 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021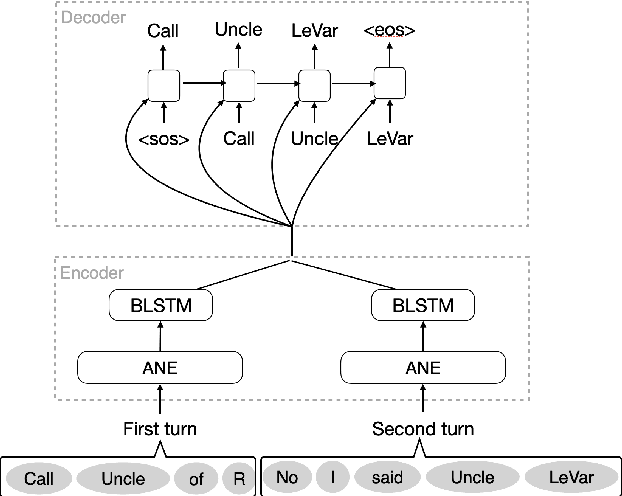
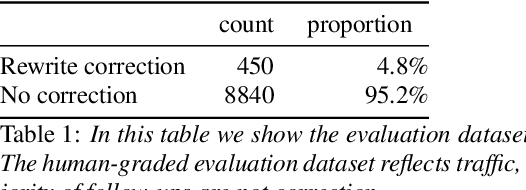
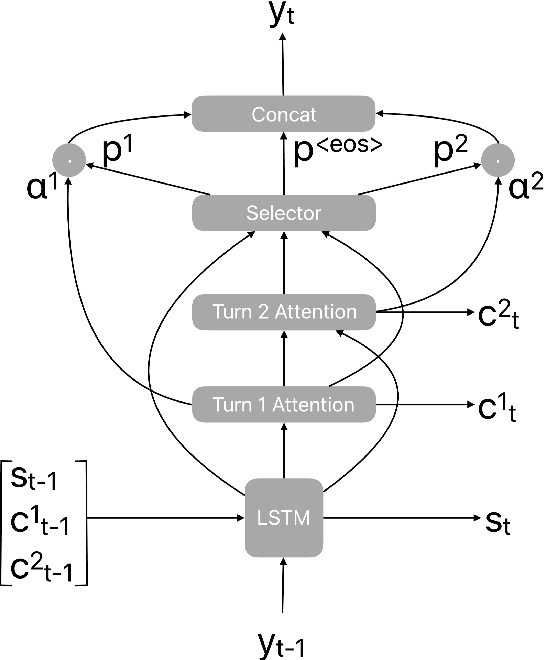

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.
On the long-term learning ability of LSTM LMs
Jun 16, 2021
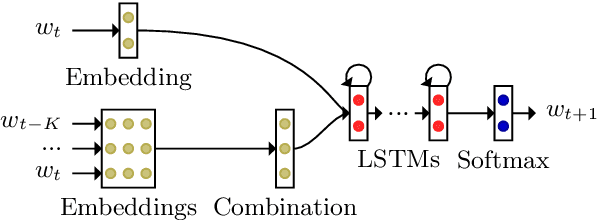
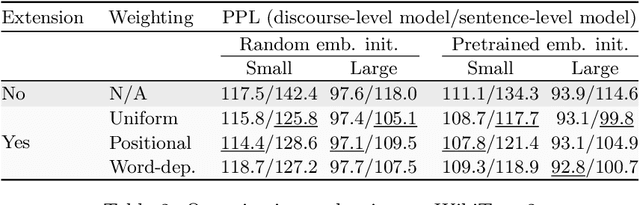

We inspect the long-term learning ability of Long Short-Term Memory language models (LSTM LMs) by evaluating a contextual extension based on the Continuous Bag-of-Words (CBOW) model for both sentence- and discourse-level LSTM LMs and by analyzing its performance. We evaluate on text and speech. Sentence-level models using the long-term contextual module perform comparably to vanilla discourse-level LSTM LMs. On the other hand, the extension does not provide gains for discourse-level models. These findings indicate that discourse-level LSTM LMs already rely on contextual information to perform long-term learning.
