 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a World-English Language Model for On-Device Virtual Assistants
Mar 27, 2024



Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them. Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English'' NNLM for on-device VAs. In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs {and enhance the multi-dialect baselines}. We find that adapter modules are more effective in modeling dialects than specializing entire sub-networks. Based on this insight and leveraging the design of our production models, we introduce a new architecture for World English NNLM that meets the accuracy, latency, and memory constraints of our single-dialect models.
Cross-lingual Knowledge Transfer and Iterative Pseudo-labeling for Low-Resource Speech Recognition with Transducers
May 23, 2023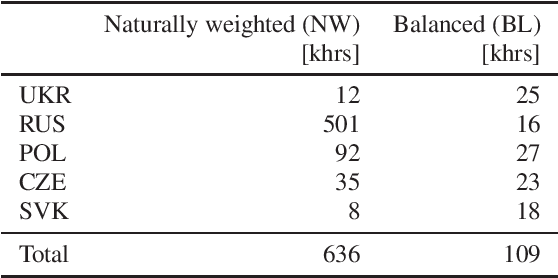


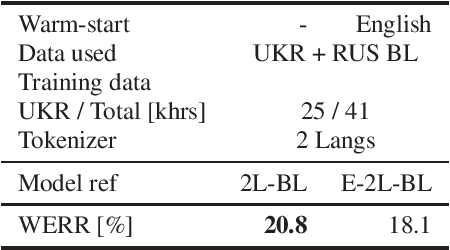
Voice technology has become ubiquitous recently. However, the accuracy, and hence experience, in different languages varies significantly, which makes the technology not equally inclusive. The availability of data for different languages is one of the key factors affecting accuracy, especially in training of all-neural end-to-end automatic speech recognition systems. Cross-lingual knowledge transfer and iterative pseudo-labeling are two techniques that have been shown to be successful for improving the accuracy of ASR systems, in particular for low-resource languages, like Ukrainian. Our goal is to train an all-neural Transducer-based ASR system to replace a DNN-HMM hybrid system with no manually annotated training data. We show that the Transducer system trained using transcripts produced by the hybrid system achieves 18% reduction in terms of word error rate. However, using a combination of cross-lingual knowledge transfer from related languages and iterative pseudo-labeling, we are able to achieve 35% reduction of the error rate.
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices
Jul 18, 2022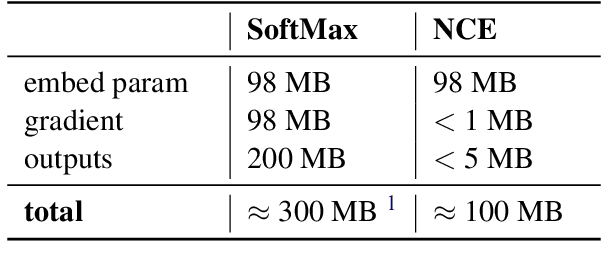
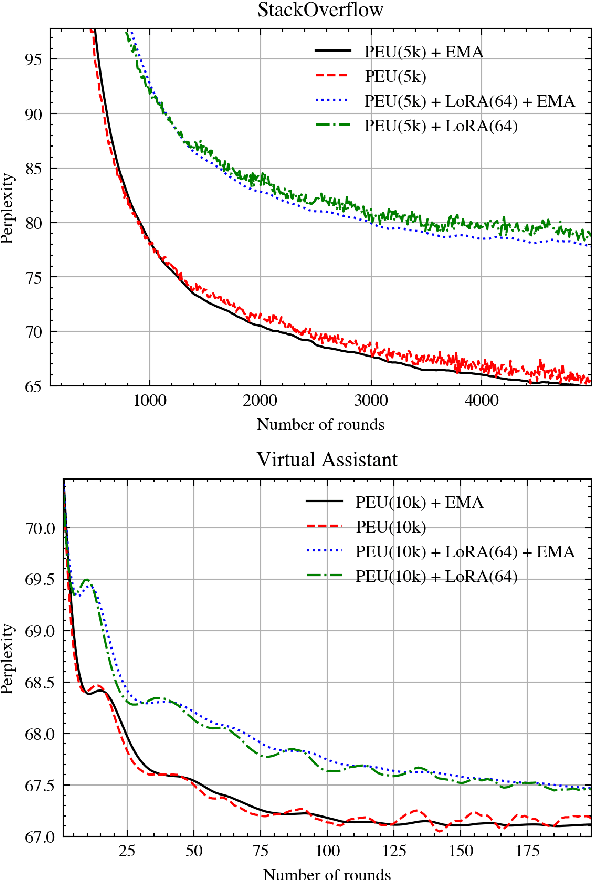

