 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Modelling of Federated Datasets using Mixtures-of-Dirichlet-Multinomials
Jun 04, 2024

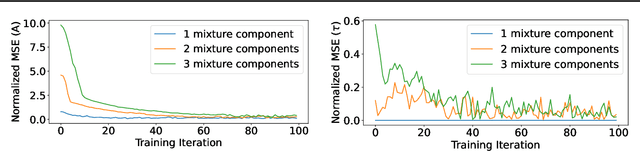

In practice, training using federated learning can be orders of magnitude slower than standard centralized training. This severely limits the amount of experimentation and tuning that can be done, making it challenging to obtain good performance on a given task. Server-side proxy data can be used to run training simulations, for instance for hyperparameter tuning. This can greatly speed up the training pipeline by reducing the number of tuning runs to be performed overall on the true clients. However, it is challenging to ensure that these simulations accurately reflect the dynamics of the real federated training. In particular, the proxy data used for simulations often comes as a single centralized dataset without a partition into distinct clients, and partitioning this data in a naive way can lead to simulations that poorly reflect real federated training. In this paper we address the challenge of how to partition centralized data in a way that reflects the statistical heterogeneity of the true federated clients. We propose a fully federated, theoretically justified, algorithm that efficiently learns the distribution of the true clients and observe improved server-side simulations when using the inferred distribution to create simulated clients from the centralized data.
pfl-research: simulation framework for accelerating research in Private Federated Learning
Apr 09, 2024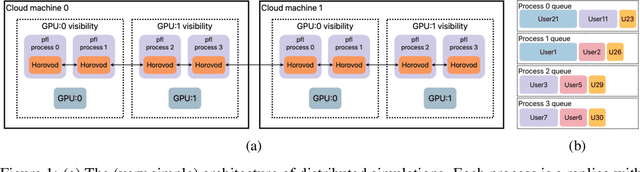
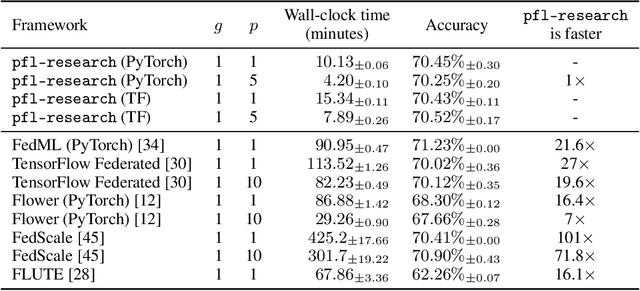

