 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-encoder attention-based architectures for sound recognition with partial visual assistance
Paper and Code
Sep 26, 2022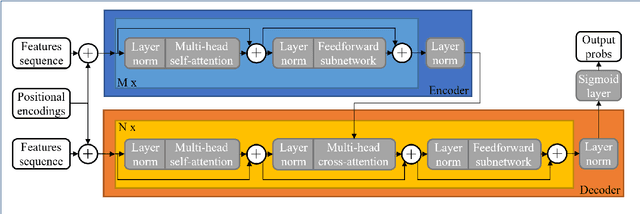

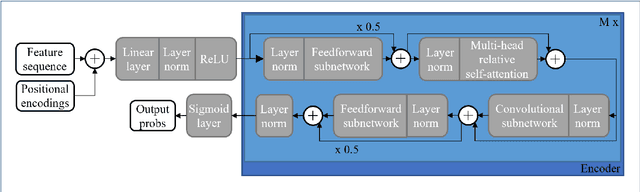
Large-scale sound recognition data sets typically consist of acoustic recordings obtained from multimedia libraries. As a consequence, modalities other than audio can often be exploited to improve the outputs of models designed for associated tasks. Frequently, however, not all contents are available for all samples of such a collection: For example, the original material may have been removed from the source platform at some point, and therefore, non-auditory features can no longer be acquired. We demonstrate that a multi-encoder framework can be employed to deal with this issue by applying this method to attention-based deep learning systems, which are currently part of the state of the art in the domain of sound recognition. More specifically, we show that the proposed model extension can successfully be utilized to incorporate partially available visual information into the operational procedures of such networks, which normally only use auditory features during training and inference. Experimentally, we verify that the considered approach leads to improved predictions in a number of evaluation scenarios pertaining to audio tagging and sound event detection. Additionally, we scrutinize some properties and limitations of the presented technique.