 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Attention Decoding With Long Form Acoustic Encodings
Dec 16, 2025

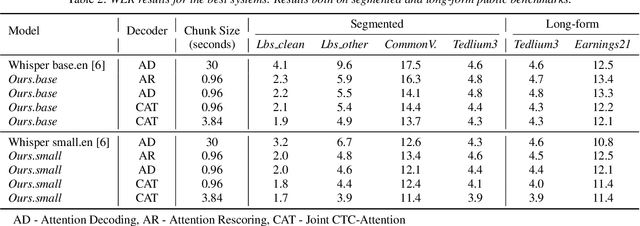
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.
Optimizing Contextual Speech Recognition Using Vector Quantization for Efficient Retrieval
Nov 04, 2024Neural contextual biasing allows speech recognition models to leverage contextually relevant information, leading to improved transcription accuracy. However, the biasing mechanism is typically based on a cross-attention module between the audio and a catalogue of biasing entries, which means computational complexity can pose severe practical limitations on the size of the biasing catalogue and consequently on accuracy improvements. This work proposes an approximation to cross-attention scoring based on vector quantization and enables compute- and memory-efficient use of large biasing catalogues. We propose to use this technique jointly with a retrieval based contextual biasing approach. First, we use an efficient quantized retrieval module to shortlist biasing entries by grounding them on audio. Then we use retrieved entries for biasing. Since the proposed approach is agnostic to the biasing method, we investigate using full cross-attention, LLM prompting, and a combination of the two. We show that retrieval based shortlisting allows the system to efficiently leverage biasing catalogues of several thousands of entries, resulting in up to 71% relative error rate reduction in personal entity recognition. At the same time, the proposed approximation algorithm reduces compute time by 20% and memory usage by 85-95%, for lists of up to one million entries, when compared to standard dot-product cross-attention.
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
SLURP: A Spoken Language Understanding Resource Package
Nov 26, 2020



Spoken Language Understanding infers semantic meaning directly from audio data, and thus promises to reduce error propagation and misunderstandings in end-user applications. However, publicly available SLU resources are limited. In this paper, we release SLURP, a new SLU package containing the following: (1) A new challenging dataset in English spanning 18 domains, which is substantially bigger and linguistically more diverse than existing datasets; (2) Competitive baselines based on state-of-the-art NLU and ASR systems; (3) A new transparent metric for entity labelling which enables a detailed error analysis for identifying potential areas of improvement. SLURP is available at https: //github.com/pswietojanski/slurp.
