 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual End-to-End ASR with Byte-Level Subwords
Paper and Code
May 01, 2022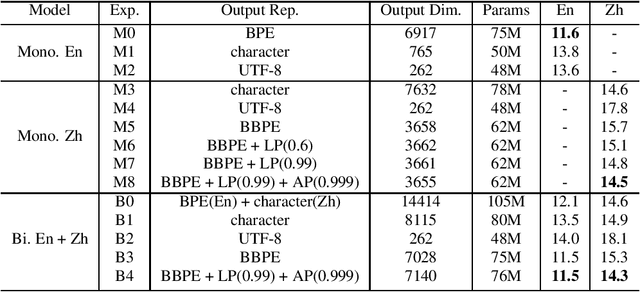
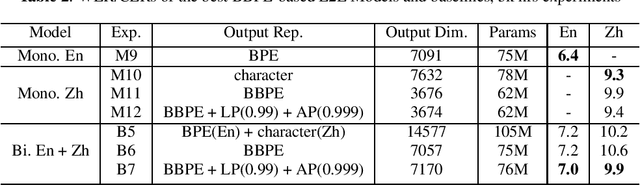
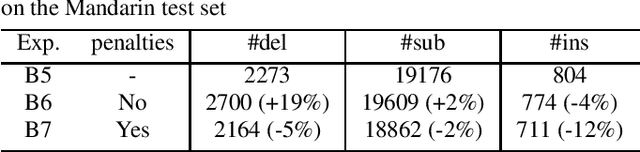
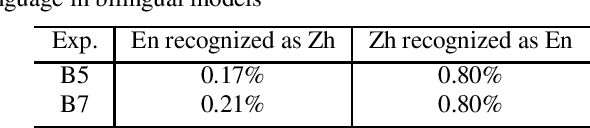
In this paper, we investigate how the output representation of an end-to-end neural network affects multilingual automatic speech recognition (ASR). We study different representations including character-level, byte-level, byte pair encoding (BPE), and byte-level byte pair encoding (BBPE) representations, and analyze their strengths and weaknesses. We focus on developing a single end-to-end model to support utterance-based bilingual ASR, where speakers do not alternate between two languages in a single utterance but may change languages across utterances. We conduct our experiments on English and Mandarin dictation tasks, and we find that BBPE with penalty schemes can improve utterance-based bilingual ASR performance by 2% to 5% relative even with smaller number of outputs and fewer parameters. We conclude with analysis that indicates directions for further improving multilingual ASR.