 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Minimax Regret Bounds for Reinforcement Learning based on Duality
Oct 21, 2024We study agents acting in an unknown environment where the agent's goal is to find a robust policy. We consider robust policies as policies that achieve high cumulative rewards for all possible environments. To this end, we consider agents minimizing the maximum regret over different environment parameters, leading to the study of minimax regret. This research focuses on deriving information-theoretic bounds for minimax regret in Markov Decision Processes (MDPs) with a finite time horizon. Building on concepts from supervised learning, such as minimum excess risk (MER) and minimax excess risk, we use recent bounds on the Bayesian regret to derive minimax regret bounds. Specifically, we establish minimax theorems and use bounds on the Bayesian regret to perform minimax regret analysis using these minimax theorems. Our contributions include defining a suitable minimax regret in the context of MDPs, finding information-theoretic bounds for it, and applying these bounds in various scenarios.
A Coding-Theoretic Analysis of Hyperspherical Prototypical Learning Geometry
Jul 10, 2024Hyperspherical Prototypical Learning (HPL) is a supervised approach to representation learning that designs class prototypes on the unit hypersphere. The prototypes bias the representations to class separation in a scale invariant and known geometry. Previous approaches to HPL have either of the following shortcomings: (i) they follow an unprincipled optimisation procedure; or (ii) they are theoretically sound, but are constrained to only one possible latent dimension. In this paper, we address both shortcomings. To address (i), we present a principled optimisation procedure whose solution we show is optimal. To address (ii), we construct well-separated prototypes in a wide range of dimensions using linear block codes. Additionally, we give a full characterisation of the optimal prototype placement in terms of achievable and converse bounds, showing that our proposed methods are near-optimal.
A note on generalization bounds for losses with finite moments
Mar 25, 2024
This paper studies the truncation method from Alquier [1] to derive high-probability PAC-Bayes bounds for unbounded losses with heavy tails. Assuming that the $p$-th moment is bounded, the resulting bounds interpolate between a slow rate $1 / \sqrt{n}$ when $p=2$, and a fast rate $1 / n$ when $p \to \infty$ and the loss is essentially bounded. Moreover, the paper derives a high-probability PAC-Bayes bound for losses with a bounded variance. This bound has an exponentially better dependence on the confidence parameter and the dependency measure than previous bounds in the literature. Finally, the paper extends all results to guarantees in expectation and single-draw PAC-Bayes. In order to so, it obtains analogues of the PAC-Bayes fast rate bound for bounded losses from [2] in these settings.
Chained Information-Theoretic bounds and Tight Regret Rate for Linear Bandit Problems
Mar 05, 2024This paper studies the Bayesian regret of a variant of the Thompson-Sampling algorithm for bandit problems. It builds upon the information-theoretic framework of [Russo and Van Roy, 2015] and, more specifically, on the rate-distortion analysis from [Dong and Van Roy, 2020], where they proved a bound with regret rate of $O(d\sqrt{T \log(T)})$ for the $d$-dimensional linear bandit setting. We focus on bandit problems with a metric action space and, using a chaining argument, we establish new bounds that depend on the metric entropy of the action space for a variant of Thompson-Sampling. Under suitable continuity assumption of the rewards, our bound offers a tight rate of $O(d\sqrt{T})$ for $d$-dimensional linear bandit problems.
The Role of Entropy and Reconstruction in Multi-View Self-Supervised Learning
Jul 20, 2023



The mechanisms behind the success of multi-view self-supervised learning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied through the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We consider a different lower bound on the MI consisting of an entropy and a reconstruction term (ER), and analyze the main MVSSL families through its lens. Through this ER bound, we show that clustering-based methods such as DeepCluster and SwAV maximize the MI. We also re-interpret the mechanisms of distillation-based approaches such as BYOL and DINO, showing that they explicitly maximize the reconstruction term and implicitly encourage a stable entropy, and we confirm this empirically. We show that replacing the objectives of common MVSSL methods with this ER bound achieves competitive performance, while making them stable when training with smaller batch sizes or smaller exponential moving average (EMA) coefficients. Github repo: https://github.com/apple/ml-entropy-reconstruction.
