 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetically-Augmented Discriminative Rescoring for Voice Search Error Correction
Jun 06, 2025End-to-end (E2E) Automatic Speech Recognition (ASR) models are trained using paired audio-text samples that are expensive to obtain, since high-quality ground-truth data requires human annotators. Voice search applications, such as digital media players, leverage ASR to allow users to search by voice as opposed to an on-screen keyboard. However, recent or infrequent movie titles may not be sufficiently represented in the E2E ASR system's training data, and hence, may suffer poor recognition. In this paper, we propose a phonetic correction system that consists of (a) a phonetic search based on the ASR model's output that generates phonetic alternatives that may not be considered by the E2E system, and (b) a rescorer component that combines the ASR model recognition and the phonetic alternatives, and select a final system output. We find that our approach improves word error rate between 4.4 and 7.6% relative on benchmarks of popular movie titles over a series of competitive baselines.
Towards a World-English Language Model for On-Device Virtual Assistants
Mar 27, 2024



Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them. Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English'' NNLM for on-device VAs. In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs {and enhance the multi-dialect baselines}. We find that adapter modules are more effective in modeling dialects than specializing entire sub-networks. Based on this insight and leveraging the design of our production models, we introduce a new architecture for World English NNLM that meets the accuracy, latency, and memory constraints of our single-dialect models.
Application-Agnostic Language Modeling for On-Device ASR
May 16, 2023On-device automatic speech recognition systems face several challenges compared to server-based systems. They have to meet stricter constraints in terms of speed, disk size and memory while maintaining the same accuracy. Often they have to serve several applications with different distributions at once, such as communicating with a virtual assistant and speech-to-text. The simplest solution to serve multiple applications is to build application-specific (language) models, but this leads to an increase in memory. Therefore, we explore different data- and architecture-driven language modeling approaches to build a single application-agnostic model. We propose two novel feed-forward architectures that find an optimal trade off between different on-device constraints. In comparison to the application-specific solution, one of our novel approaches reduces the disk size by half, while maintaining speed and accuracy of the original model.
On the long-term learning ability of LSTM LMs
Jun 16, 2021
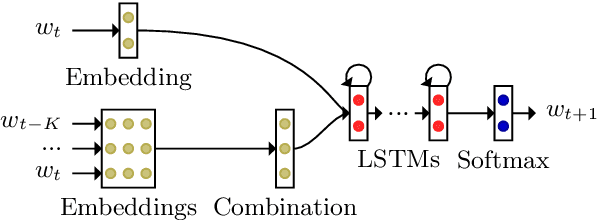
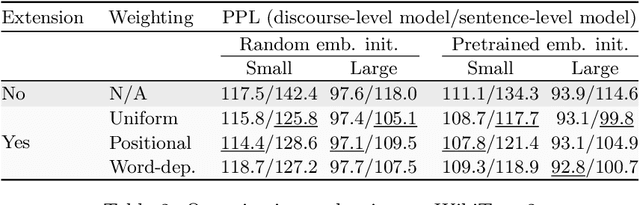

We inspect the long-term learning ability of Long Short-Term Memory language models (LSTM LMs) by evaluating a contextual extension based on the Continuous Bag-of-Words (CBOW) model for both sentence- and discourse-level LSTM LMs and by analyzing its performance. We evaluate on text and speech. Sentence-level models using the long-term contextual module perform comparably to vanilla discourse-level LSTM LMs. On the other hand, the extension does not provide gains for discourse-level models. These findings indicate that discourse-level LSTM LMs already rely on contextual information to perform long-term learning.
