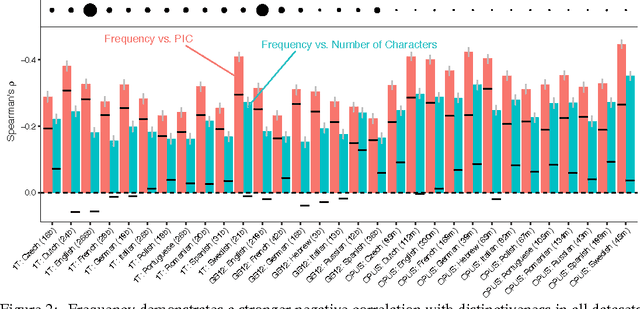
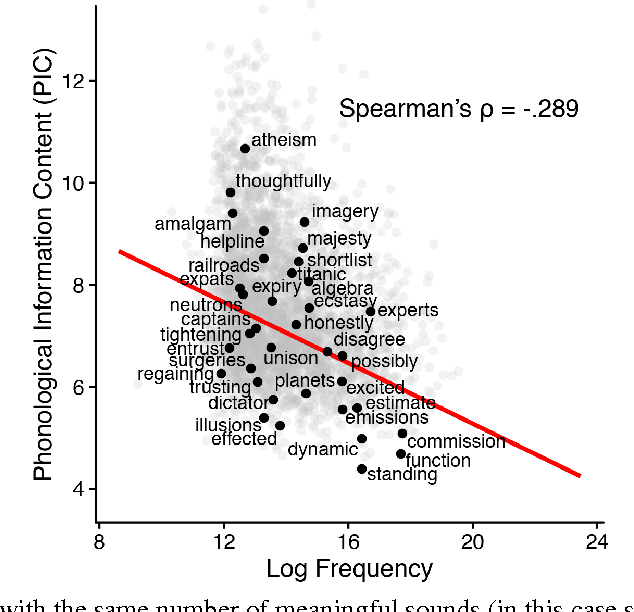
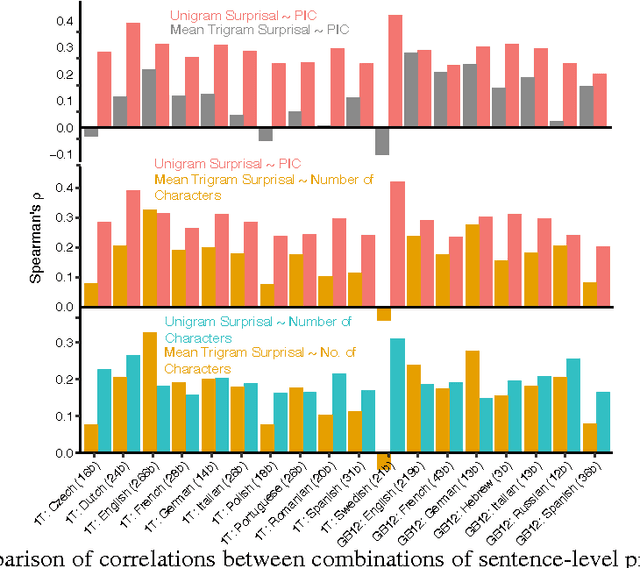
The inverse relationship between the length of a word and the frequency of its use, first identified by G.K. Zipf in 1935, is a classic empirical law that holds across a wide range of human languages. We demonstrate that length is one aspect of a much more general property of words: how distinctive they are with respect to other words in a language. Distinctiveness plays a critical role in recognizing words in fluent speech, in that it reflects the strength of potential competitors when selecting the best candidate for an ambiguous signal. Phonological information content, a measure of a word's string probability under a statistical model of a language's sound or character sequences, concisely captures distinctiveness. Examining large-scale corpora from 13 languages, we find that distinctiveness significantly outperforms word length as a predictor of frequency. This finding provides evidence that listeners' processing constraints shape fine-grained aspects of word forms across languages.