More PAC-Bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime-validity
Jun 21, 2023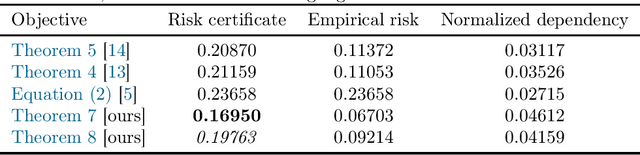
In this paper, we present new high-probability PAC-Bayes bounds for different types of losses. Firstly, for losses with a bounded range, we present a strengthened version of Catoni's bound that holds uniformly for all parameter values. This leads to new fast rate and mixed rate bounds that are interpretable and tighter than previous bounds in the literature. Secondly, for losses with more general tail behaviors, we introduce two new parameter-free bounds: a PAC-Bayes Chernoff analogue when the loss' cumulative generating function is bounded, and a bound when the loss' second moment is bounded. These two bounds are obtained using a new technique based on a discretization of the space of possible events for the "in probability" parameter optimization problem. Finally, we extend all previous results to anytime-valid bounds using a simple technique applicable to any existing bound.
Thompson Sampling Regret Bounds for Contextual Bandits with sub-Gaussian rewards
Apr 26, 2023In this work, we study the performance of the Thompson Sampling algorithm for Contextual Bandit problems based on the framework introduced by Neu et al. and their concept of lifted information ratio. First, we prove a comprehensive bound on the Thompson Sampling expected cumulative regret that depends on the mutual information of the environment parameters and the history. Then, we introduce new bounds on the lifted information ratio that hold for sub-Gaussian rewards, thus generalizing the results from Neu et al. which analysis requires binary rewards. Finally, we provide explicit regret bounds for the special cases of unstructured bounded contextual bandits, structured bounded contextual bandits with Laplace likelihood, structured Bernoulli bandits, and bounded linear contextual bandits.
Limitations of Information-Theoretic Generalization Bounds for Gradient Descent Methods in Stochastic Convex Optimization
Dec 27, 2022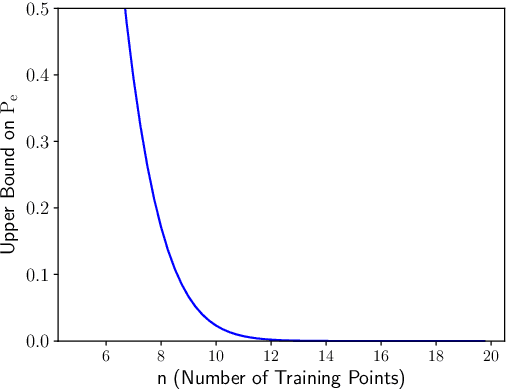
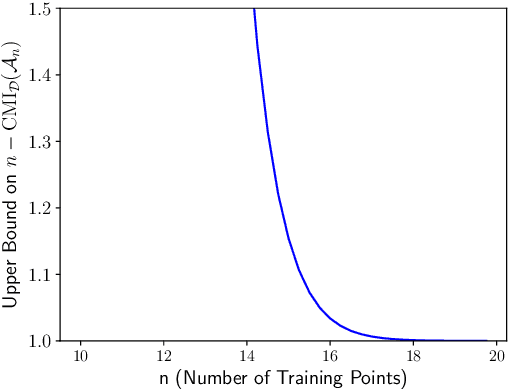
To date, no "information-theoretic" frameworks for reasoning about generalization error have been shown to establish minimax rates for gradient descent in the setting of stochastic convex optimization. In this work, we consider the prospect of establishing such rates via several existing information-theoretic frameworks: input-output mutual information bounds, conditional mutual information bounds and variants, PAC-Bayes bounds, and recent conditional variants thereof. We prove that none of these bounds are able to establish minimax rates. We then consider a common tactic employed in studying gradient methods, whereby the final iterate is corrupted by Gaussian noise, producing a noisy "surrogate" algorithm. We prove that minimax rates cannot be established via the analysis of such surrogates. Our results suggest that new ideas are required to analyze gradient descent using information-theoretic techniques.
An Information-Theoretic Analysis of Bayesian Reinforcement Learning
Jul 18, 2022Building on the framework introduced by Xu and Raginksy [1] for supervised learning problems, we study the best achievable performance for model-based Bayesian reinforcement learning problems. With this purpose, we define minimum Bayesian regret (MBR) as the difference between the maximum expected cumulative reward obtainable either by learning from the collected data or by knowing the environment and its dynamics. We specialize this definition to reinforcement learning problems modeled as Markov decision processes (MDPs) whose kernel parameters are unknown to the agent and whose uncertainty is expressed by a prior distribution. One method for deriving upper bounds on the MBR is presented and specific bounds based on the relative entropy and the Wasserstein distance are given. We then focus on two particular cases of MDPs, the multi-armed bandit problem (MAB) and the online optimization with partial feedback problem. For the latter problem, we show that our bounds can recover from below the current information-theoretic bounds by Russo and Van Roy [2].
