 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of visual assistance for automated audio captioning
Nov 18, 2022We study the impact of visual assistance for automated audio captioning. Utilizing multi-encoder transformer architectures, which have previously been employed to introduce vision-related information in the context of sound event detection, we analyze the usefulness of incorporating a variety of pretrained features. We perform experiments on a YouTube-based audiovisual data set and investigate the effect of applying the considered transfer learning technique in terms of a variety of captioning metrics. We find that only one of the considered kinds of pretrained features provides consistent improvements, while the others do not provide any noteworthy gains at all. Interestingly, the outcomes of prior research efforts indicate that the exact opposite is true in the case of sound event detection, leading us to conclude that the optimal choice of visual embeddings is strongly dependent on the task at hand. More specifically, visual features focusing on semantics appear appropriate in the context of automated audio captioning, while for sound event detection, time information seems to be more important.
Multi-Source Transformer Architectures for Audiovisual Scene Classification
Oct 18, 2022
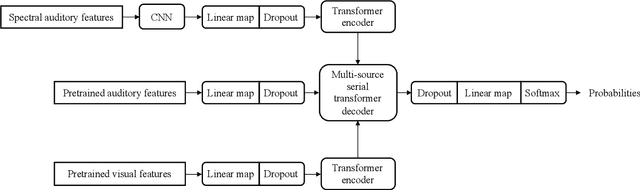
In this technical report, the systems we submitted for subtask 1B of the DCASE 2021 challenge, regarding audiovisual scene classification, are described in detail. They are essentially multi-source transformers employing a combination of auditory and visual features to make predictions. These models are evaluated utilizing the macro-averaged multi-class cross-entropy and accuracy metrics. In terms of the macro-averaged multi-class cross-entropy, our best model achieved a score of 0.620 on the validation data. This is slightly better than the performance of the baseline system (0.658). With regard to the accuracy measure, our best model achieved a score of 77.1\% on the validation data, which is about the same as the performance obtained by the baseline system (77.0\%).
Optimizing Temporal Resolution Of Convolutional Recurrent Neural Networks For Sound Event Detection
Oct 18, 2022
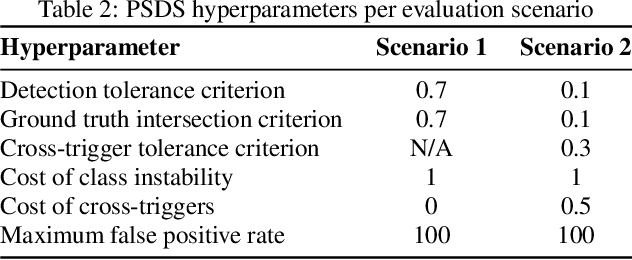
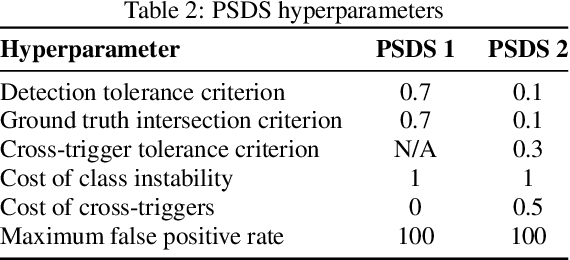
In this technical report, the systems we submitted for subtask 4 of the DCASE 2021 challenge, regarding sound event detection, are described in detail. These models are closely related to the baseline provided for this problem, as they are essentially convolutional recurrent neural networks trained in a mean teacher setting to deal with the heterogeneous annotation of the supplied data. However, the time resolution of the predictions was adapted to deal with the fact that these systems are evaluated using two intersection-based metrics involving different needs in terms of temporal localization. This was done by optimizing the pooling operations. For the first of the defined evaluation scenarios, imposing relatively strict requirements on the temporal localization accuracy, our best model achieved a PSDS score of 0.3609 on the validation data. This is only marginally better than the performance obtained by the baseline system (0.342): The amount of pooling in the baseline network already turned out to be optimal, and thus, no substantial changes were made, explaining this result. For the second evaluation scenario, imposing relatively lax restrictions on the localization accuracy, our best-performing system achieved a PSDS score of 0.7312 on the validation data. This is significantly better than the performance obtained by the baseline model (0.527), which can effectively be attributed to the changes that were applied to the pooling operations of the network.
