 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Query Generation using Large Language Models for Virtual Assistants
Jun 10, 2024

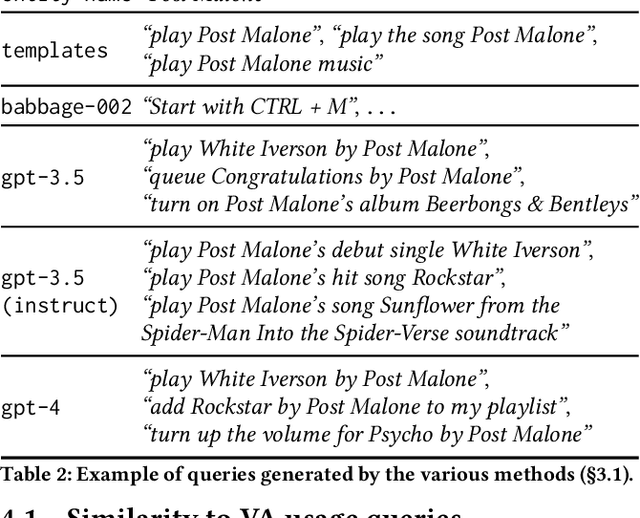
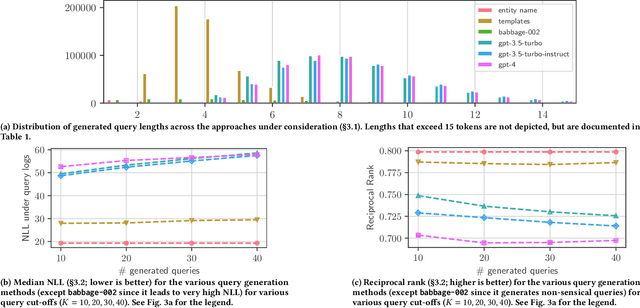
Virtual Assistants (VAs) are important Information Retrieval platforms that help users accomplish various tasks through spoken commands. The speech recognition system (speech-to-text) uses query priors, trained solely on text, to distinguish between phonetically confusing alternatives. Hence, the generation of synthetic queries that are similar to existing VA usage can greatly improve upon the VA's abilities -- especially for use-cases that do not (yet) occur in paired audio/text data. In this paper, we provide a preliminary exploration of the use of Large Language Models (LLMs) to generate synthetic queries that are complementary to template-based methods. We investigate whether the methods (a) generate queries that are similar to randomly sampled, representative, and anonymized user queries from a popular VA, and (b) whether the generated queries are specific. We find that LLMs generate more verbose queries, compared to template-based methods, and reference aspects specific to the entity. The generated queries are similar to VA user queries, and are specific enough to retrieve the relevant entity. We conclude that queries generated by LLMs and templates are complementary.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Neural Language Model Pruning for Automatic Speech Recognition
Oct 05, 2023We study model pruning methods applied to Transformer-based neural network language models for automatic speech recognition. We explore three aspects of the pruning frame work, namely criterion, method and scheduler, analyzing their contribution in terms of accuracy and inference speed. To the best of our knowledge, such in-depth analyses on large-scale recognition systems has not been reported in the literature. In addition, we propose a variant of low-rank approximation suitable for incrementally compressing models, and delivering multiple models with varied target sizes. Among other results, we show that a) data-driven pruning outperforms magnitude-driven in several scenarios; b) incremental pruning achieves higher accuracy compared to one-shot pruning, especially when targeting smaller sizes; and c) low-rank approximation presents the best trade-off between size reduction and inference speed-up for moderate compression.