 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
Optimizing Contextual Speech Recognition Using Vector Quantization for Efficient Retrieval
Nov 04, 2024Neural contextual biasing allows speech recognition models to leverage contextually relevant information, leading to improved transcription accuracy. However, the biasing mechanism is typically based on a cross-attention module between the audio and a catalogue of biasing entries, which means computational complexity can pose severe practical limitations on the size of the biasing catalogue and consequently on accuracy improvements. This work proposes an approximation to cross-attention scoring based on vector quantization and enables compute- and memory-efficient use of large biasing catalogues. We propose to use this technique jointly with a retrieval based contextual biasing approach. First, we use an efficient quantized retrieval module to shortlist biasing entries by grounding them on audio. Then we use retrieved entries for biasing. Since the proposed approach is agnostic to the biasing method, we investigate using full cross-attention, LLM prompting, and a combination of the two. We show that retrieval based shortlisting allows the system to efficiently leverage biasing catalogues of several thousands of entries, resulting in up to 71% relative error rate reduction in personal entity recognition. At the same time, the proposed approximation algorithm reduces compute time by 20% and memory usage by 85-95%, for lists of up to one million entries, when compared to standard dot-product cross-attention.
Optimizing Byte-level Representation for End-to-end ASR
Jun 14, 2024We propose a novel approach to optimizing a byte-level representation for end-to-end automatic speech recognition (ASR). Byte-level representation is often used by large scale multilingual ASR systems when the character set of the supported languages is large. The compactness and universality of byte-level representation allow the ASR models to use smaller output vocabularies and therefore, provide more flexibility. UTF-8 is a commonly used byte-level representation for multilingual ASR, but it is not designed to optimize machine learning tasks directly. By using auto-encoder and vector quantization, we show that we can optimize a byte-level representation for ASR and achieve better accuracy. Our proposed framework can incorporate information from different modalities, and provides an error correction mechanism. In an English/Mandarin dictation task, we show that a bilingual ASR model built with this approach can outperform UTF-8 representation by 5% relative in error rate.
Cross-lingual Knowledge Transfer and Iterative Pseudo-labeling for Low-Resource Speech Recognition with Transducers
May 23, 2023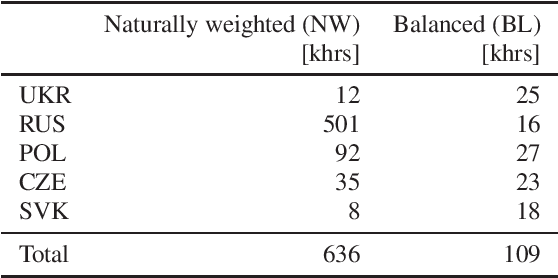


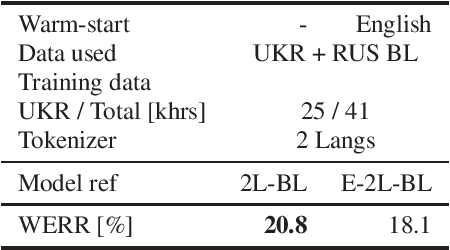
Voice technology has become ubiquitous recently. However, the accuracy, and hence experience, in different languages varies significantly, which makes the technology not equally inclusive. The availability of data for different languages is one of the key factors affecting accuracy, especially in training of all-neural end-to-end automatic speech recognition systems. Cross-lingual knowledge transfer and iterative pseudo-labeling are two techniques that have been shown to be successful for improving the accuracy of ASR systems, in particular for low-resource languages, like Ukrainian. Our goal is to train an all-neural Transducer-based ASR system to replace a DNN-HMM hybrid system with no manually annotated training data. We show that the Transducer system trained using transcripts produced by the hybrid system achieves 18% reduction in terms of word error rate. However, using a combination of cross-lingual knowledge transfer from related languages and iterative pseudo-labeling, we are able to achieve 35% reduction of the error rate.