Adaptation Algorithms for Speech Recognition: An Overview
Aug 14, 2020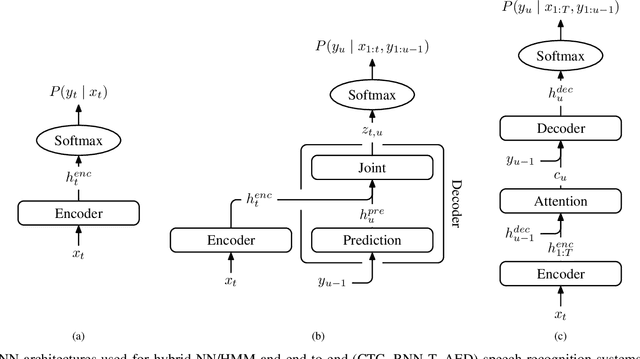
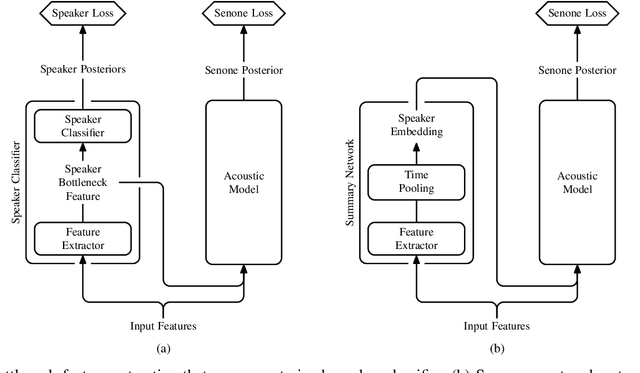
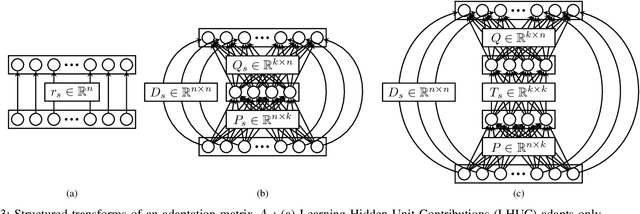
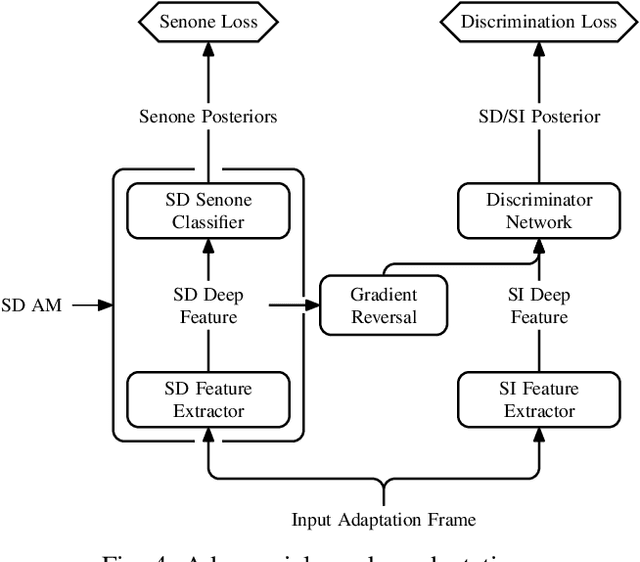
We present a structured overview of adaptation algorithms for neural network-based speech recognition, considering both hybrid hidden Markov model / neural network systems and end-to-end neural network systems, with a focus on speaker adaptation, domain adaptation, and accent adaptation. The overview characterizes adaptation algorithms as based on embeddings, model parameter adaptation, or data augmentation. We present a meta-analysis of the performance of speech recognition adaptation algorithms, based on relative error rate reductions as reported in the literature.
Multi-task self-supervised learning for Robust Speech Recognition
Jan 25, 2020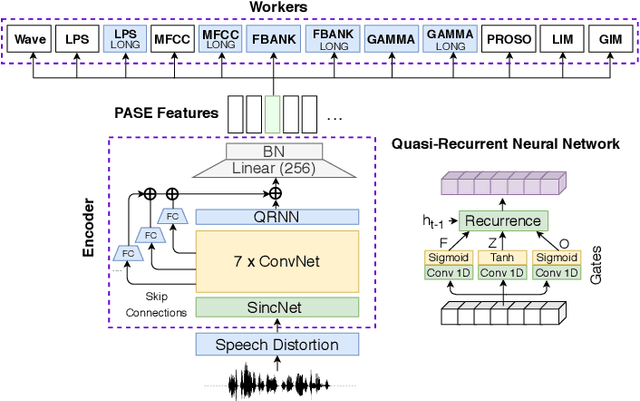
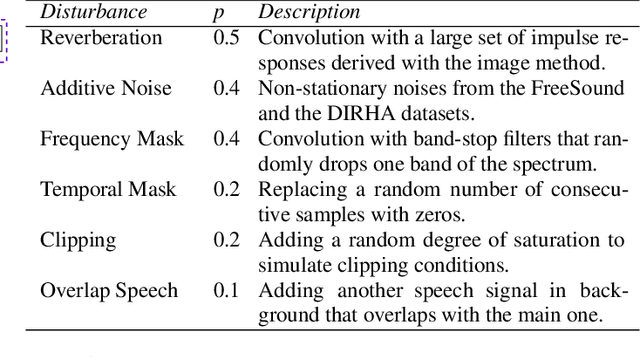
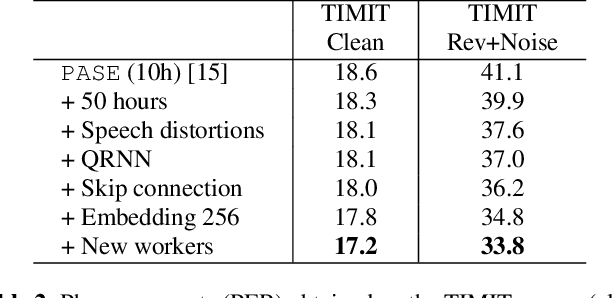
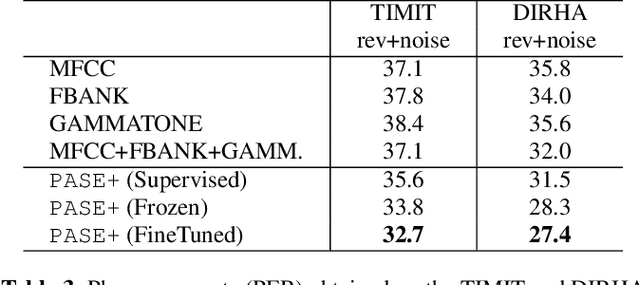
Despite the growing interest in unsupervised learning, extracting meaningful knowledge from unlabelled audio remains an open challenge. To take a step in this direction, we recently proposed a problem-agnostic speech encoder (PASE), that combines a convolutional encoder followed by multiple neural networks, called workers, tasked to solve self-supervised problems (i.e., ones that do not require manual annotations as ground truth). PASE was shown to capture relevant speech information, including speaker voice-print and phonemes. This paper proposes PASE+, an improved version of PASE for robust speech recognition in noisy and reverberant environments. To this end, we employ an online speech distortion module, that contaminates the input signals with a variety of random disturbances. We then propose a revised encoder that better learns short- and long-term speech dynamics with an efficient combination of recurrent and convolutional networks. Finally, we refine the set of workers used in self-supervision to encourage better cooperation. Results on TIMIT, DIRHA and CHiME-5 show that PASE+ significantly outperforms both the previous version of PASE as well as common acoustic features. Interestingly, PASE+ learns transferable representations suitable for highly mismatched acoustic conditions.
