 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Tokenizer for Free with Private Federated Learning
Paper and Code
Mar 15, 2022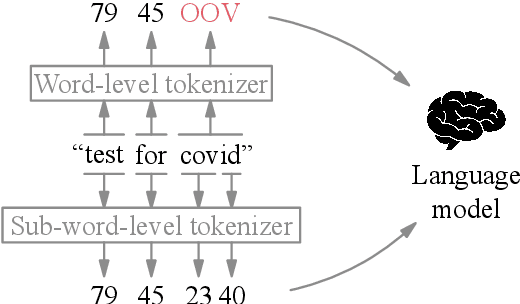
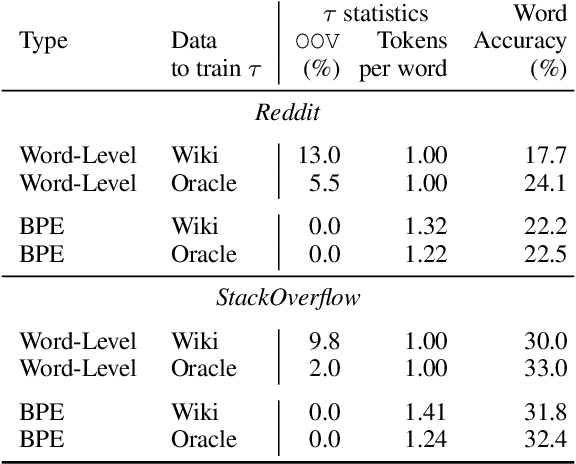
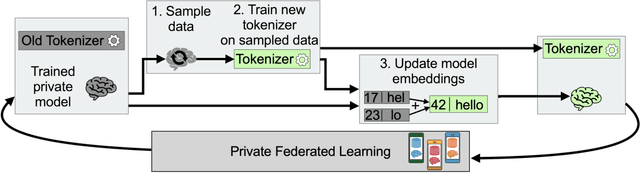
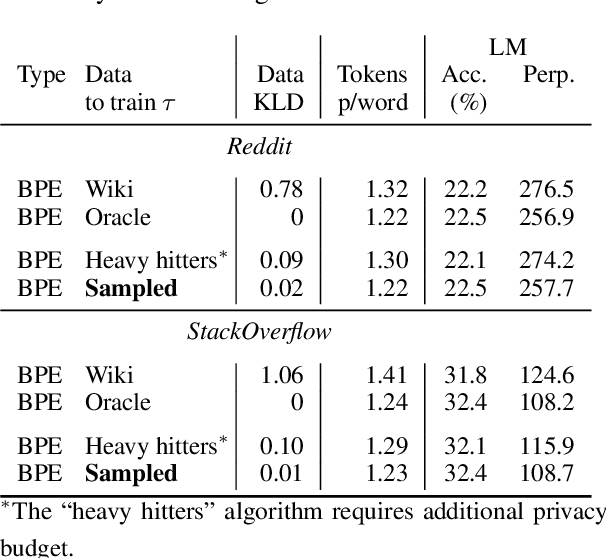
Federated learning with differential privacy, i.e. private federated learning (PFL), makes it possible to train models on private data distributed across users' devices without harming privacy. PFL is efficient for models, such as neural networks, that have a fixed number of parameters, and thus a fixed-dimensional gradient vector. Such models include neural-net language models, but not tokenizers, the topic of this work. Training a tokenizer requires frequencies of words from an unlimited vocabulary, and existing methods for finding an unlimited vocabulary need a separate privacy budget. A workaround is to train the tokenizer on publicly available data. However, in this paper we first show that a tokenizer trained on mismatched data results in worse model performance compared to a privacy-violating "oracle" tokenizer that accesses user data, with perplexity increasing by 20%. We also show that sub-word tokenizers are better suited to the federated context than word-level ones, since they can encode new words, though with more tokens per word. Second, we propose a novel method to obtain a tokenizer without using any additional privacy budget. During private federated learning of the language model, we sample from the model, train a new tokenizer on the sampled sequences, and update the model embeddings. We then continue private federated learning, and obtain performance within 1% of the "oracle" tokenizer. Since this process trains the tokenizer only indirectly on private data, we can use the "postprocessing guarantee" of differential privacy and thus use no additional privacy budget.