 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving on-device speaker verification using federated learning with privacy
Paper and Code
Aug 06, 2020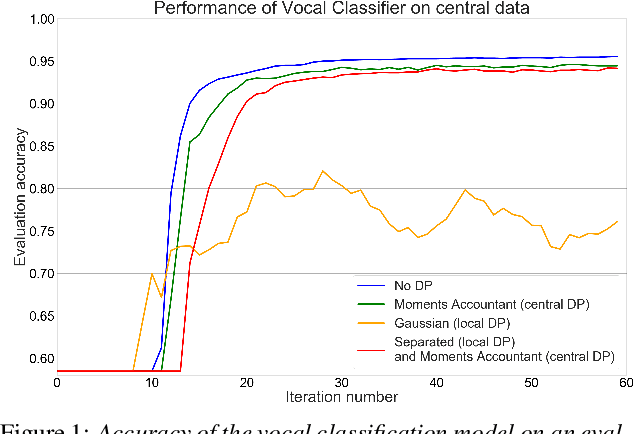

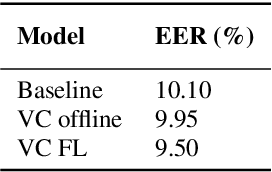
Information on speaker characteristics can be useful as side information in improving speaker recognition accuracy. However, such information is often private. This paper investigates how privacy-preserving learning can improve a speaker verification system, by enabling the use of privacy-sensitive speaker data to train an auxiliary classification model that predicts vocal characteristics of speakers. In particular, this paper explores the utility achieved by approaches which combine different federated learning and differential privacy mechanisms. These approaches make it possible to train a central model while protecting user privacy, with users' data remaining on their devices. Furthermore, they make learning on a large population of speakers possible, ensuring good coverage of speaker characteristics when training a model. The auxiliary model described here uses features extracted from phrases which trigger a speaker verification system. From these features, the model predicts speaker characteristic labels considered useful as side information. The knowledge of the auxiliary model is distilled into a speaker verification system using multi-task learning, with the side information labels predicted by this auxiliary model being the additional task. This approach results in a 6% relative improvement in equal error rate over a baseline system.