Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of temporal resolution on convolutional recurrent networks for audio tagging and sound event detection
Paper and Code
Sep 27, 2022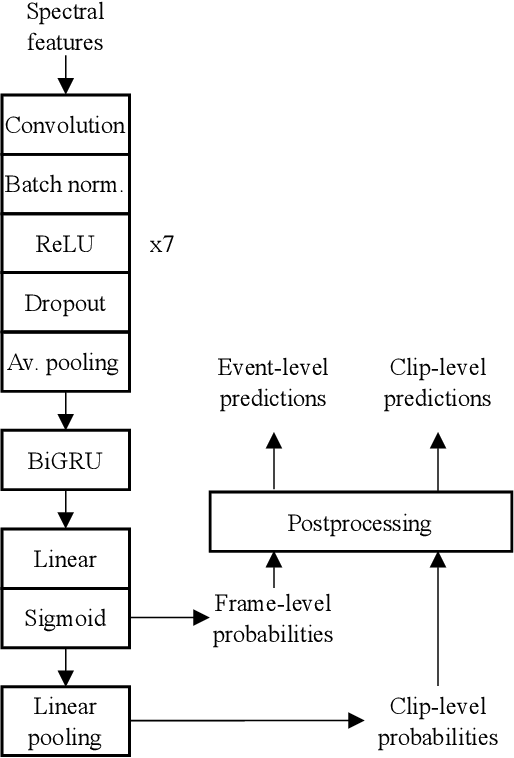

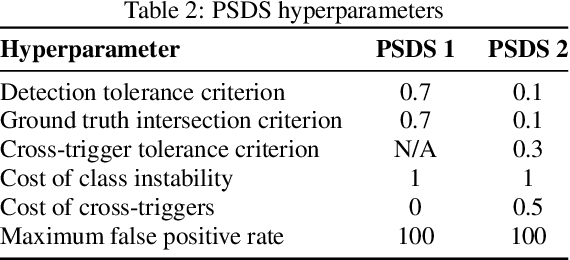
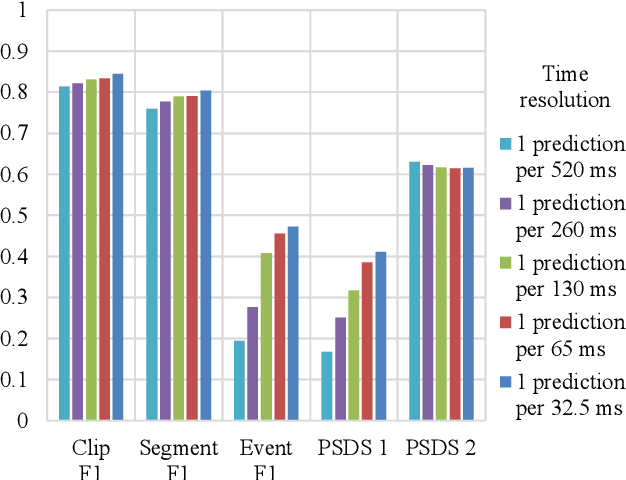
Many state-of-the-art systems for audio tagging and sound event detection employ convolutional recurrent neural architectures. Typically, they are trained in a mean teacher setting to deal with the heterogeneous annotation of the available data. In this work, we present a thorough analysis of how changing the temporal resolution of these convolutional recurrent neural networks - which can be done by simply adapting their pooling operations - impacts their performance. By using a variety of evaluation metrics, we investigate the effects of adapting this design parameter under several sound recognition scenarios involving different needs in terms of temporal localization.
* Submitted to DCASE 2022 Workshop
View paper on