Impact of temporal resolution on convolutional recurrent networks for audio tagging and sound event detection
Sep 27, 2022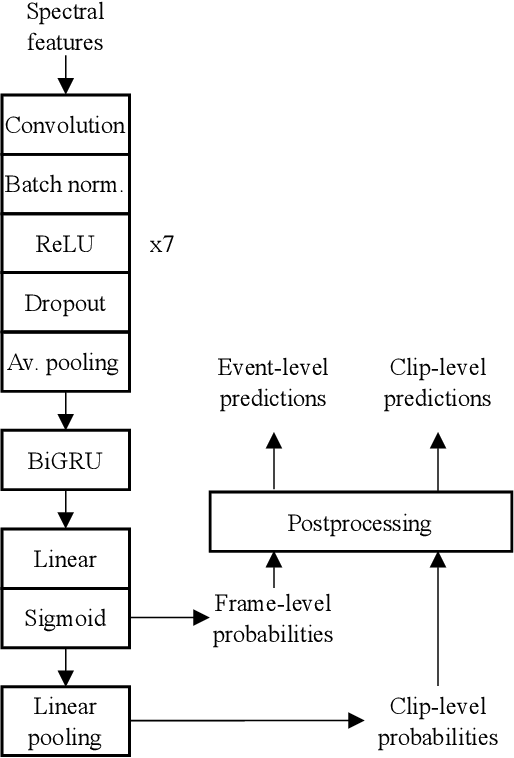

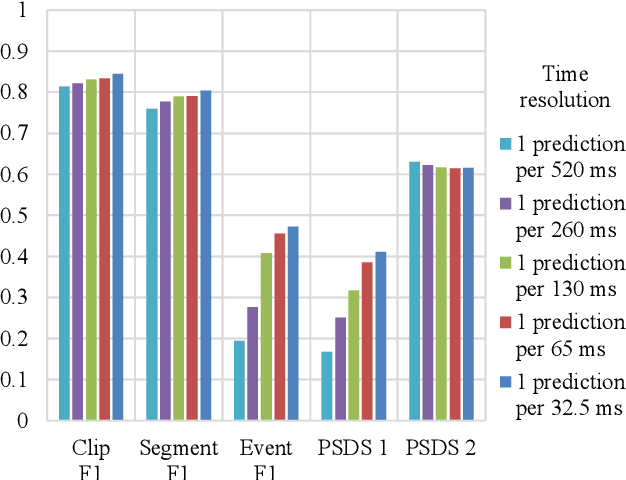
Many state-of-the-art systems for audio tagging and sound event detection employ convolutional recurrent neural architectures. Typically, they are trained in a mean teacher setting to deal with the heterogeneous annotation of the available data. In this work, we present a thorough analysis of how changing the temporal resolution of these convolutional recurrent neural networks - which can be done by simply adapting their pooling operations - impacts their performance. By using a variety of evaluation metrics, we investigate the effects of adapting this design parameter under several sound recognition scenarios involving different needs in terms of temporal localization.
Multi-encoder attention-based architectures for sound recognition with partial visual assistance
Sep 26, 2022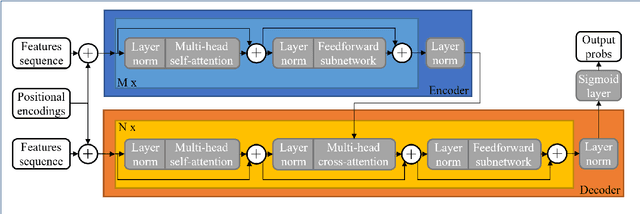

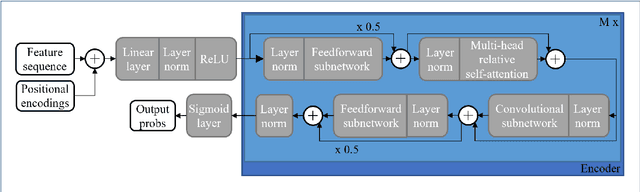
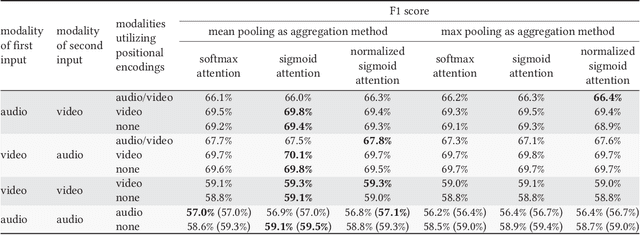
Large-scale sound recognition data sets typically consist of acoustic recordings obtained from multimedia libraries. As a consequence, modalities other than audio can often be exploited to improve the outputs of models designed for associated tasks. Frequently, however, not all contents are available for all samples of such a collection: For example, the original material may have been removed from the source platform at some point, and therefore, non-auditory features can no longer be acquired. We demonstrate that a multi-encoder framework can be employed to deal with this issue by applying this method to attention-based deep learning systems, which are currently part of the state of the art in the domain of sound recognition. More specifically, we show that the proposed model extension can successfully be utilized to incorporate partially available visual information into the operational procedures of such networks, which normally only use auditory features during training and inference. Experimentally, we verify that the considered approach leads to improved predictions in a number of evaluation scenarios pertaining to audio tagging and sound event detection. Additionally, we scrutinize some properties and limitations of the presented technique.
