 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Transformer Architectures for Audiovisual Scene Classification
Paper and Code
Oct 18, 2022
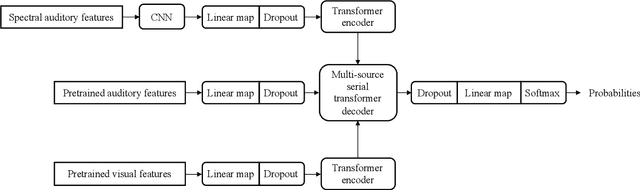
In this technical report, the systems we submitted for subtask 1B of the DCASE 2021 challenge, regarding audiovisual scene classification, are described in detail. They are essentially multi-source transformers employing a combination of auditory and visual features to make predictions. These models are evaluated utilizing the macro-averaged multi-class cross-entropy and accuracy metrics. In terms of the macro-averaged multi-class cross-entropy, our best model achieved a score of 0.620 on the validation data. This is slightly better than the performance of the baseline system (0.658). With regard to the accuracy measure, our best model achieved a score of 77.1\% on the validation data, which is about the same as the performance obtained by the baseline system (77.0\%).