Benchmarking Natural Language Understanding Services for building Conversational Agents
Mar 26, 2019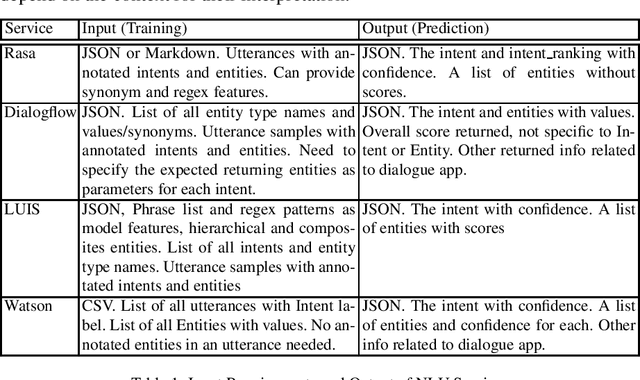



We have recently seen the emergence of several publicly available Natural Language Understanding (NLU) toolkits, which map user utterances to structured, but more abstract, Dialogue Act (DA) or Intent specifications, while making this process accessible to the lay developer. In this paper, we present the first wide coverage evaluation and comparison of some of the most popular NLU services, on a large, multi-domain (21 domains) dataset of 25K user utterances that we have collected and annotated with Intent and Entity Type specifications and which will be released as part of this submission. The results show that on Intent classification Watson significantly outperforms the other platforms, namely, Dialogflow, LUIS and Rasa; though these also perform well. Interestingly, on Entity Type recognition, Watson performs significantly worse due to its low Precision. Again, Dialogflow, LUIS and Rasa perform well on this task.
Differentiable Pooling for Unsupervised Acoustic Model Adaptation
Jul 13, 2016
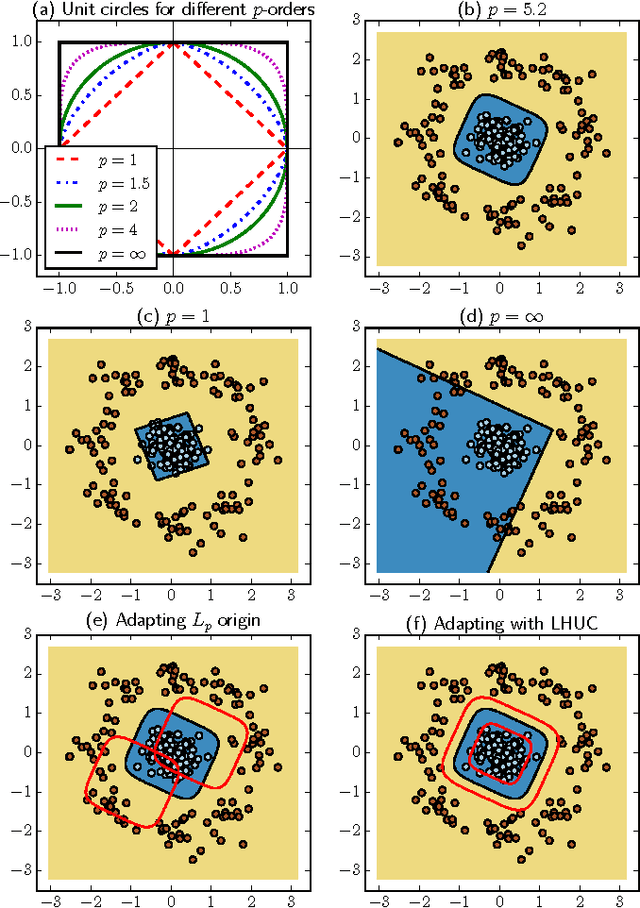
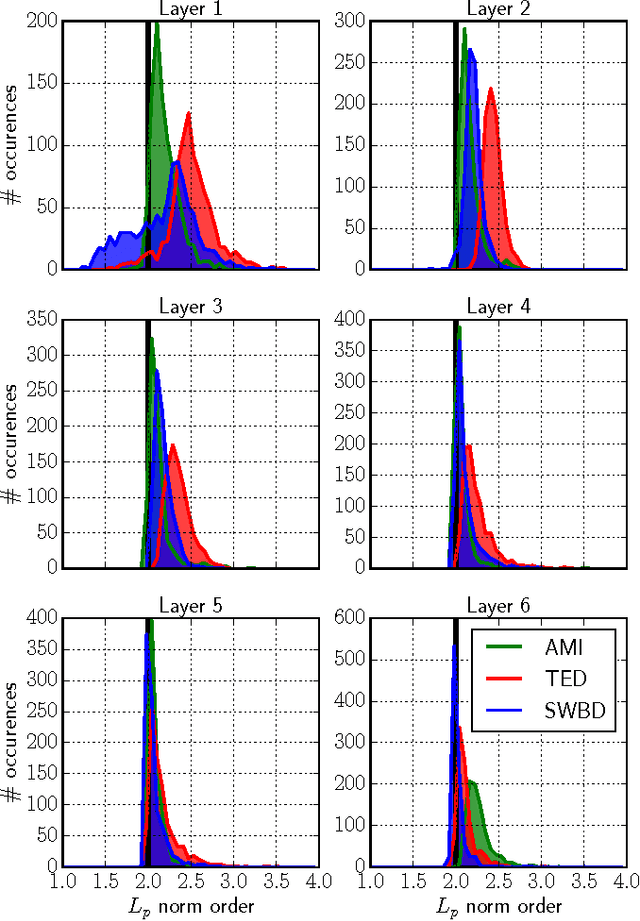