On the long-term learning ability of LSTM LMs
Jun 16, 2021
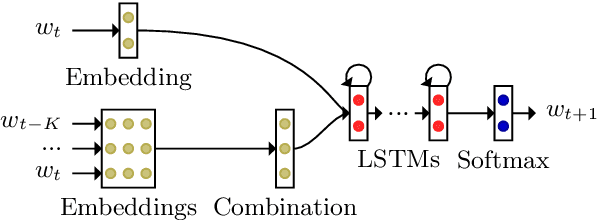
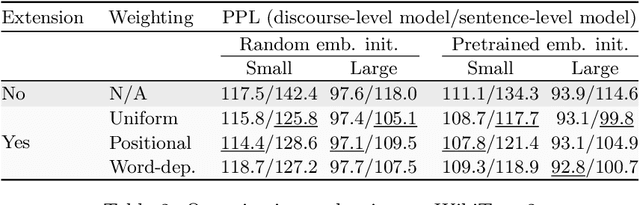

We inspect the long-term learning ability of Long Short-Term Memory language models (LSTM LMs) by evaluating a contextual extension based on the Continuous Bag-of-Words (CBOW) model for both sentence- and discourse-level LSTM LMs and by analyzing its performance. We evaluate on text and speech. Sentence-level models using the long-term contextual module perform comparably to vanilla discourse-level LSTM LMs. On the other hand, the extension does not provide gains for discourse-level models. These findings indicate that discourse-level LSTM LMs already rely on contextual information to perform long-term learning.
Audiovisual transfer learning for audio tagging and sound event detection
Jun 09, 2021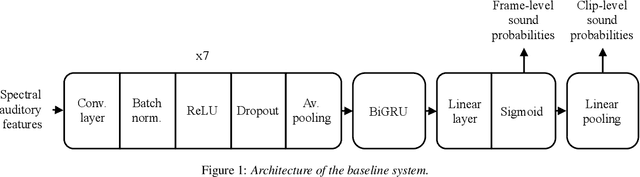
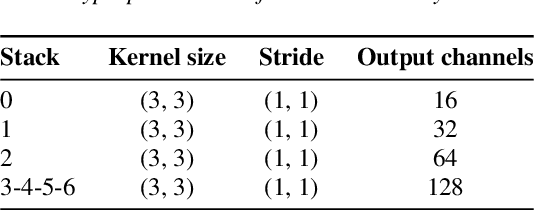
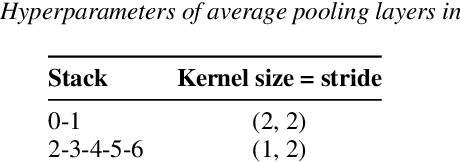
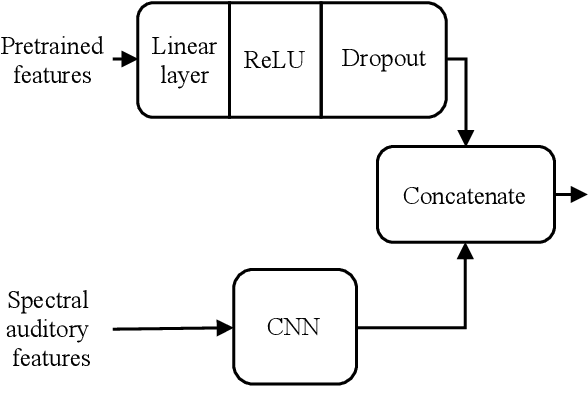
We study the merit of transfer learning for two sound recognition problems, i.e., audio tagging and sound event detection. Employing feature fusion, we adapt a baseline system utilizing only spectral acoustic inputs to also make use of pretrained auditory and visual features, extracted from networks built for different tasks and trained with external data. We perform experiments with these modified models on an audiovisual multi-label data set, of which the training partition contains a large number of unlabeled samples and a smaller amount of clips with weak annotations, indicating the clip-level presence of 10 sound categories without specifying the temporal boundaries of the active auditory events. For clip-based audio tagging, this transfer learning method grants marked improvements. Addition of the visual modality on top of audio also proves to be advantageous in this context. When it comes to generating transcriptions of audio recordings, the benefit of pretrained features depends on the requested temporal resolution: for coarse-grained sound event detection, their utility remains notable. But when more fine-grained predictions are required, performance gains are strongly reduced due to a mismatch between the problem at hand and the goals of the models from which the pretrained vectors were obtained.