Information-Weighted Neural Cache Language Models for ASR
Sep 24, 2018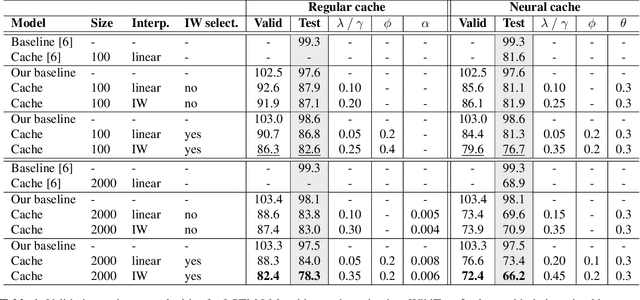
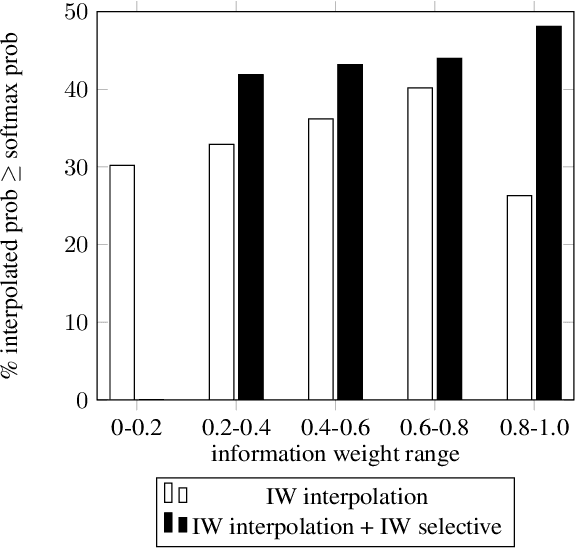
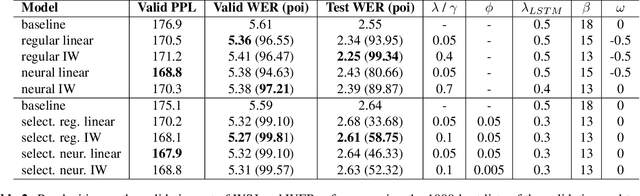
Neural cache language models (LMs) extend the idea of regular cache language models by making the cache probability dependent on the similarity between the current context and the context of the words in the cache. We make an extensive comparison of 'regular' cache models with neural cache models, both in terms of perplexity and WER after rescoring first-pass ASR results. Furthermore, we propose two extensions to this neural cache model that make use of the content value/information weight of the word: firstly, combining the cache probability and LM probability with an information-weighted interpolation and secondly, selectively adding only content words to the cache. We obtain a 29.9%/32.1% (validation/test set) relative improvement in perplexity with respect to a baseline LSTM LM on the WikiText-2 dataset, outperforming previous work on neural cache LMs. Additionally, we observe significant WER reductions with respect to the baseline model on the WSJ ASR task.
Language Models of Spoken Dutch
Sep 12, 2017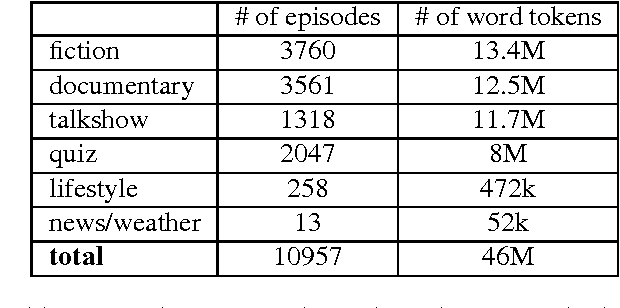
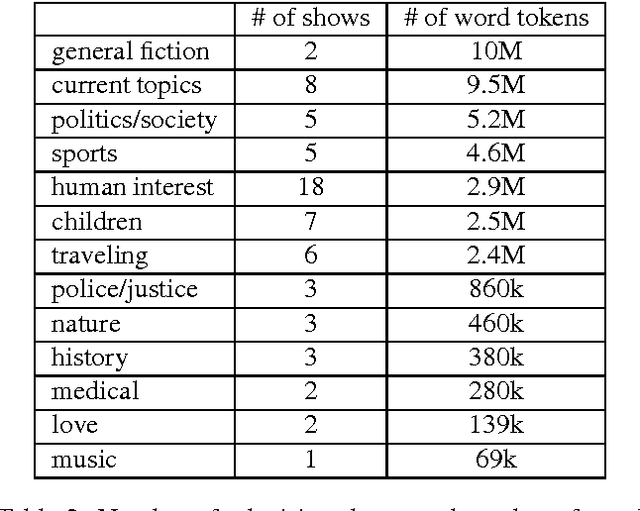
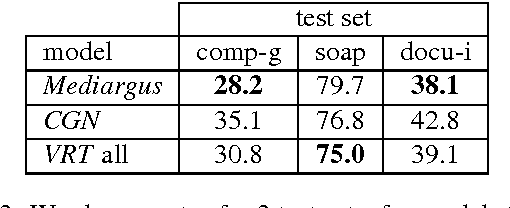
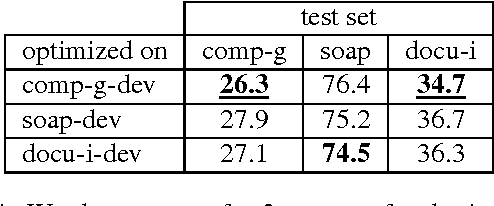
