 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepfl-research: simulation framework for accelerating research in Private Federated Learning
Apr 09, 2024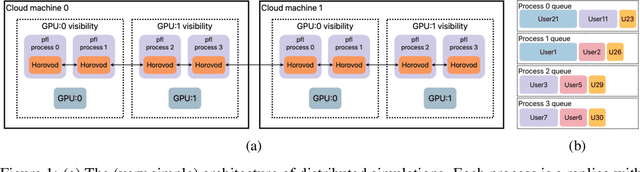
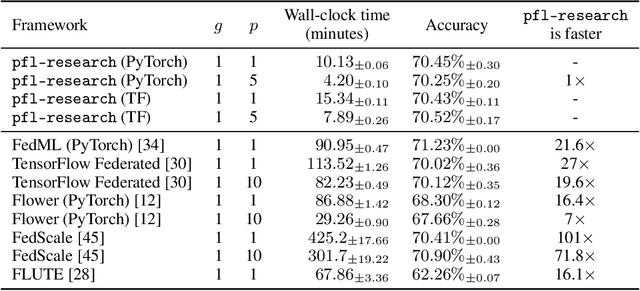

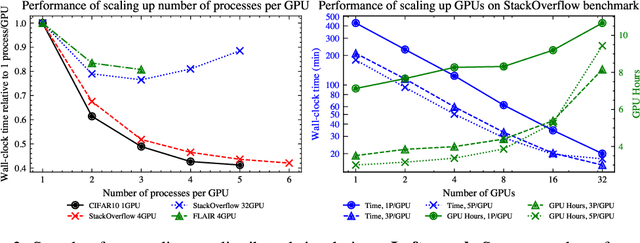
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Samplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices
Jul 18, 2022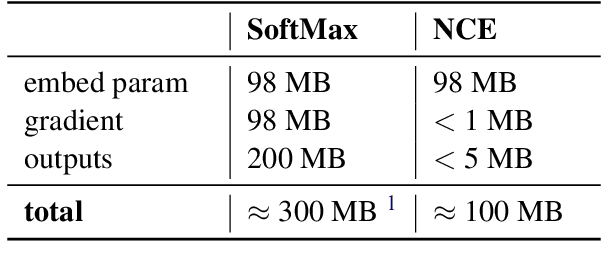
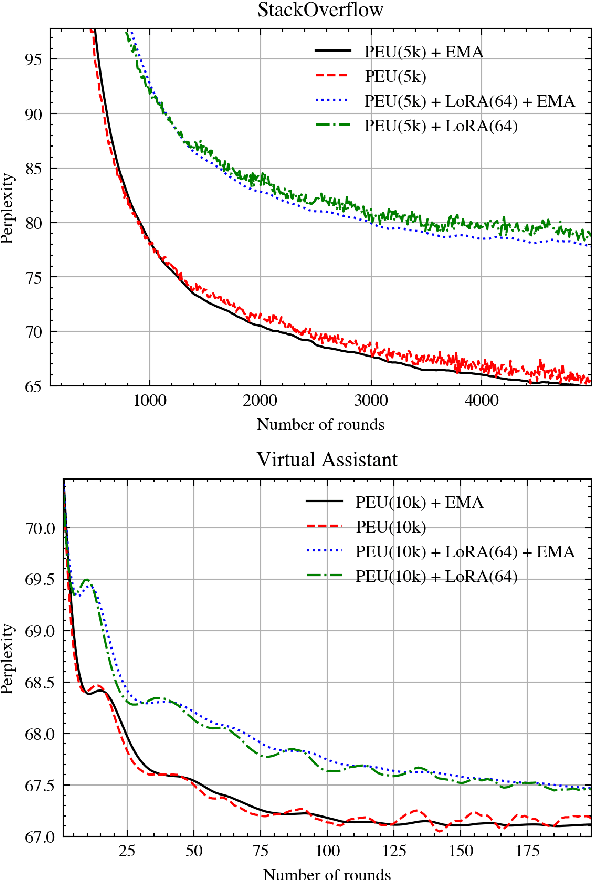

Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents convergence. We propose Partial Embedding Updates (PEU), a novel technique to decrease noise by decreasing payload size. Furthermore, we adopt Low Rank Adaptation (LoRA) and Noise Contrastive Estimation (NCE) to reduce the memory demands of large models on compute-constrained devices. This combination of techniques makes it possible to train large-vocabulary language models while preserving accuracy and privacy.