Error-driven Pruning of Language Models for Virtual Assistants
Feb 14, 2021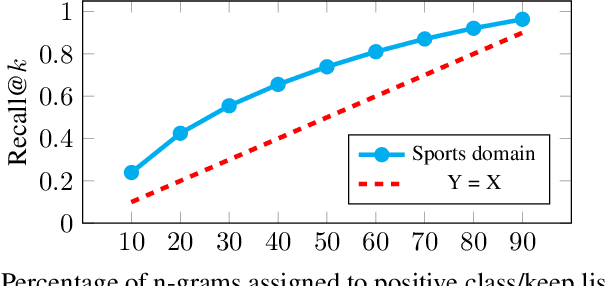
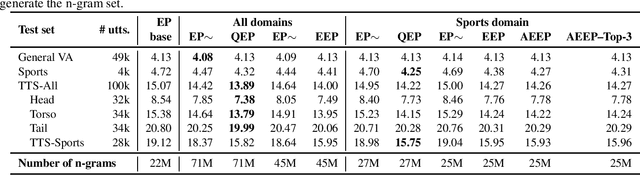
Language models (LMs) for virtual assistants (VAs) are typically trained on large amounts of data, resulting in prohibitively large models which require excessive memory and/or cannot be used to serve user requests in real-time. Entropy pruning results in smaller models but with significant degradation of effectiveness in the tail of the user request distribution. We customize entropy pruning by allowing for a keep list of infrequent n-grams that require a more relaxed pruning threshold, and propose three methods to construct the keep list. Each method has its own advantages and disadvantages with respect to LM size, ASR accuracy and cost of constructing the keep list. Our best LM gives 8% average Word Error Rate (WER) reduction on a targeted test set, but is 3 times larger than the baseline. We also propose discriminative methods to reduce the size of the LM while retaining the majority of the WER gains achieved by the largest LM.
Reverse Transfer Learning: Can Word Embeddings Trained for Different NLP Tasks Improve Neural Language Models?
Sep 09, 2019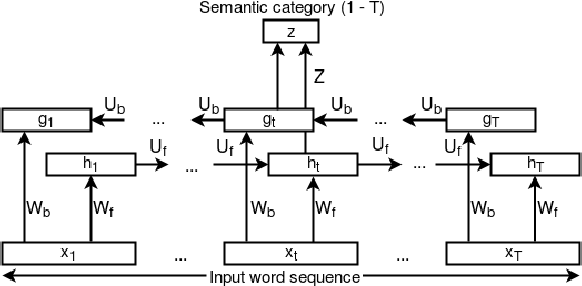
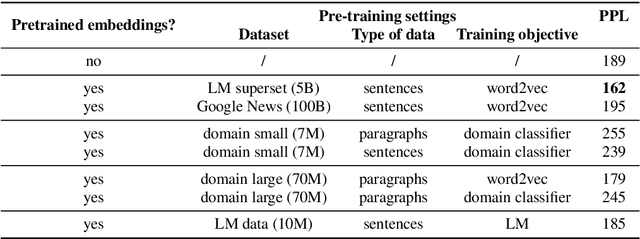
Natural language processing (NLP) tasks tend to suffer from a paucity of suitably annotated training data, hence the recent success of transfer learning across a wide variety of them. The typical recipe involves: (i) training a deep, possibly bidirectional, neural network with an objective related to language modeling, for which training data is plentiful; and (ii) using the trained network to derive contextual representations that are far richer than standard linear word embeddings such as word2vec, and thus result in important gains. In this work, we wonder whether the opposite perspective is also true: can contextual representations trained for different NLP tasks improve language modeling itself? Since language models (LMs) are predominantly locally optimized, other NLP tasks may help them make better predictions based on the entire semantic fabric of a document. We test the performance of several types of pre-trained embeddings in neural LMs, and we investigate whether it is possible to make the LM more aware of global semantic information through embeddings pre-trained with a domain classification model. Initial experiments suggest that as long as the proper objective criterion is used during training, pre-trained embeddings are likely to be beneficial for neural language modeling.