In Flanders, all TV shows are subtitled. However, the process of subtitling is a very time-consuming one and can be sped up by providing the output of a speech recognizer run on the audio of the TV show, prior to the subtitling. Naturally, this speech recognition will perform much better if the employed language model is adapted to the register and the topic of the program. We present several language models trained on subtitles of television shows provided by the Flemish public-service broadcaster VRT. This data was gathered in the context of the project STON which has as purpose to facilitate the process of subtitling TV shows. One model is trained on all available data (46M word tokens), but we also trained models on a specific type of TV show or domain/topic. Language models of spoken language are quite rare due to the lack of training data. The size of this corpus is relatively large for a corpus of spoken language (compare with e.g. CGN which has 9M words), but still rather small for a language model. Thus, in practice it is advised to interpolate these models with a large background language model trained on written language. The models can be freely downloaded on http://www.esat.kuleuven.be/psi/spraak/downloads/.
Character-Word LSTM Language Models
Apr 10, 2017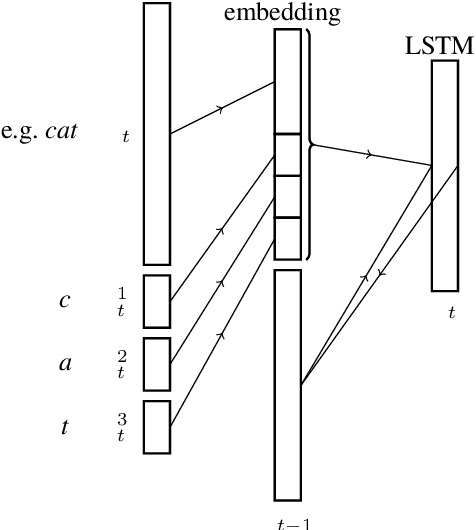
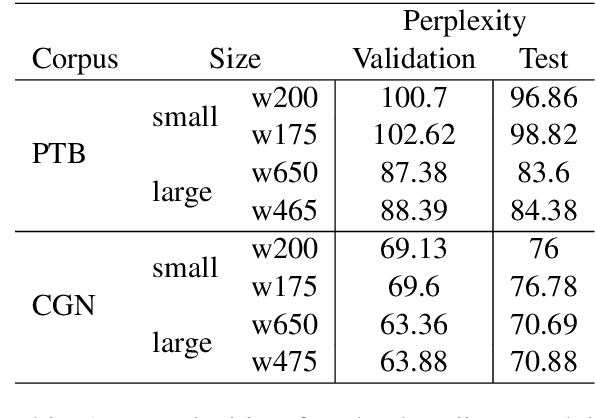
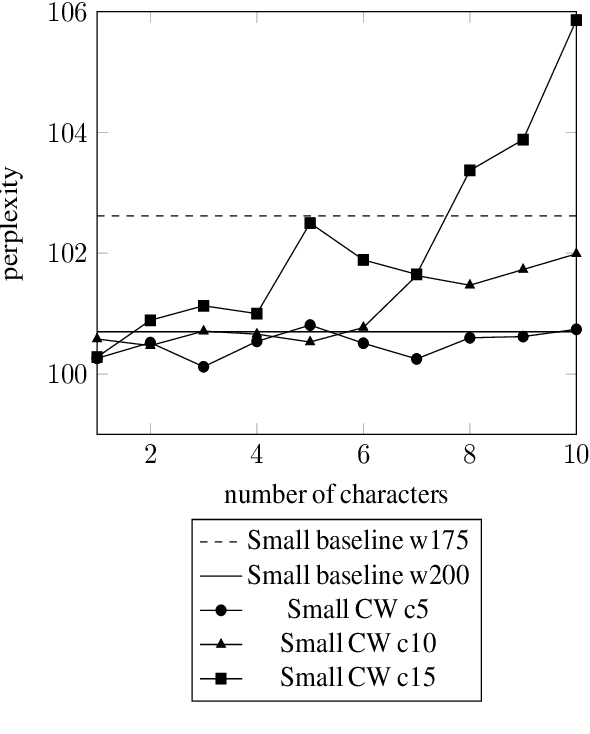
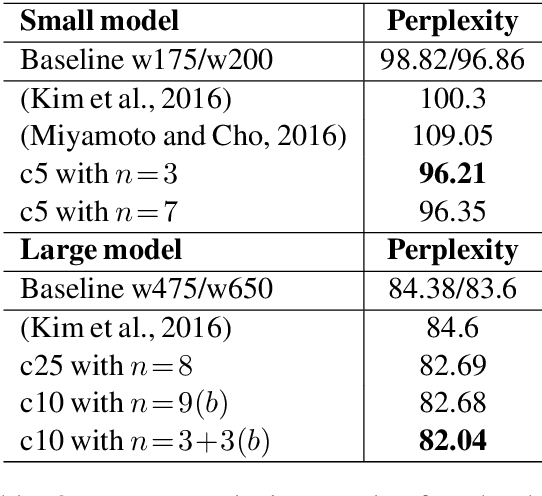
