 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Phonetically-Augmented Discriminative Rescoring for Voice Search Error Correction
Jun 06, 2025End-to-end (E2E) Automatic Speech Recognition (ASR) models are trained using paired audio-text samples that are expensive to obtain, since high-quality ground-truth data requires human annotators. Voice search applications, such as digital media players, leverage ASR to allow users to search by voice as opposed to an on-screen keyboard. However, recent or infrequent movie titles may not be sufficiently represented in the E2E ASR system's training data, and hence, may suffer poor recognition. In this paper, we propose a phonetic correction system that consists of (a) a phonetic search based on the ASR model's output that generates phonetic alternatives that may not be considered by the E2E system, and (b) a rescorer component that combines the ASR model recognition and the phonetic alternatives, and select a final system output. We find that our approach improves word error rate between 4.4 and 7.6% relative on benchmarks of popular movie titles over a series of competitive baselines.
Enhancing CTC-based speech recognition with diverse modeling units
Jun 05, 2024



In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023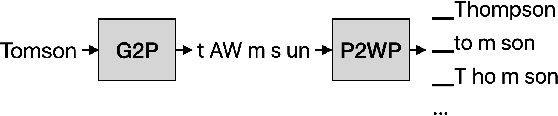


Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
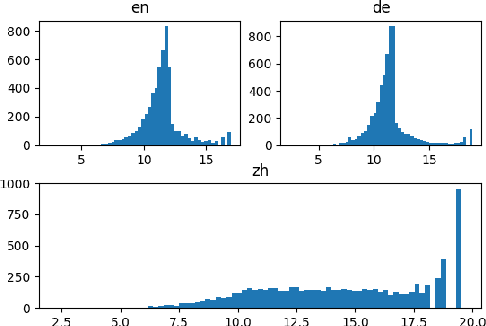
Acoustic Model Fusion for End-to-end Speech Recognition
Oct 10, 2023

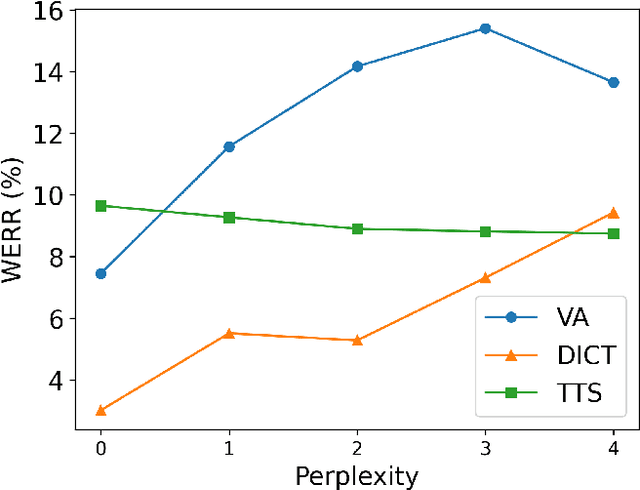
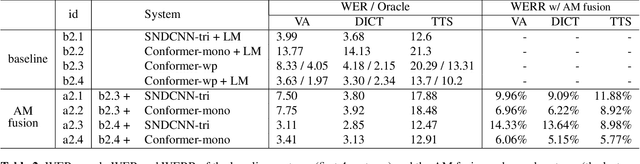
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted the accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E system has proven to be beneficial. However, the application of LM fusion presents certain drawbacks, such as its inability to address the domain mismatch issue inherent to the internal AM. Drawing inspiration from the concept of LM fusion, we propose the integration of an external AM into the E2E system to better address the domain mismatch. By implementing this novel approach, we have achieved a significant reduction in the word error rate, with an impressive drop of up to 14.3% across varied test sets. We also discovered that this AM fusion approach is particularly beneficial in enhancing named entity recognition.