Neural Transducer Training: Reduced Memory Consumption with Sample-wise Computation
Nov 29, 2022The neural transducer is an end-to-end model for automatic speech recognition (ASR). While the model is well-suited for streaming ASR, the training process remains challenging. During training, the memory requirements may quickly exceed the capacity of state-of-the-art GPUs, limiting batch size and sequence lengths. In this work, we analyze the time and space complexity of a typical transducer training setup. We propose a memory-efficient training method that computes the transducer loss and gradients sample by sample. We present optimizations to increase the efficiency and parallelism of the sample-wise method. In a set of thorough benchmarks, we show that our sample-wise method significantly reduces memory usage, and performs at competitive speed when compared to the default batched computation. As a highlight, we manage to compute the transducer loss and gradients for a batch size of 1024, and audio length of 40 seconds, using only 6 GB of memory.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Bilingual End-to-End ASR with Byte-Level Subwords
May 01, 2022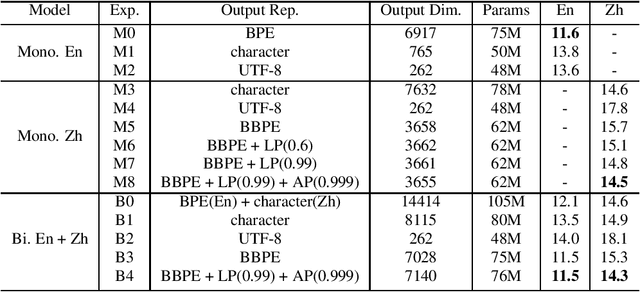
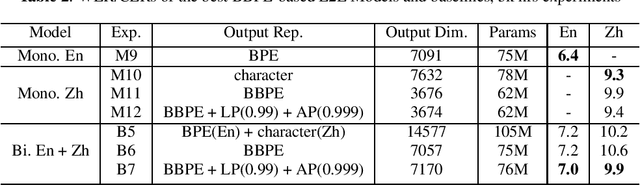
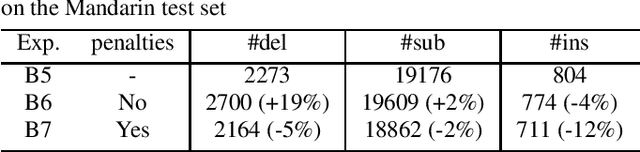
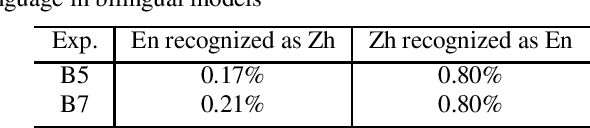
In this paper, we investigate how the output representation of an end-to-end neural network affects multilingual automatic speech recognition (ASR). We study different representations including character-level, byte-level, byte pair encoding (BPE), and byte-level byte pair encoding (BBPE) representations, and analyze their strengths and weaknesses. We focus on developing a single end-to-end model to support utterance-based bilingual ASR, where speakers do not alternate between two languages in a single utterance but may change languages across utterances. We conduct our experiments on English and Mandarin dictation tasks, and we find that BBPE with penalty schemes can improve utterance-based bilingual ASR performance by 2% to 5% relative even with smaller number of outputs and fewer parameters. We conclude with analysis that indicates directions for further improving multilingual ASR.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020

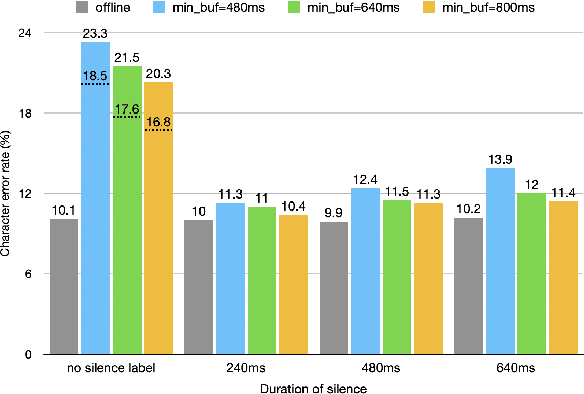
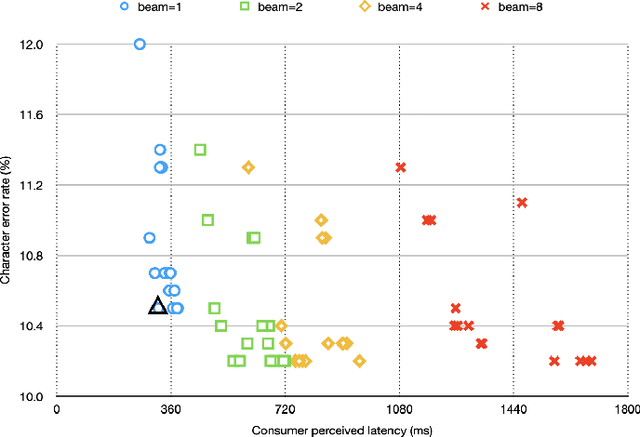
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.
