 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetically-Augmented Discriminative Rescoring for Voice Search Error Correction
Jun 06, 2025End-to-end (E2E) Automatic Speech Recognition (ASR) models are trained using paired audio-text samples that are expensive to obtain, since high-quality ground-truth data requires human annotators. Voice search applications, such as digital media players, leverage ASR to allow users to search by voice as opposed to an on-screen keyboard. However, recent or infrequent movie titles may not be sufficiently represented in the E2E ASR system's training data, and hence, may suffer poor recognition. In this paper, we propose a phonetic correction system that consists of (a) a phonetic search based on the ASR model's output that generates phonetic alternatives that may not be considered by the E2E system, and (b) a rescorer component that combines the ASR model recognition and the phonetic alternatives, and select a final system output. We find that our approach improves word error rate between 4.4 and 7.6% relative on benchmarks of popular movie titles over a series of competitive baselines.
Transformer-based Model for ASR N-Best Rescoring and Rewriting
Jun 12, 2024



Voice assistants increasingly use on-device Automatic Speech Recognition (ASR) to ensure speed and privacy. However, due to resource constraints on the device, queries pertaining to complex information domains often require further processing by a search engine. For such applications, we propose a novel Transformer based model capable of rescoring and rewriting, by exploring full context of the N-best hypotheses in parallel. We also propose a new discriminative sequence training objective that can work well for both rescore and rewrite tasks. We show that our Rescore+Rewrite model outperforms the Rescore-only baseline, and achieves up to an average 8.6% relative Word Error Rate (WER) reduction over the ASR system by itself.
Synthetic Query Generation using Large Language Models for Virtual Assistants
Jun 10, 2024

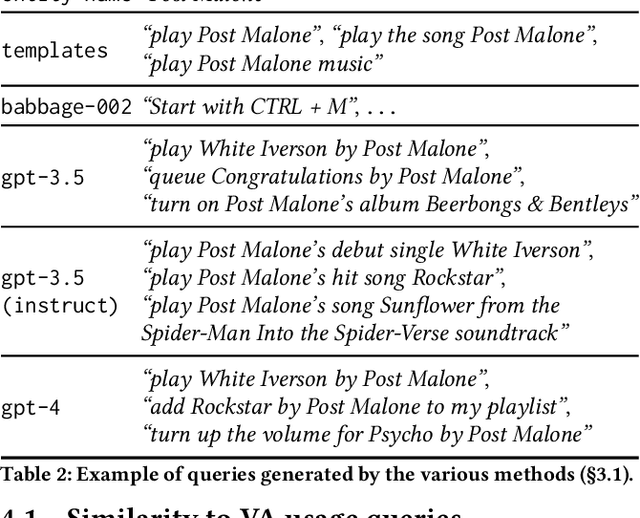
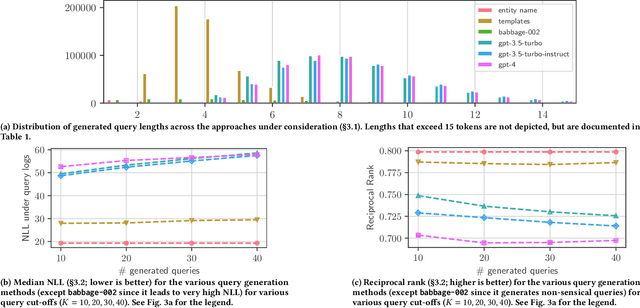
Virtual Assistants (VAs) are important Information Retrieval platforms that help users accomplish various tasks through spoken commands. The speech recognition system (speech-to-text) uses query priors, trained solely on text, to distinguish between phonetically confusing alternatives. Hence, the generation of synthetic queries that are similar to existing VA usage can greatly improve upon the VA's abilities -- especially for use-cases that do not (yet) occur in paired audio/text data. In this paper, we provide a preliminary exploration of the use of Large Language Models (LLMs) to generate synthetic queries that are complementary to template-based methods. We investigate whether the methods (a) generate queries that are similar to randomly sampled, representative, and anonymized user queries from a popular VA, and (b) whether the generated queries are specific. We find that LLMs generate more verbose queries, compared to template-based methods, and reference aspects specific to the entity. The generated queries are similar to VA user queries, and are specific enough to retrieve the relevant entity. We conclude that queries generated by LLMs and templates are complementary.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Modeling Spoken Information Queries for Virtual Assistants: Open Problems, Challenges and Opportunities
Apr 25, 2023Virtual assistants are becoming increasingly important speech-driven Information Retrieval platforms that assist users with various tasks. We discuss open problems and challenges with respect to modeling spoken information queries for virtual assistants, and list opportunities where Information Retrieval methods and research can be applied to improve the quality of virtual assistant speech recognition. We discuss how query domain classification, knowledge graphs and user interaction data, and query personalization can be helpful to improve the accurate recognition of spoken information domain queries. Finally, we also provide a brief overview of current problems and challenges in speech recognition.