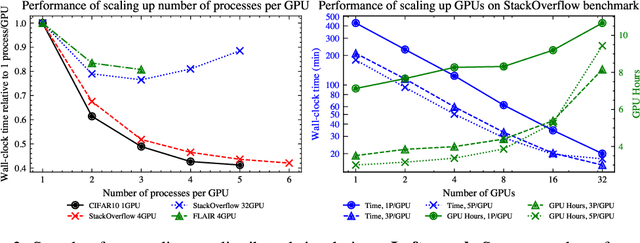
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Training a Tokenizer for Free with Private Federated Learning
Mar 15, 2022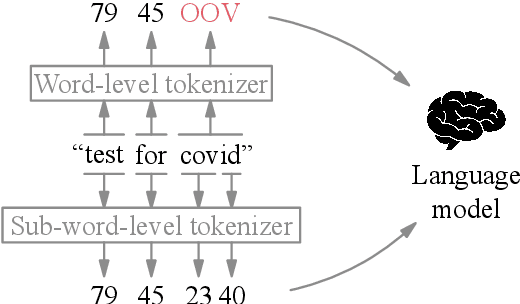
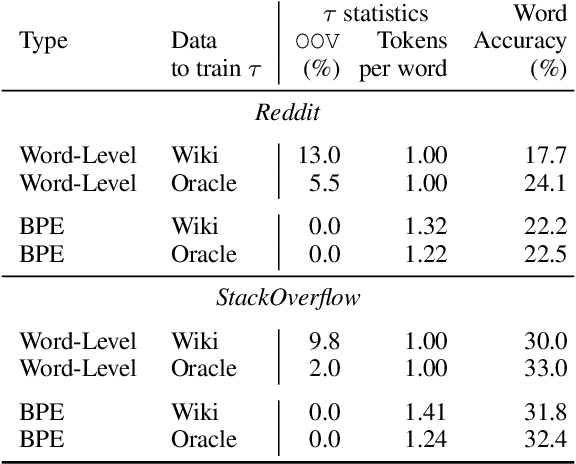
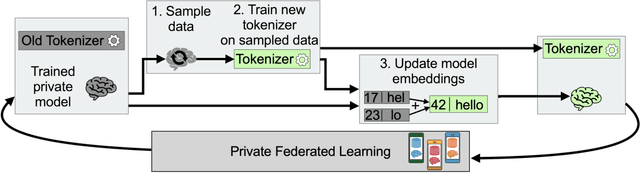
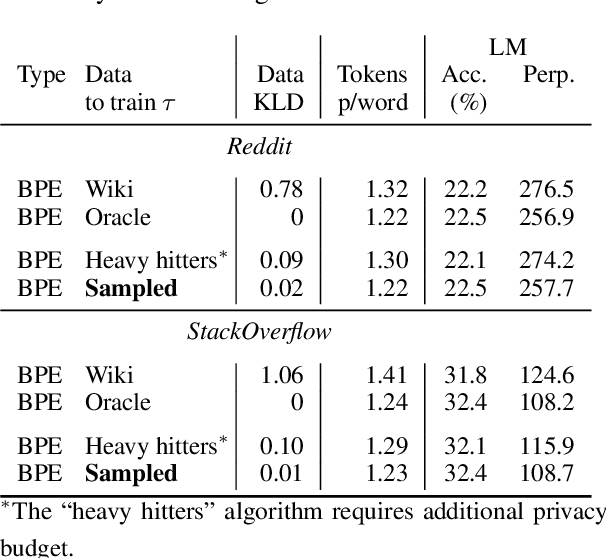
Federated learning with differential privacy, i.e. private federated learning (PFL), makes it possible to train models on private data distributed across users' devices without harming privacy. PFL is efficient for models, such as neural networks, that have a fixed number of parameters, and thus a fixed-dimensional gradient vector. Such models include neural-net language models, but not tokenizers, the topic of this work. Training a tokenizer requires frequencies of words from an unlimited vocabulary, and existing methods for finding an unlimited vocabulary need a separate privacy budget. A workaround is to train the tokenizer on publicly available data. However, in this paper we first show that a tokenizer trained on mismatched data results in worse model performance compared to a privacy-violating "oracle" tokenizer that accesses user data, with perplexity increasing by 20%. We also show that sub-word tokenizers are better suited to the federated context than word-level ones, since they can encode new words, though with more tokens per word. Second, we propose a novel method to obtain a tokenizer without using any additional privacy budget. During private federated learning of the language model, we sample from the model, train a new tokenizer on the sampled sequences, and update the model embeddings. We then continue private federated learning, and obtain performance within 1% of the "oracle" tokenizer. Since this process trains the tokenizer only indirectly on private data, we can use the "postprocessing guarantee" of differential privacy and thus use no additional privacy budget.
Federated Evaluation and Tuning for On-Device Personalization: System Design & Applications
Feb 16, 2021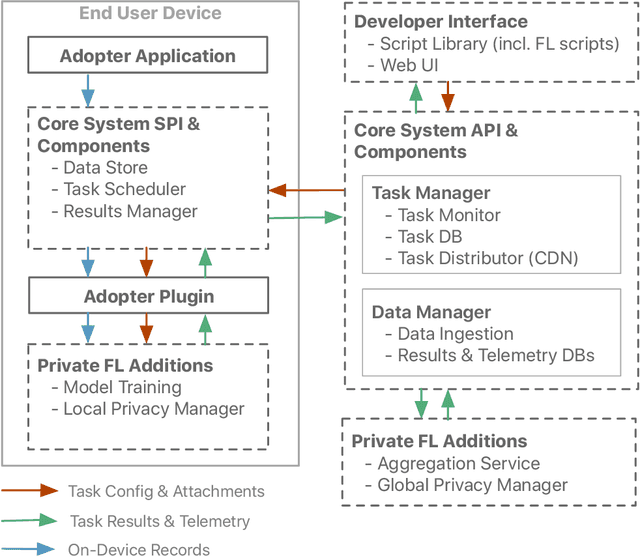
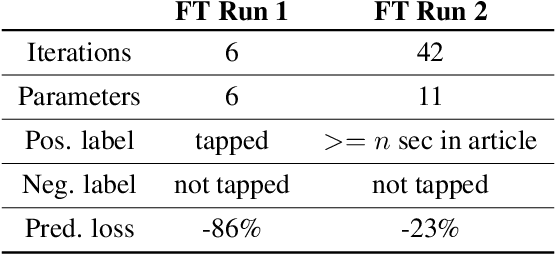