Information-Weighted Neural Cache Language Models for ASR
Sep 24, 2018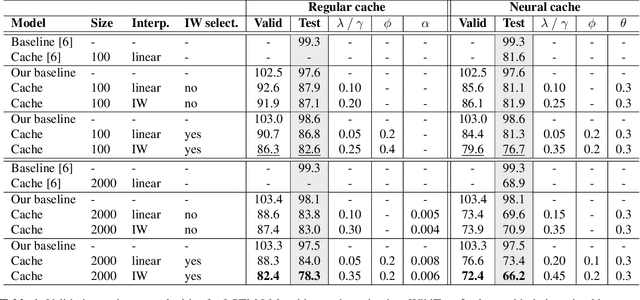
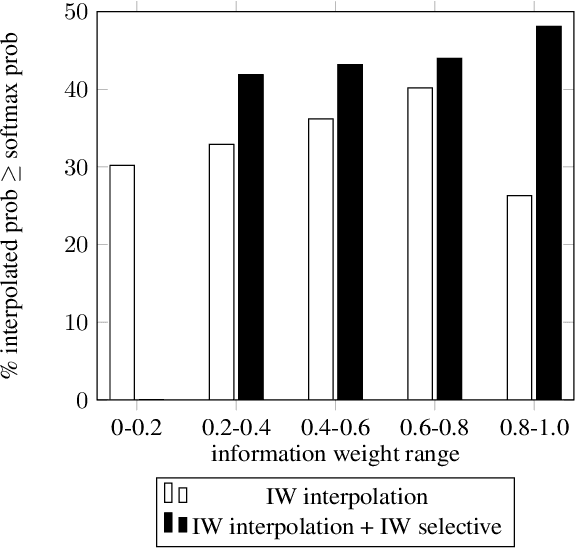
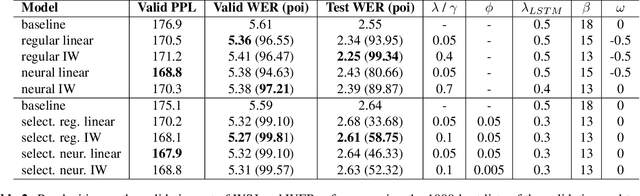
Neural cache language models (LMs) extend the idea of regular cache language models by making the cache probability dependent on the similarity between the current context and the context of the words in the cache. We make an extensive comparison of 'regular' cache models with neural cache models, both in terms of perplexity and WER after rescoring first-pass ASR results. Furthermore, we propose two extensions to this neural cache model that make use of the content value/information weight of the word: firstly, combining the cache probability and LM probability with an information-weighted interpolation and secondly, selectively adding only content words to the cache. We obtain a 29.9%/32.1% (validation/test set) relative improvement in perplexity with respect to a baseline LSTM LM on the WikiText-2 dataset, outperforming previous work on neural cache LMs. Additionally, we observe significant WER reductions with respect to the baseline model on the WSJ ASR task.
State Gradients for RNN Memory Analysis
Jun 18, 2018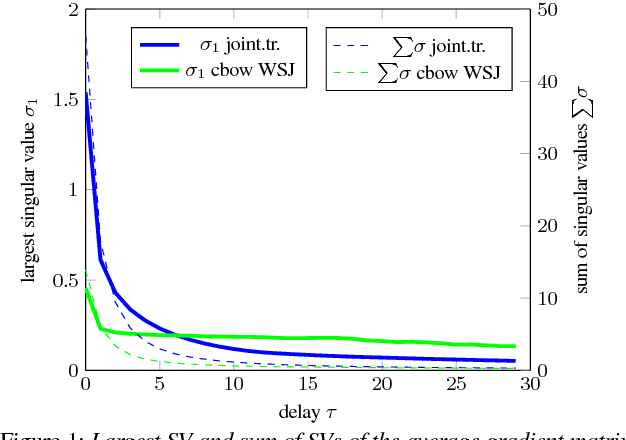
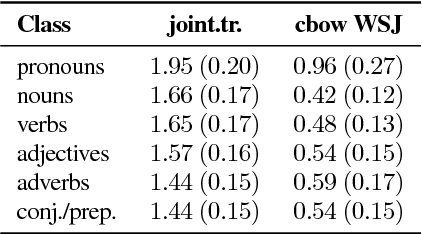
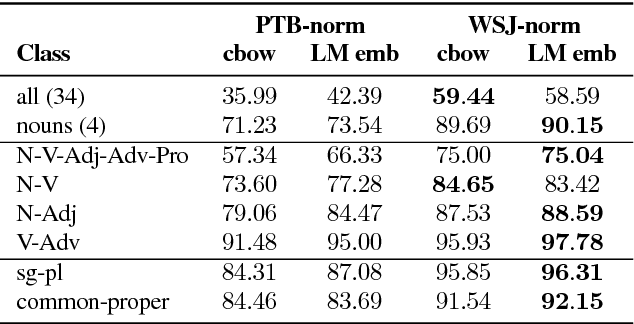
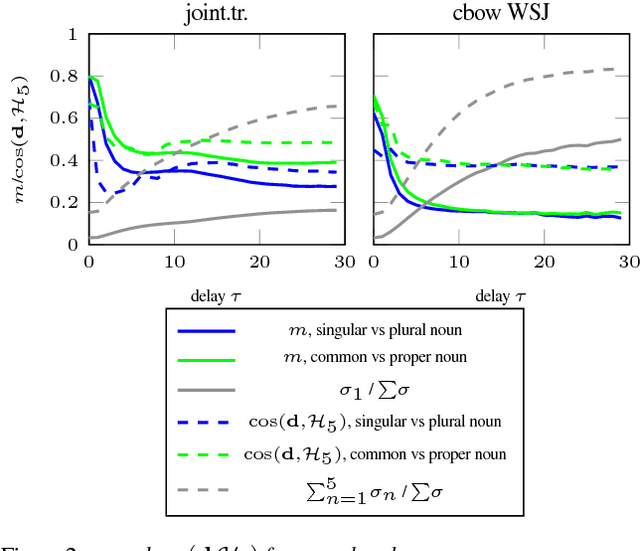
We present a framework for analyzing what the state in RNNs remembers from its input embeddings. Our approach is inspired by backpropagation, in the sense that we compute the gradients of the states with respect to the input embeddings. The gradient matrix is decomposed with Singular Value Decomposition to analyze which directions in the embedding space are best transferred to the hidden state space, characterized by the largest singular values. We apply our approach to LSTM language models and investigate to what extent and for how long certain classes of words are remembered on average for a certain corpus. Additionally, the extent to which a specific property or relationship is remembered by the RNN can be tracked by comparing a vector characterizing that property with the direction(s) in embedding space that are best preserved in hidden state space.