Space-Efficient Representation of Entity-centric Query Language Models
Jun 29, 2022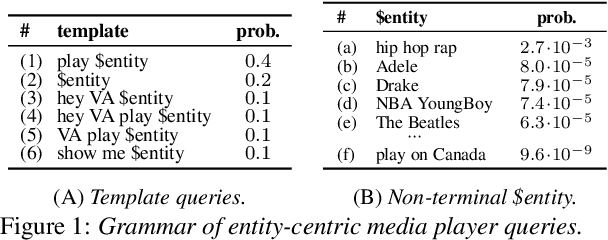

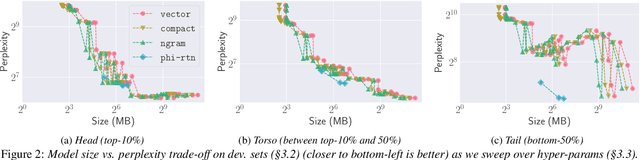
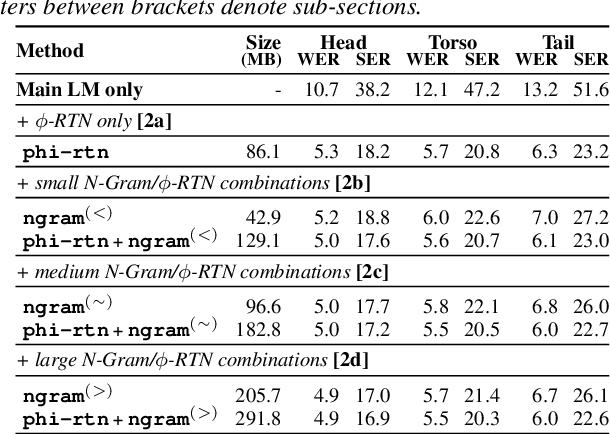
Virtual assistants make use of automatic speech recognition (ASR) to help users answer entity-centric queries. However, spoken entity recognition is a difficult problem, due to the large number of frequently-changing named entities. In addition, resources available for recognition are constrained when ASR is performed on-device. In this work, we investigate the use of probabilistic grammars as language models within the finite-state transducer (FST) framework. We introduce a deterministic approximation to probabilistic grammars that avoids the explicit expansion of non-terminals at model creation time, integrates directly with the FST framework, and is complementary to n-gram models. We obtain a 10% relative word error rate improvement on long tail entity queries compared to when a similarly-sized n-gram model is used without our method.
A Discriminative Entity-Aware Language Model for Virtual Assistants
Jun 21, 2021
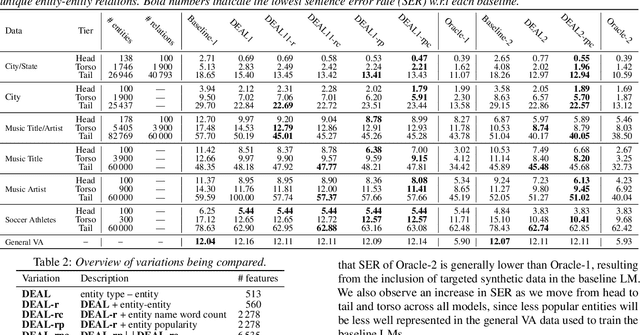


High-quality automatic speech recognition (ASR) is essential for virtual assistants (VAs) to work well. However, ASR often performs poorly on VA requests containing named entities. In this work, we start from the observation that many ASR errors on named entities are inconsistent with real-world knowledge. We extend previous discriminative n-gram language modeling approaches to incorporate real-world knowledge from a Knowledge Graph (KG), using features that capture entity type-entity and entity-entity relationships. We apply our model through an efficient lattice rescoring process, achieving relative sentence error rate reductions of more than 25% on some synthesized test sets covering less popular entities, with minimal degradation on a uniformly sampled VA test set.
Error-driven Pruning of Language Models for Virtual Assistants
Feb 14, 2021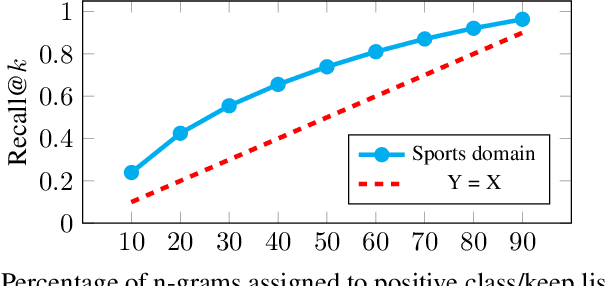
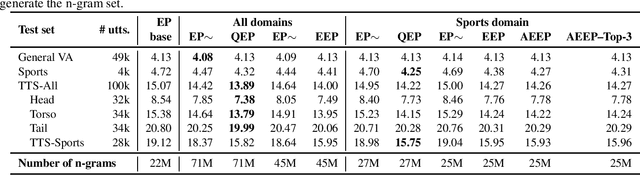
Language models (LMs) for virtual assistants (VAs) are typically trained on large amounts of data, resulting in prohibitively large models which require excessive memory and/or cannot be used to serve user requests in real-time. Entropy pruning results in smaller models but with significant degradation of effectiveness in the tail of the user request distribution. We customize entropy pruning by allowing for a keep list of infrequent n-grams that require a more relaxed pruning threshold, and propose three methods to construct the keep list. Each method has its own advantages and disadvantages with respect to LM size, ASR accuracy and cost of constructing the keep list. Our best LM gives 8% average Word Error Rate (WER) reduction on a targeted test set, but is 3 times larger than the baseline. We also propose discriminative methods to reduce the size of the LM while retaining the majority of the WER gains achieved by the largest LM.