Enforcing fairness in private federated learning via the modified method of differential multipliers
Sep 17, 2021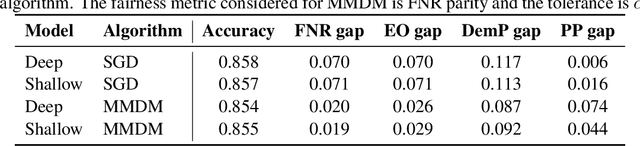
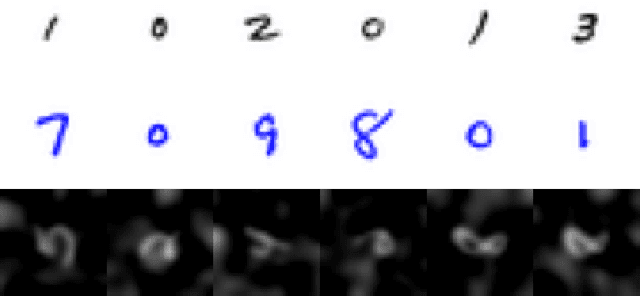
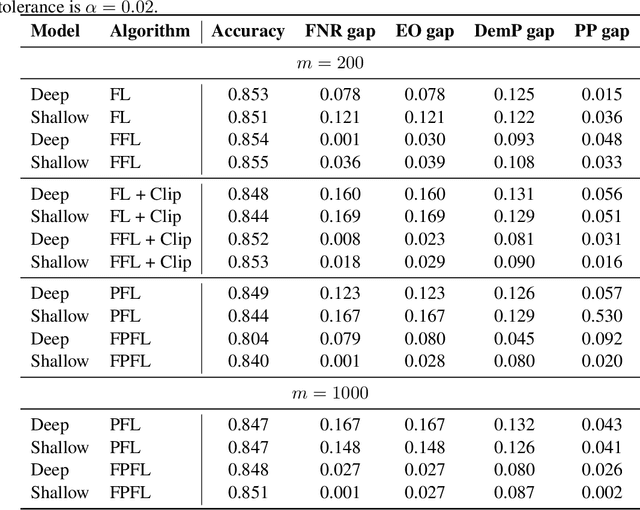
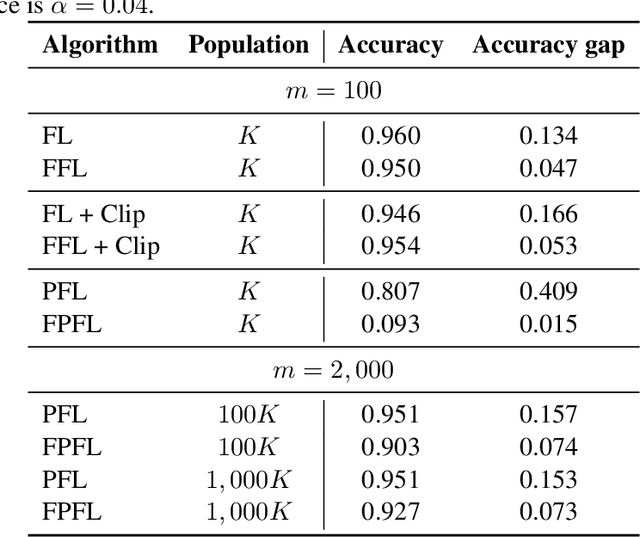
Federated learning with differential privacy, or private federated learning, provides a strategy to train machine learning models while respecting users' privacy. However, differential privacy can disproportionately degrade the performance of the models on under-represented groups, as these parts of the distribution are difficult to learn in the presence of noise. Existing approaches for enforcing fairness in machine learning models have considered the centralized setting, in which the algorithm has access to the users' data. This paper introduces an algorithm to enforce group fairness in private federated learning, where users' data does not leave their devices. First, the paper extends the modified method of differential multipliers to empirical risk minimization with fairness constraints, thus providing an algorithm to enforce fairness in the central setting. Then, this algorithm is extended to the private federated learning setting. The proposed algorithm, FPFL, is tested on a federated version of the Adult dataset and an "unfair" version of the FEMNIST dataset. The experiments on these datasets show how private federated learning accentuates unfairness in the trained models, and how FPFL is able to mitigate such unfairness.