 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGISpeech 2.0: Transcribed multi-speaker financial audio for speaker-tagged transcription
Aug 07, 2025
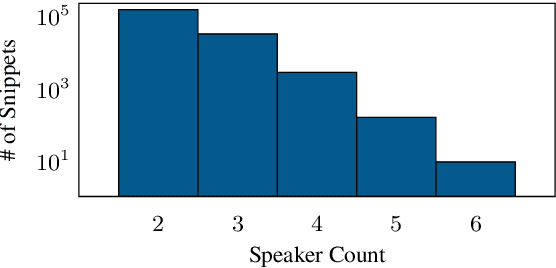
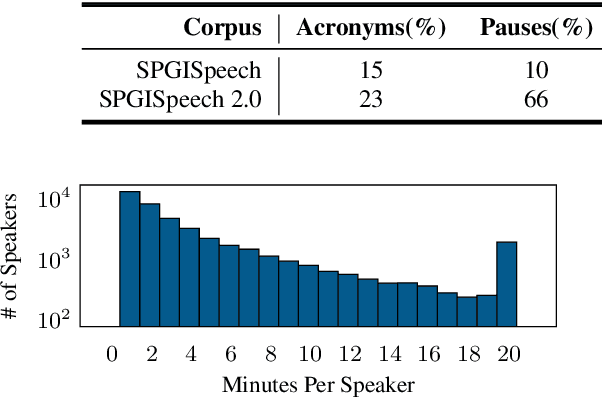
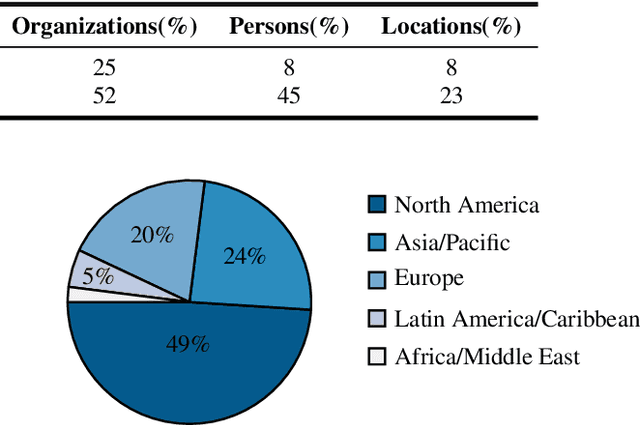
We introduce SPGISpeech 2.0, a dataset suitable for speaker-tagged transcription in the financial domain. SPGISpeech 2.0 improves the diversity of applicable modeling tasks while maintaining the core characteristic of the original SPGISpeech dataset: audio snippets and their corresponding fully formatted text transcriptions, usable for end-to-end automatic speech recognition (ASR). SPGISpeech 2.0 consists of 3,780 additional hours of professionally transcribed earnings calls. Furthermore, the dataset contains call and speaker information for each audio snippet facilitating multi-talker ASR. We validate the utility of SPGISpeech 2.0 through improvements in speaker-tagged ASR performance of popular speech recognition models after fine-tuning on SPGISpeech 2.0. Released free for non-commercial use, we expect SPGISpeech 2.0 to foster advancements in speech recognition technologies and inspire a wide range of research applications.
Improving Language Identification for Multilingual Speakers
Jan 29, 2020
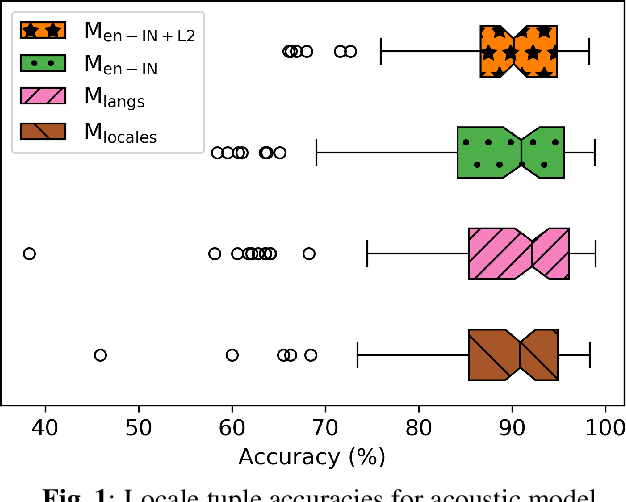
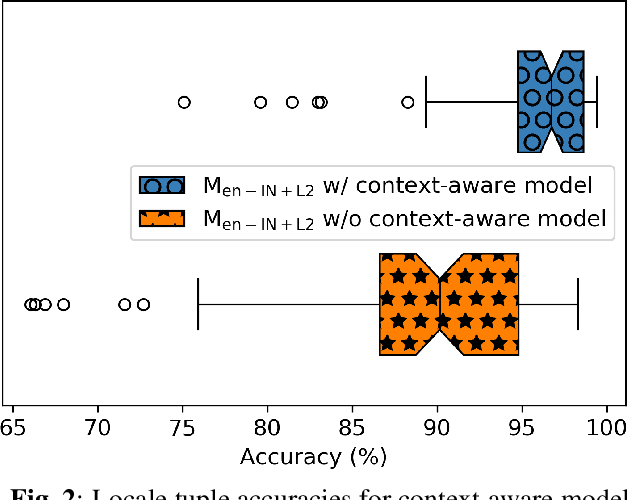

Spoken language identification (LID) technologies have improved in recent years from discriminating largely distinct languages to discriminating highly similar languages or even dialects of the same language. One aspect that has been mostly neglected, however, is discrimination of languages for multilingual speakers, despite being a primary target audience of many systems that utilize LID technologies. As we show in this work, LID systems can have a high average accuracy for most combinations of languages while greatly underperforming for others when accented speech is present. We address this by using coarser-grained targets for the acoustic LID model and integrating its outputs with interaction context signals in a context-aware model to tailor the system to each user. This combined system achieves an average 97% accuracy across all language combinations while improving worst-case accuracy by over 60% relative to our baseline.