 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Transformer Architectures for Large-Scale Classification and Synchronization of Weakly Labeled Audio Events
Paper and Code
Dec 02, 2019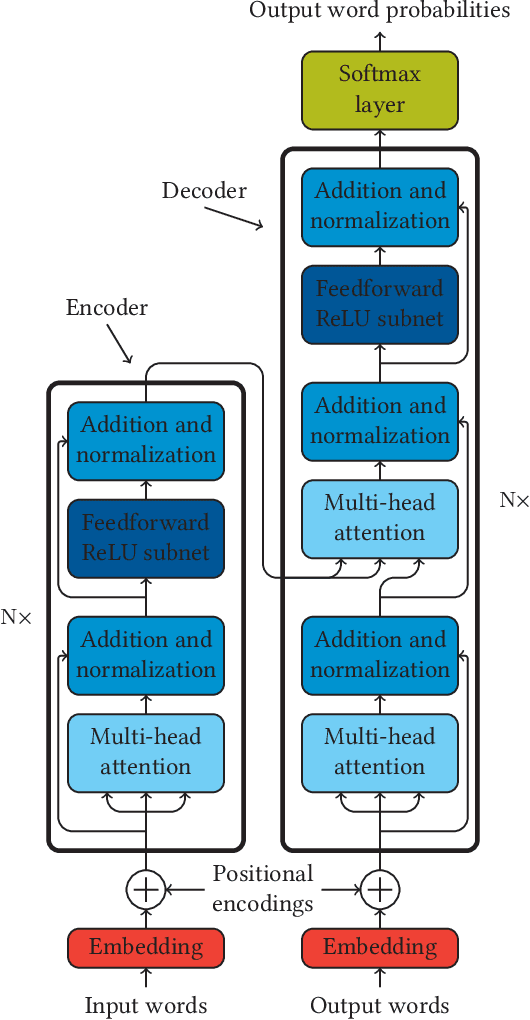
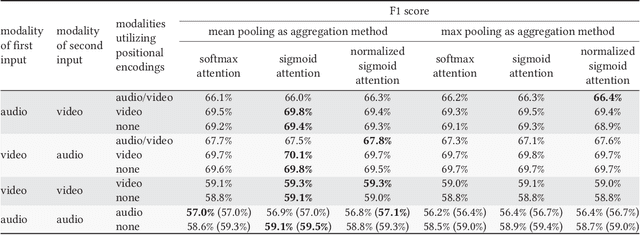
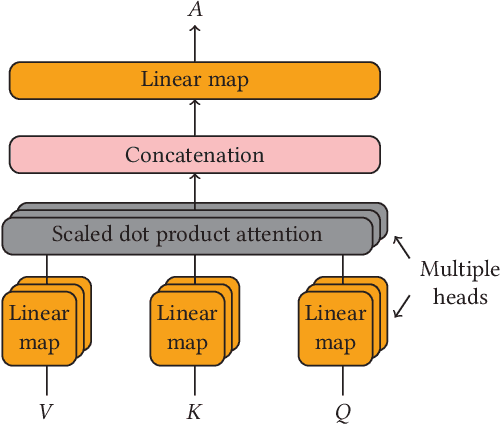

We tackle the task of environmental event classification by drawing inspiration from the transformer neural network architecture used in machine translation. We modify this attention-based feedforward structure in such a way that allows the resulting model to use audio as well as video to compute sound event predictions. We perform extensive experiments with these adapted transformers on an audiovisual data set, obtained by appending relevant visual information to an existing large-scale weakly labeled audio collection. The employed multi-label data contains clip-level annotation indicating the presence or absence of 17 classes of environmental sounds, and does not include temporal information. We show that the proposed modified transformers strongly improve upon previously introduced models and in fact achieve state-of-the-art results. We also make a compelling case for devoting more attention to research in multimodal audiovisual classification by proving the usefulness of visual information for the task at hand,namely audio event recognition. In addition, we visualize internal attention patterns of the audiovisual transformers and in doing so demonstrate their potential for performing multimodal synchronization.