 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Temporal Resolution Of Convolutional Recurrent Neural Networks For Sound Event Detection
Paper and Code
Oct 18, 2022
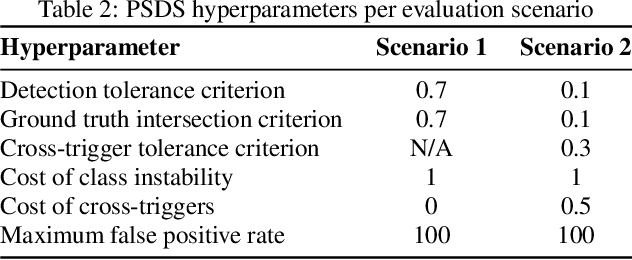
In this technical report, the systems we submitted for subtask 4 of the DCASE 2021 challenge, regarding sound event detection, are described in detail. These models are closely related to the baseline provided for this problem, as they are essentially convolutional recurrent neural networks trained in a mean teacher setting to deal with the heterogeneous annotation of the supplied data. However, the time resolution of the predictions was adapted to deal with the fact that these systems are evaluated using two intersection-based metrics involving different needs in terms of temporal localization. This was done by optimizing the pooling operations. For the first of the defined evaluation scenarios, imposing relatively strict requirements on the temporal localization accuracy, our best model achieved a PSDS score of 0.3609 on the validation data. This is only marginally better than the performance obtained by the baseline system (0.342): The amount of pooling in the baseline network already turned out to be optimal, and thus, no substantial changes were made, explaining this result. For the second evaluation scenario, imposing relatively lax restrictions on the localization accuracy, our best-performing system achieved a PSDS score of 0.7312 on the validation data. This is significantly better than the performance obtained by the baseline model (0.527), which can effectively be attributed to the changes that were applied to the pooling operations of the network.