 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Attention Decoding With Long Form Acoustic Encodings
Dec 16, 2025

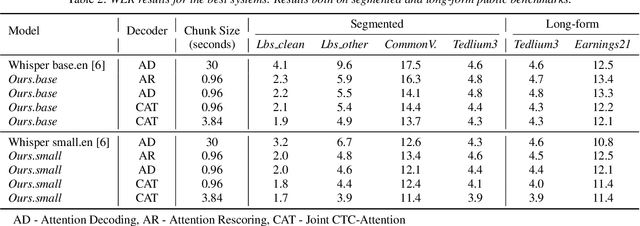
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.
Optimizing Contextual Speech Recognition Using Vector Quantization for Efficient Retrieval
Nov 04, 2024Neural contextual biasing allows speech recognition models to leverage contextually relevant information, leading to improved transcription accuracy. However, the biasing mechanism is typically based on a cross-attention module between the audio and a catalogue of biasing entries, which means computational complexity can pose severe practical limitations on the size of the biasing catalogue and consequently on accuracy improvements. This work proposes an approximation to cross-attention scoring based on vector quantization and enables compute- and memory-efficient use of large biasing catalogues. We propose to use this technique jointly with a retrieval based contextual biasing approach. First, we use an efficient quantized retrieval module to shortlist biasing entries by grounding them on audio. Then we use retrieved entries for biasing. Since the proposed approach is agnostic to the biasing method, we investigate using full cross-attention, LLM prompting, and a combination of the two. We show that retrieval based shortlisting allows the system to efficiently leverage biasing catalogues of several thousands of entries, resulting in up to 71% relative error rate reduction in personal entity recognition. At the same time, the proposed approximation algorithm reduces compute time by 20% and memory usage by 85-95%, for lists of up to one million entries, when compared to standard dot-product cross-attention.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020

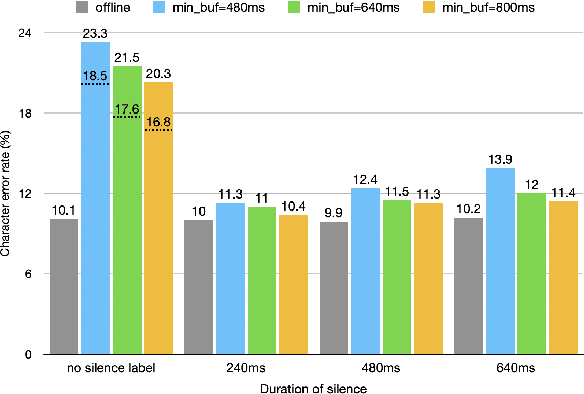
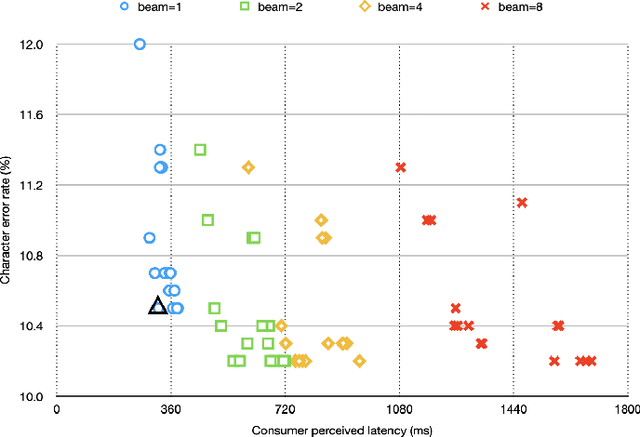
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.