FLAIR: Federated Learning Annotated Image Repository
Jul 18, 2022
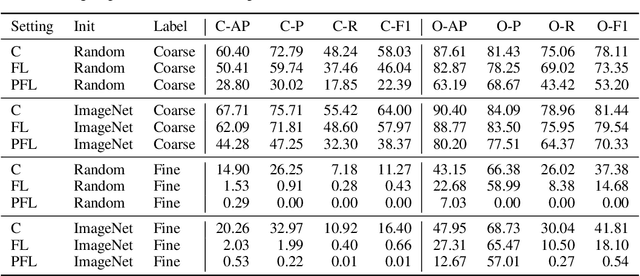
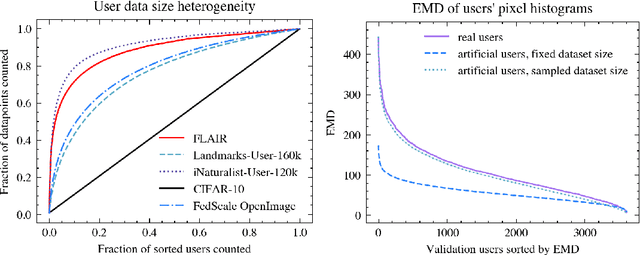
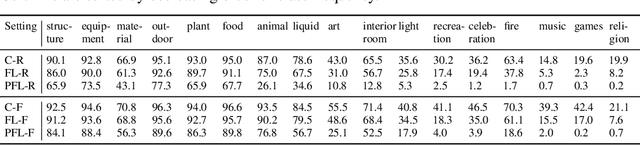
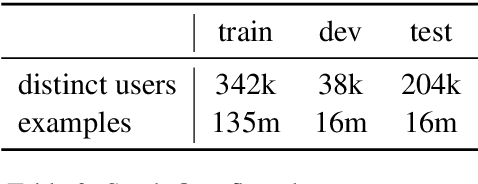
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices. This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed. Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning. FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution. We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning. Dataset access and the code for the benchmark are available at \url{https://github.com/apple/ml-flair}.
Enforcing fairness in private federated learning via the modified method of differential multipliers
Sep 17, 2021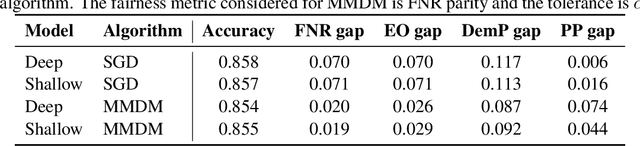
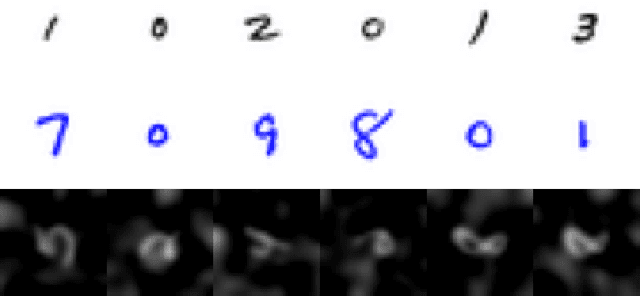
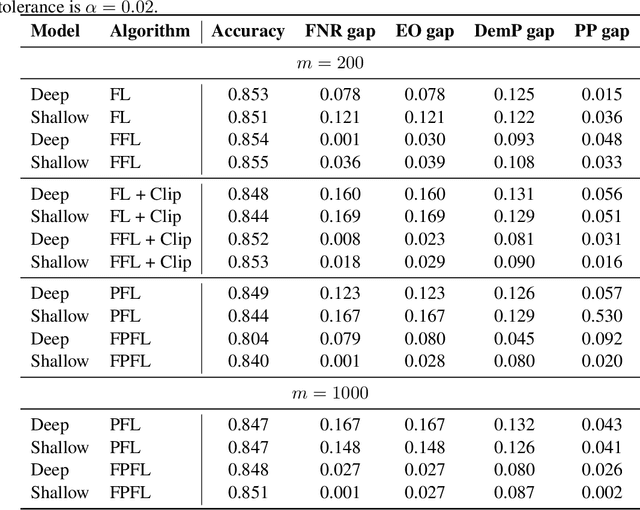
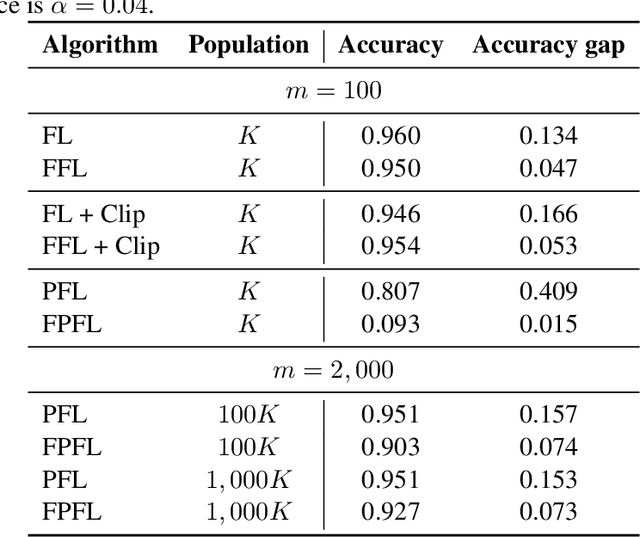
Federated learning with differential privacy, or private federated learning, provides a strategy to train machine learning models while respecting users' privacy. However, differential privacy can disproportionately degrade the performance of the models on under-represented groups, as these parts of the distribution are difficult to learn in the presence of noise. Existing approaches for enforcing fairness in machine learning models have considered the centralized setting, in which the algorithm has access to the users' data. This paper introduces an algorithm to enforce group fairness in private federated learning, where users' data does not leave their devices. First, the paper extends the modified method of differential multipliers to empirical risk minimization with fairness constraints, thus providing an algorithm to enforce fairness in the central setting. Then, this algorithm is extended to the private federated learning setting. The proposed algorithm, FPFL, is tested on a federated version of the Adult dataset and an "unfair" version of the FEMNIST dataset. The experiments on these datasets show how private federated learning accentuates unfairness in the trained models, and how FPFL is able to mitigate such unfairness.