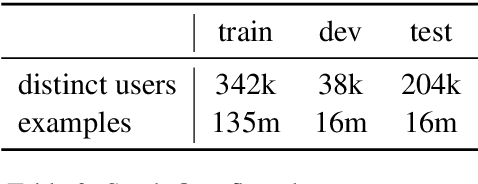
Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents convergence. We propose Partial Embedding Updates (PEU), a novel technique to decrease noise by decreasing payload size. Furthermore, we adopt Low Rank Adaptation (LoRA) and Noise Contrastive Estimation (NCE) to reduce the memory demands of large models on compute-constrained devices. This combination of techniques makes it possible to train large-vocabulary language models while preserving accuracy and privacy.
Composing Finite State Transducers on GPUs
May 16, 2018

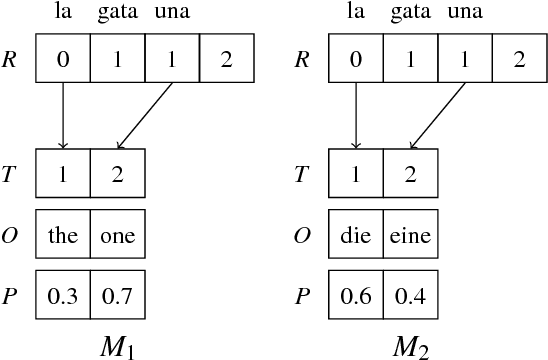

Weighted finite-state transducers (FSTs) are frequently used in language processing to handle tasks such as part-of-speech tagging and speech recognition. There has been previous work using multiple CPU cores to accelerate finite state algorithms, but limited attention has been given to parallel graphics processing unit (GPU) implementations. In this paper, we introduce the first (to our knowledge) GPU implementation of the FST composition operation, and we also discuss the optimizations used to achieve the best performance on this architecture. We show that our approach obtains speedups of up to 6x over our serial implementation and 4.5x over OpenFST.
Decoding with Finite-State Transducers on GPUs
Jan 17, 2017

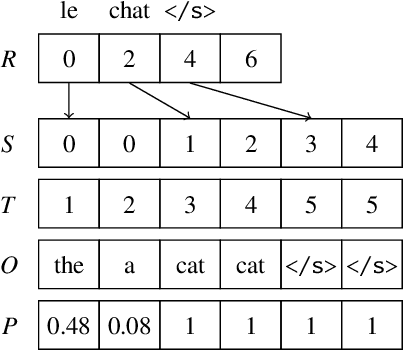
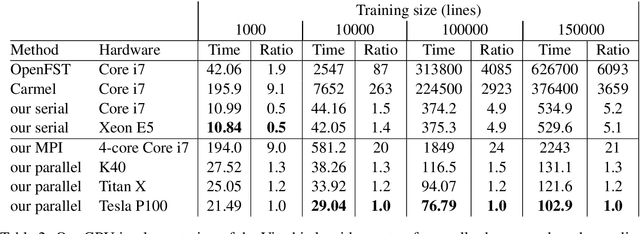
Weighted finite automata and transducers (including hidden Markov models and conditional random fields) are widely used in natural language processing (NLP) to perform tasks such as morphological analysis, part-of-speech tagging, chunking, named entity recognition, speech recognition, and others. Parallelizing finite state algorithms on graphics processing units (GPUs) would benefit many areas of NLP. Although researchers have implemented GPU versions of basic graph algorithms, limited previous work, to our knowledge, has been done on GPU algorithms for weighted finite automata. We introduce a GPU implementation of the Viterbi and forward-backward algorithm, achieving decoding speedups of up to 5.2x over our serial implementation running on different computer architectures and 6093x over OpenFST.