Predicting Entity Popularity to Improve Spoken Entity Recognition by Virtual Assistants
May 26, 2020
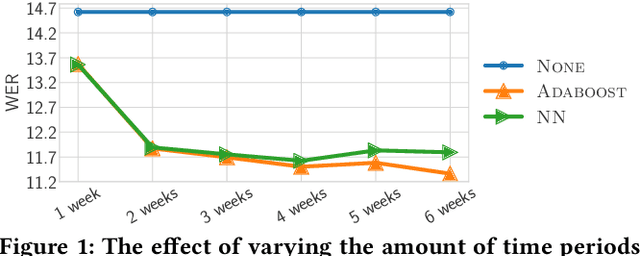
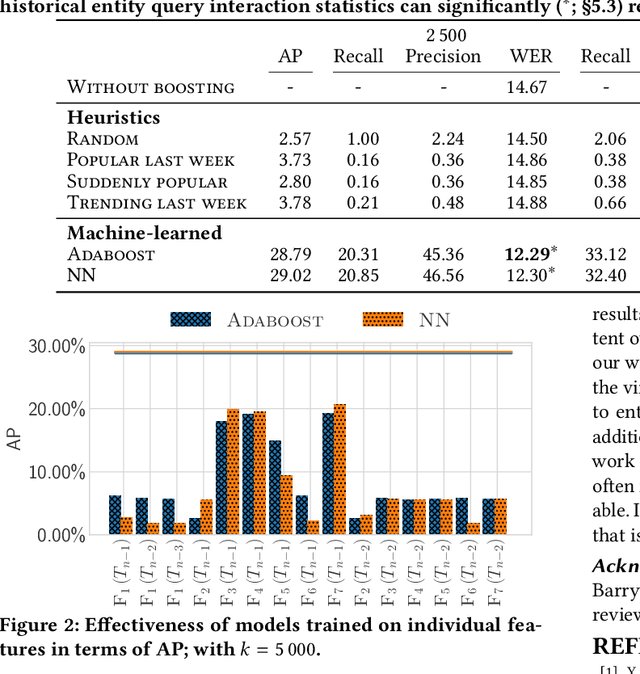
We focus on improving the effectiveness of a Virtual Assistant (VA) in recognizing emerging entities in spoken queries. We introduce a method that uses historical user interactions to forecast which entities will gain in popularity and become trending, and it subsequently integrates the predictions within the Automated Speech Recognition (ASR) component of the VA. Experiments show that our proposed approach results in a 20% relative reduction in errors on emerging entity name utterances without degrading the overall recognition quality of the system.
Connecting and Comparing Language Model Interpolation Techniques
Aug 26, 2019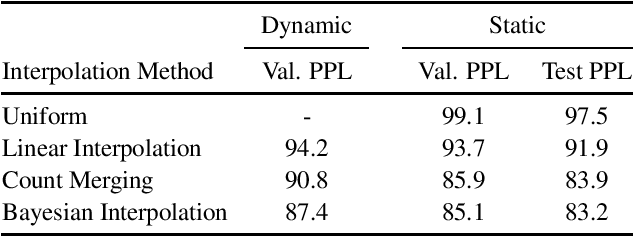
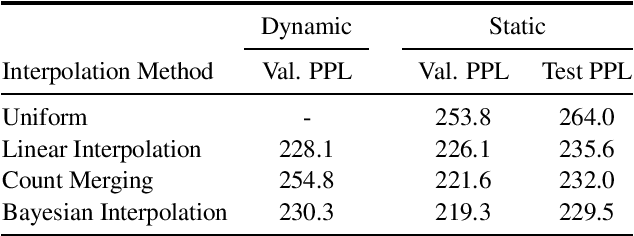
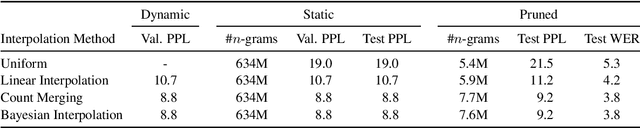
In this work, we uncover a theoretical connection between two language model interpolation techniques, count merging and Bayesian interpolation. We compare these techniques as well as linear interpolation in three scenarios with abundant training data per component model. Consistent with prior work, we show that both count merging and Bayesian interpolation outperform linear interpolation. We include the first (to our knowledge) published comparison of count merging and Bayesian interpolation, showing that the two techniques perform similarly. Finally, we argue that other considerations will make Bayesian interpolation the preferred approach in most circumstances.