 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Correction of Named Entity Speech Recognition Errors
Sep 09, 2024
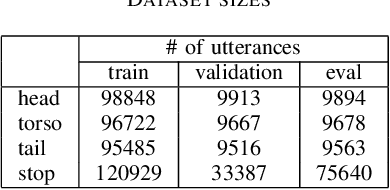
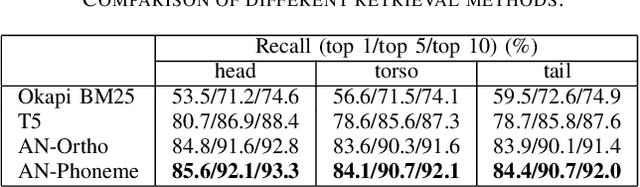
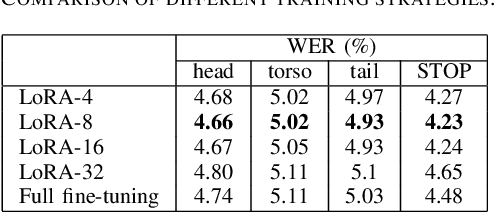
In recent years, end-to-end automatic speech recognition (ASR) systems have proven themselves remarkably accurate and performant, but these systems still have a significant error rate for entity names which appear infrequently in their training data. In parallel to the rise of end-to-end ASR systems, large language models (LLMs) have proven to be a versatile tool for various natural language processing (NLP) tasks. In NLP tasks where a database of relevant knowledge is available, retrieval augmented generation (RAG) has achieved impressive results when used with LLMs. In this work, we propose a RAG-like technique for correcting speech recognition entity name errors. Our approach uses a vector database to index a set of relevant entities. At runtime, database queries are generated from possibly errorful textual ASR hypotheses, and the entities retrieved using these queries are fed, along with the ASR hypotheses, to an LLM which has been adapted to correct ASR errors. Overall, our best system achieves 33%-39% relative word error rate reductions on synthetic test sets focused on voice assistant queries of rare music entities without regressing on the STOP test set, a publicly available voice assistant test set covering many domains.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Error-driven Pruning of Language Models for Virtual Assistants
Feb 14, 2021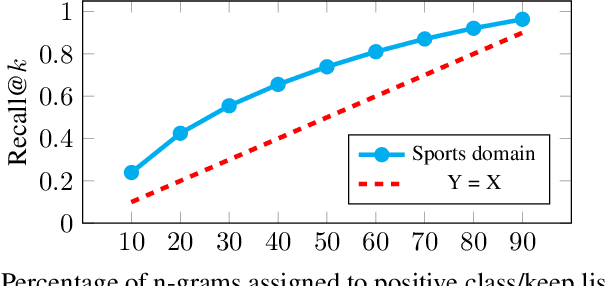
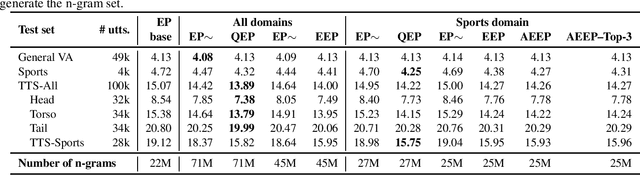
Language models (LMs) for virtual assistants (VAs) are typically trained on large amounts of data, resulting in prohibitively large models which require excessive memory and/or cannot be used to serve user requests in real-time. Entropy pruning results in smaller models but with significant degradation of effectiveness in the tail of the user request distribution. We customize entropy pruning by allowing for a keep list of infrequent n-grams that require a more relaxed pruning threshold, and propose three methods to construct the keep list. Each method has its own advantages and disadvantages with respect to LM size, ASR accuracy and cost of constructing the keep list. Our best LM gives 8% average Word Error Rate (WER) reduction on a targeted test set, but is 3 times larger than the baseline. We also propose discriminative methods to reduce the size of the LM while retaining the majority of the WER gains achieved by the largest LM.