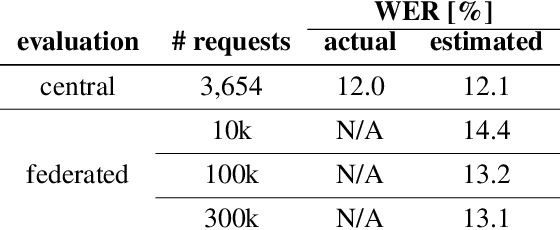
We describe the design of our federated task processing system. Originally, the system was created to support two specific federated tasks: evaluation and tuning of on-device ML systems, primarily for the purpose of personalizing these systems. In recent years, support for an additional federated task has been added: federated learning (FL) of deep neural networks. To our knowledge, only one other system has been described in literature that supports FL at scale. We include comparisons to that system to help discuss design decisions and attached trade-offs. Finally, we describe two specific large scale personalization use cases in detail to showcase the applicability of federated tuning to on-device personalization and to highlight application specific solutions.
Improving on-device speaker verification using federated learning with privacy
Aug 06, 2020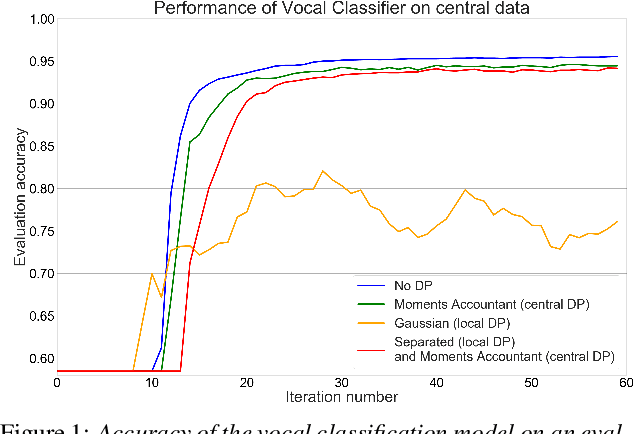

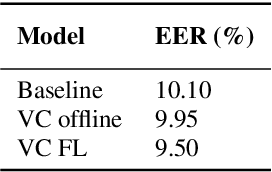
Information on speaker characteristics can be useful as side information in improving speaker recognition accuracy. However, such information is often private. This paper investigates how privacy-preserving learning can improve a speaker verification system, by enabling the use of privacy-sensitive speaker data to train an auxiliary classification model that predicts vocal characteristics of speakers. In particular, this paper explores the utility achieved by approaches which combine different federated learning and differential privacy mechanisms. These approaches make it possible to train a central model while protecting user privacy, with users' data remaining on their devices. Furthermore, they make learning on a large population of speakers possible, ensuring good coverage of speaker characteristics when training a model. The auxiliary model described here uses features extracted from phrases which trigger a speaker verification system. From these features, the model predicts speaker characteristic labels considered useful as side information. The knowledge of the auxiliary model is distilled into a speaker verification system using multi-task learning, with the side information labels predicted by this auxiliary model being the additional task. This approach results in a 6% relative improvement in equal error rate over a baseline system.