We present a Character-Word Long Short-Term Memory Language Model which both reduces the perplexity with respect to a baseline word-level language model and reduces the number of parameters of the model. Character information can reveal structural (dis)similarities between words and can even be used when a word is out-of-vocabulary, thus improving the modeling of infrequent and unknown words. By concatenating word and character embeddings, we achieve up to 2.77% relative improvement on English compared to a baseline model with a similar amount of parameters and 4.57% on Dutch. Moreover, we also outperform baseline word-level models with a larger number of parameters.
Skip-gram Language Modeling Using Sparse Non-negative Matrix Probability Estimation
Jun 26, 2015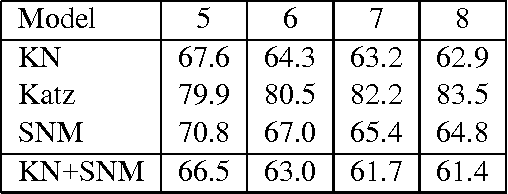

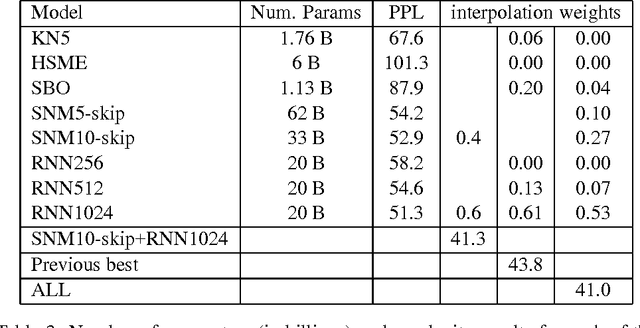

We present a novel family of language model (LM) estimation techniques named Sparse Non-negative Matrix (SNM) estimation. A first set of experiments empirically evaluating it on the One Billion Word Benchmark shows that SNM $n$-gram LMs perform almost as well as the well-established Kneser-Ney (KN) models. When using skip-gram features the models are able to match the state-of-the-art recurrent neural network (RNN) LMs; combining the two modeling techniques yields the best known result on the benchmark. The computational advantages of SNM over both maximum entropy and RNN LM estimation are probably its main strength, promising an approach that has the same flexibility in combining arbitrary features effectively and yet should scale to very large amounts of data as gracefully as $n$-gram LMs do.