Federated Evaluation and Tuning for On-Device Personalization: System Design & Applications
Feb 16, 2021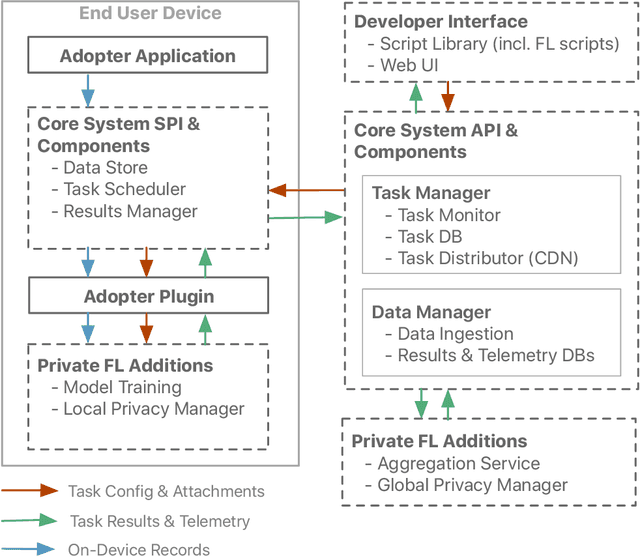
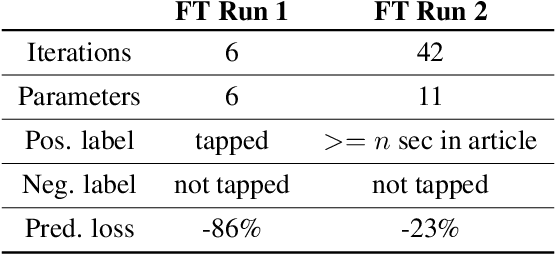

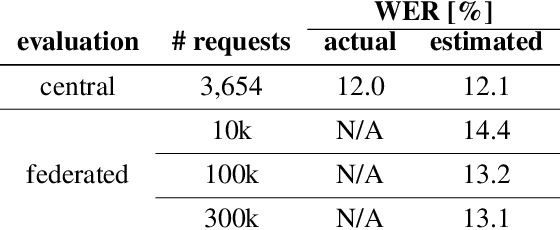
We describe the design of our federated task processing system. Originally, the system was created to support two specific federated tasks: evaluation and tuning of on-device ML systems, primarily for the purpose of personalizing these systems. In recent years, support for an additional federated task has been added: federated learning (FL) of deep neural networks. To our knowledge, only one other system has been described in literature that supports FL at scale. We include comparisons to that system to help discuss design decisions and attached trade-offs. Finally, we describe two specific large scale personalization use cases in detail to showcase the applicability of federated tuning to on-device personalization and to highlight application specific solutions.
Improving on-device speaker verification using federated learning with privacy
Aug 06, 2020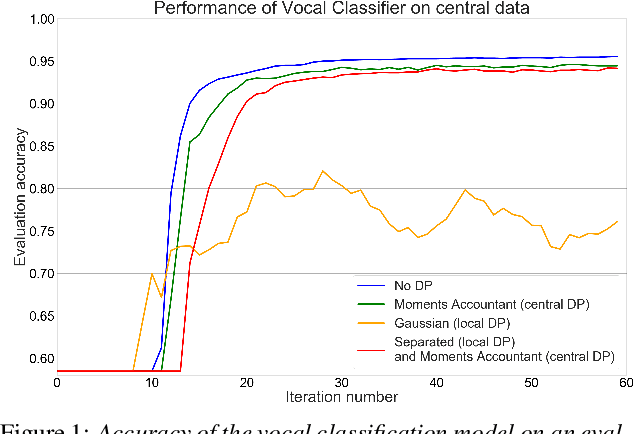

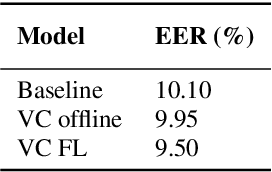
Information on speaker characteristics can be useful as side information in improving speaker recognition accuracy. However, such information is often private. This paper investigates how privacy-preserving learning can improve a speaker verification system, by enabling the use of privacy-sensitive speaker data to train an auxiliary classification model that predicts vocal characteristics of speakers. In particular, this paper explores the utility achieved by approaches which combine different federated learning and differential privacy mechanisms. These approaches make it possible to train a central model while protecting user privacy, with users' data remaining on their devices. Furthermore, they make learning on a large population of speakers possible, ensuring good coverage of speaker characteristics when training a model. The auxiliary model described here uses features extracted from phrases which trigger a speaker verification system. From these features, the model predicts speaker characteristic labels considered useful as side information. The knowledge of the auxiliary model is distilled into a speaker verification system using multi-task learning, with the side information labels predicted by this auxiliary model being the additional task. This approach results in a 6% relative improvement in equal error rate over a baseline system.