We present a deep neural network (DNN) acoustic model that includes parametrised and differentiable pooling operators. Unsupervised acoustic model adaptation is cast as the problem of updating the decision boundaries implemented by each pooling operator. In particular, we experiment with two types of pooling parametrisations: learned $L_p$-norm pooling and weighted Gaussian pooling, in which the weights of both operators are treated as speaker-dependent. We perform investigations using three different large vocabulary speech recognition corpora: AMI meetings, TED talks and Switchboard conversational telephone speech. We demonstrate that differentiable pooling operators provide a robust and relatively low-dimensional way to adapt acoustic models, with relative word error rates reductions ranging from 5--20% with respect to unadapted systems, which themselves are better than the baseline fully-connected DNN-based acoustic models. We also investigate how the proposed techniques work under various adaptation conditions including the quality of adaptation data and complementarity to other feature- and model-space adaptation methods, as well as providing an analysis of the characteristics of each of the proposed approaches.
Learning Hidden Unit Contributions for Unsupervised Acoustic Model Adaptation
Jul 13, 2016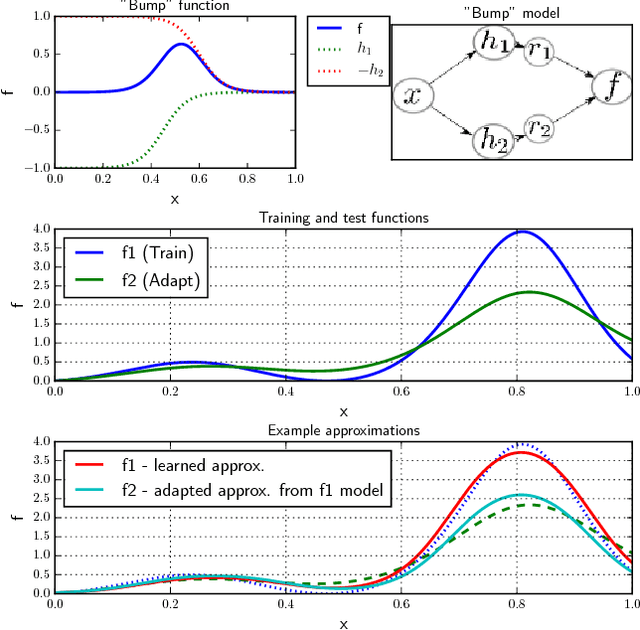
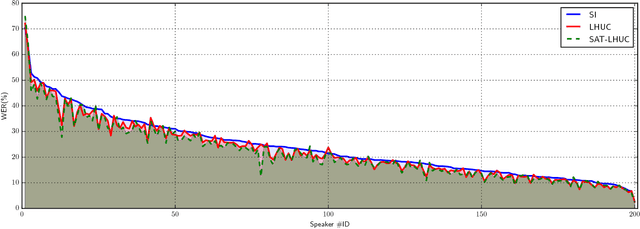
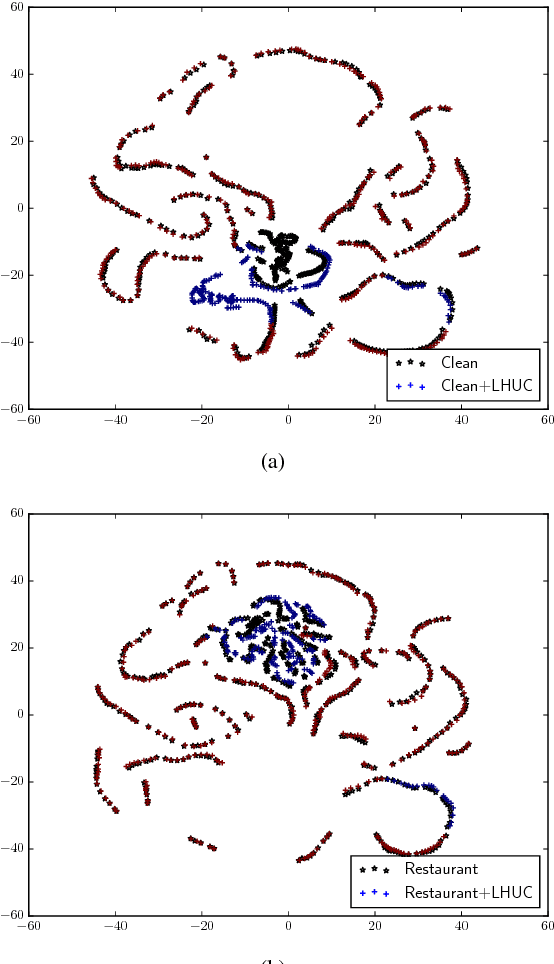