Improving Language Identification for Multilingual Speakers
Jan 29, 2020
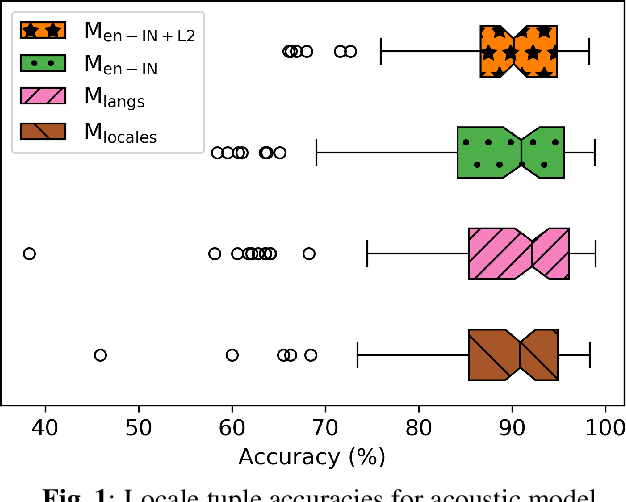
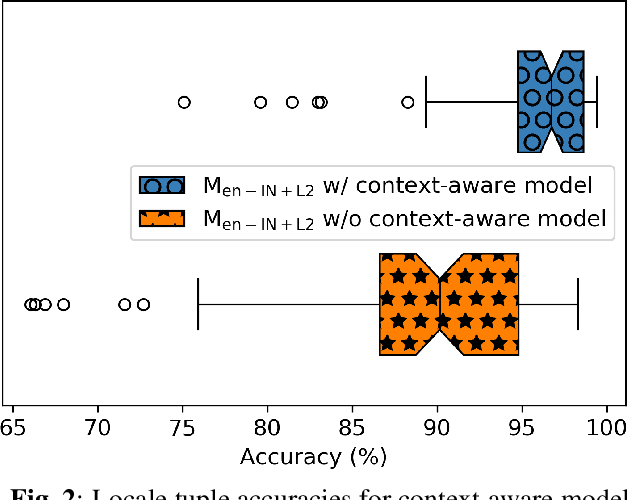

Spoken language identification (LID) technologies have improved in recent years from discriminating largely distinct languages to discriminating highly similar languages or even dialects of the same language. One aspect that has been mostly neglected, however, is discrimination of languages for multilingual speakers, despite being a primary target audience of many systems that utilize LID technologies. As we show in this work, LID systems can have a high average accuracy for most combinations of languages while greatly underperforming for others when accented speech is present. We address this by using coarser-grained targets for the acoustic LID model and integrating its outputs with interaction context signals in a context-aware model to tailor the system to each user. This combined system achieves an average 97% accuracy across all language combinations while improving worst-case accuracy by over 60% relative to our baseline.
