 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models of Spoken Dutch
Paper and Code
Sep 12, 2017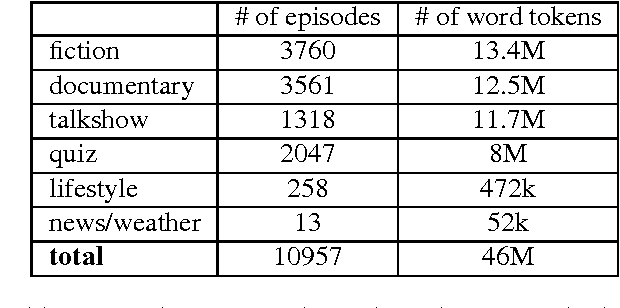
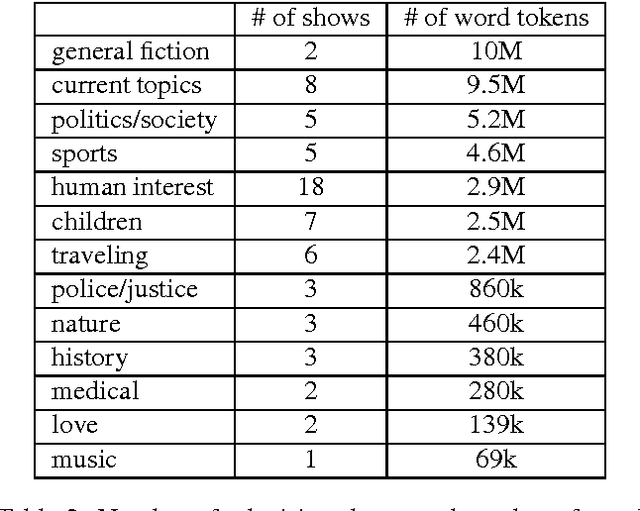
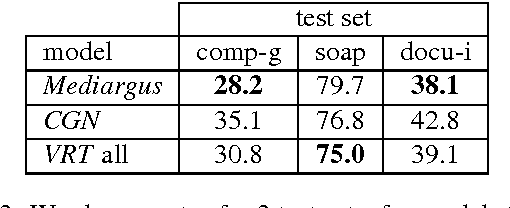
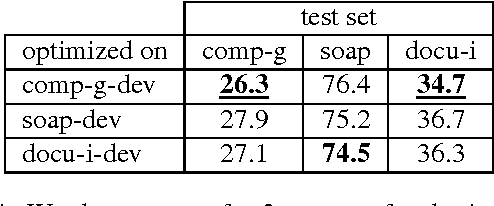
In Flanders, all TV shows are subtitled. However, the process of subtitling is a very time-consuming one and can be sped up by providing the output of a speech recognizer run on the audio of the TV show, prior to the subtitling. Naturally, this speech recognition will perform much better if the employed language model is adapted to the register and the topic of the program. We present several language models trained on subtitles of television shows provided by the Flemish public-service broadcaster VRT. This data was gathered in the context of the project STON which has as purpose to facilitate the process of subtitling TV shows. One model is trained on all available data (46M word tokens), but we also trained models on a specific type of TV show or domain/topic. Language models of spoken language are quite rare due to the lack of training data. The size of this corpus is relatively large for a corpus of spoken language (compare with e.g. CGN which has 9M words), but still rather small for a language model. Thus, in practice it is advised to interpolate these models with a large background language model trained on written language. The models can be freely downloaded on http://www.esat.kuleuven.be/psi/spraak/downloads/.