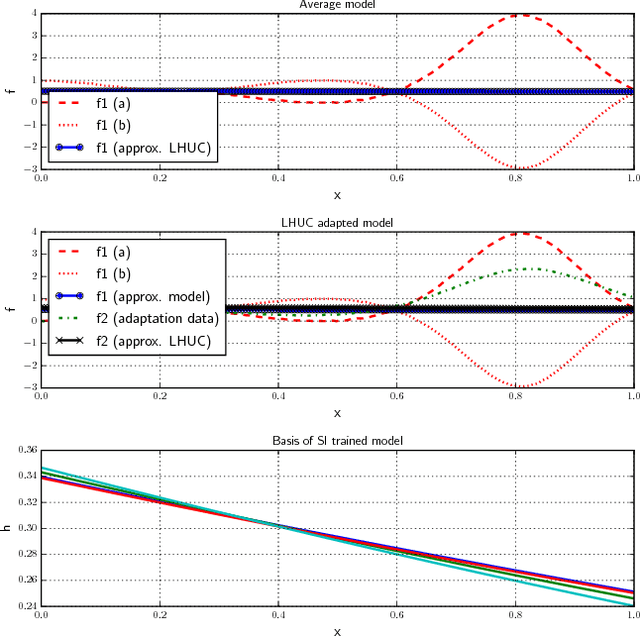
This work presents a broad study on the adaptation of neural network acoustic models by means of learning hidden unit contributions (LHUC) -- a method that linearly re-combines hidden units in a speaker- or environment-dependent manner using small amounts of unsupervised adaptation data. We also extend LHUC to a speaker adaptive training (SAT) framework that leads to a more adaptable DNN acoustic model, working both in a speaker-dependent and a speaker-independent manner, without the requirements to maintain auxiliary speaker-dependent feature extractors or to introduce significant speaker-dependent changes to the DNN structure. Through a series of experiments on four different speech recognition benchmarks (TED talks, Switchboard, AMI meetings, and Aurora4) comprising 270 test speakers, we show that LHUC in both its test-only and SAT variants results in consistent word error rate reductions ranging from 5% to 23% relative depending on the task and the degree of mismatch between training and test data. In addition, we have investigated the effect of the amount of adaptation data per speaker, the quality of unsupervised adaptation targets, the complementarity to other adaptation techniques, one-shot adaptation, and an extension to adapting DNNs trained in a sequence discriminative manner.