Migrating Monarch Butterfly Localization Using Multi-Sensor Fusion Neural Networks
Dec 14, 2019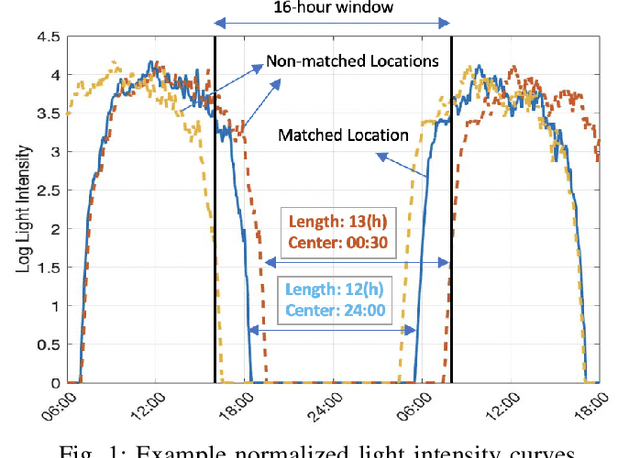
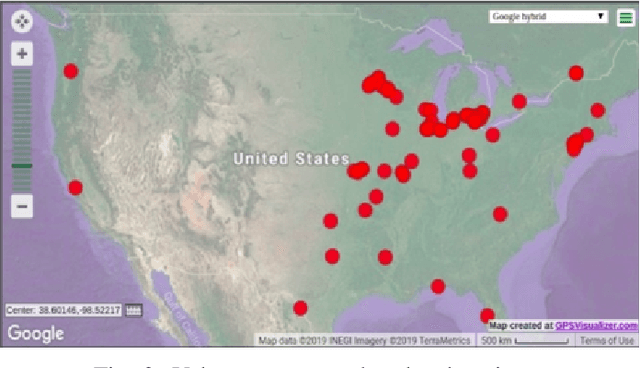
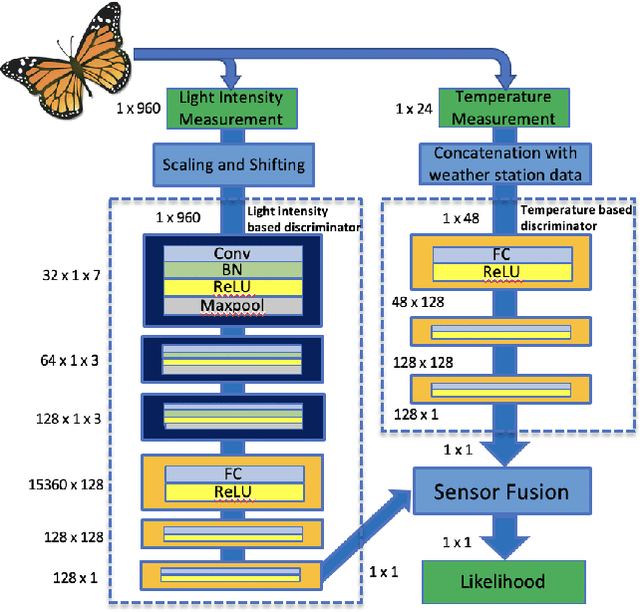
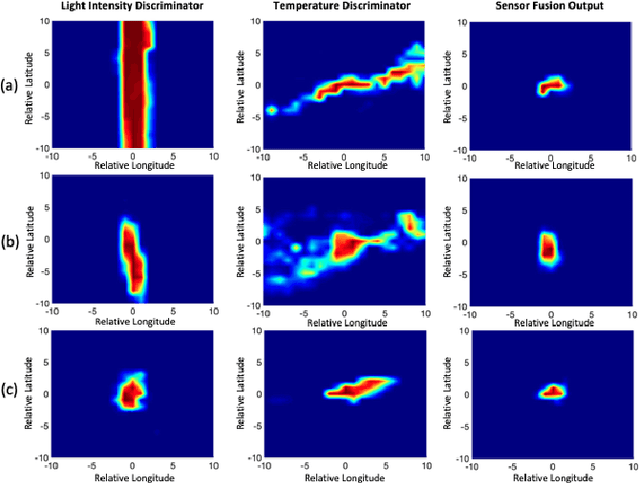
Details of Monarch butterfly migration from the U.S. to Mexico remain a mystery due to lack of a proper localization technology to accurately localize and track butterfly migration. In this paper, we propose a deep learning based butterfly localization algorithm that can estimate a butterfly's daily location by analyzing a light and temperature sensor data log continuously obtained from an ultra-low power, mm-scale sensor attached to the butterfly. To train and test the proposed neural network based multi-sensor fusion localization algorithm, we collected over 1500 days of real world sensor measurement data with 82 volunteers all over the U.S. The proposed algorithm exhibits a mean absolute error of <1.5 degree in latitude and <0.5 degree in longitude Earth coordinate, satisfying our target goal for the Monarch butterfly migration study.