Audiovisual Transformer Architectures for Large-Scale Classification and Synchronization of Weakly Labeled Audio Events
Dec 02, 2019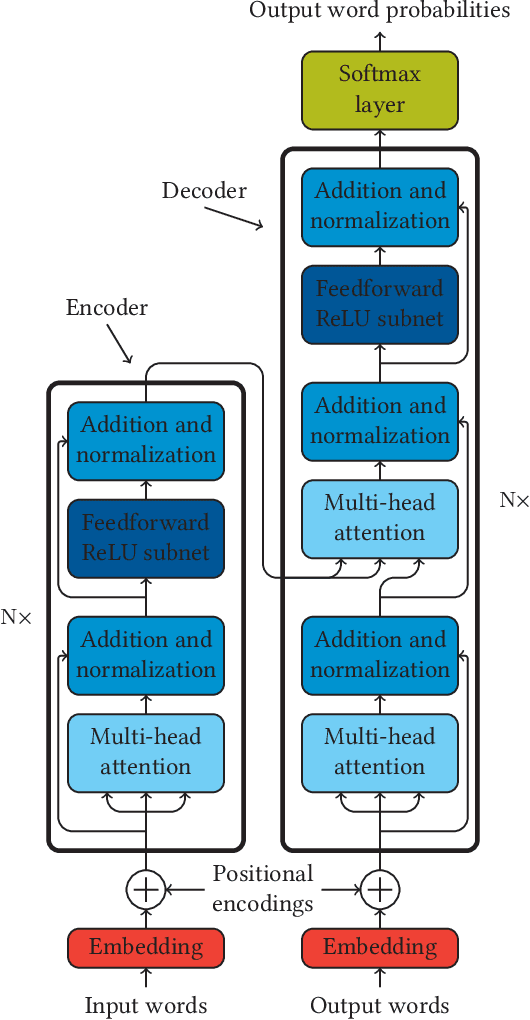
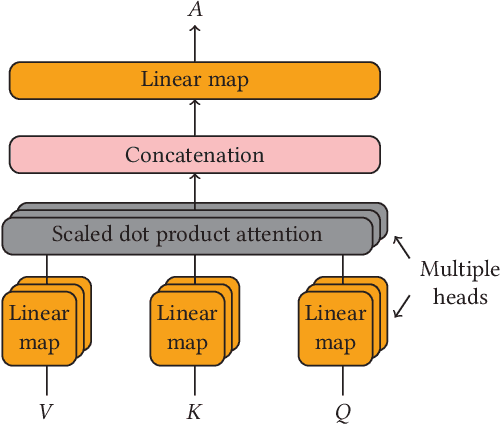

We tackle the task of environmental event classification by drawing inspiration from the transformer neural network architecture used in machine translation. We modify this attention-based feedforward structure in such a way that allows the resulting model to use audio as well as video to compute sound event predictions. We perform extensive experiments with these adapted transformers on an audiovisual data set, obtained by appending relevant visual information to an existing large-scale weakly labeled audio collection. The employed multi-label data contains clip-level annotation indicating the presence or absence of 17 classes of environmental sounds, and does not include temporal information. We show that the proposed modified transformers strongly improve upon previously introduced models and in fact achieve state-of-the-art results. We also make a compelling case for devoting more attention to research in multimodal audiovisual classification by proving the usefulness of visual information for the task at hand,namely audio event recognition. In addition, we visualize internal attention patterns of the audiovisual transformers and in doing so demonstrate their potential for performing multimodal synchronization.