Language Models of Spoken Dutch
Sep 12, 2017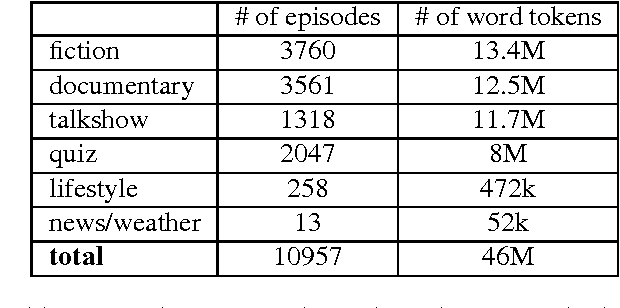
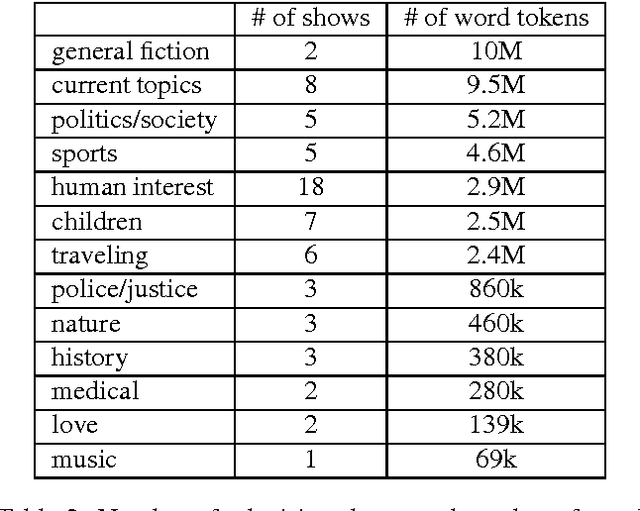
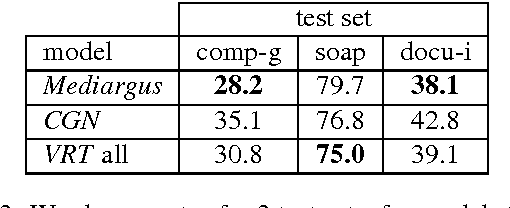
In Flanders, all TV shows are subtitled. However, the process of subtitling is a very time-consuming one and can be sped up by providing the output of a speech recognizer run on the audio of the TV show, prior to the subtitling. Naturally, this speech recognition will perform much better if the employed language model is adapted to the register and the topic of the program. We present several language models trained on subtitles of television shows provided by the Flemish public-service broadcaster VRT. This data was gathered in the context of the project STON which has as purpose to facilitate the process of subtitling TV shows. One model is trained on all available data (46M word tokens), but we also trained models on a specific type of TV show or domain/topic. Language models of spoken language are quite rare due to the lack of training data. The size of this corpus is relatively large for a corpus of spoken language (compare with e.g. CGN which has 9M words), but still rather small for a language model. Thus, in practice it is advised to interpolate these models with a large background language model trained on written language. The models can be freely downloaded on http://www.esat.kuleuven.be/psi/spraak/downloads/.
Character-Word LSTM Language Models
Apr 10, 2017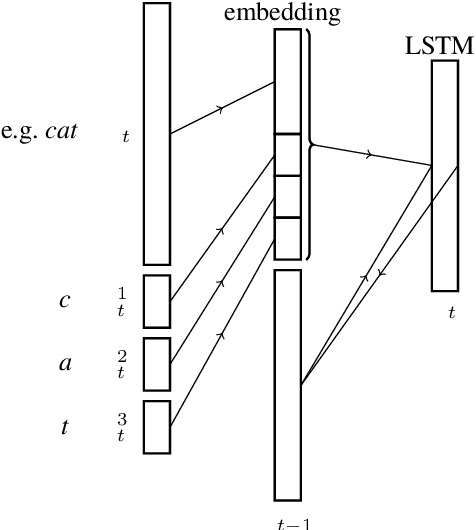
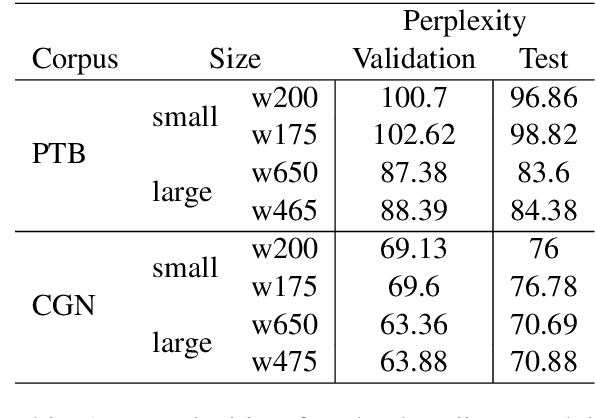
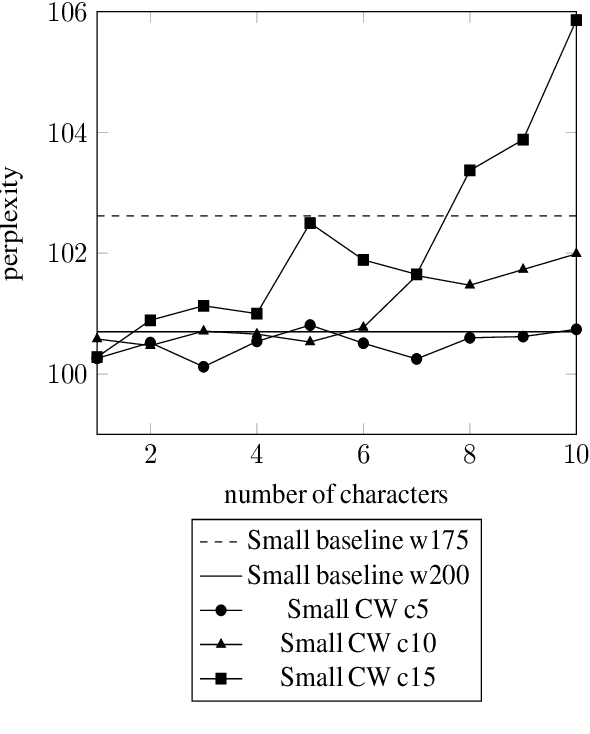
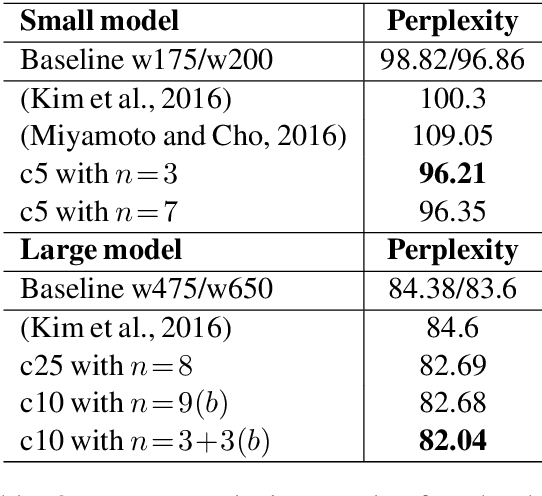
We present a Character-Word Long Short-Term Memory Language Model which both reduces the perplexity with respect to a baseline word-level language model and reduces the number of parameters of the model. Character information can reveal structural (dis)similarities between words and can even be used when a word is out-of-vocabulary, thus improving the modeling of infrequent and unknown words. By concatenating word and character embeddings, we achieve up to 2.77% relative improvement on English compared to a baseline model with a similar amount of parameters and 4.57% on Dutch. Moreover, we also outperform baseline word-level models with a larger number of parameters.