 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing for Incremental Parse States in Autoregressive Language Models
Nov 17, 2022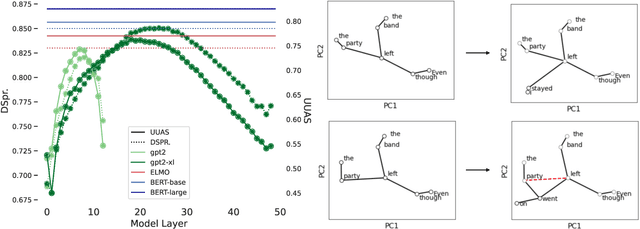
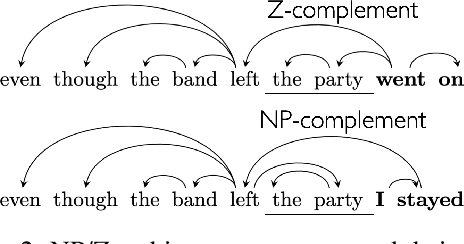
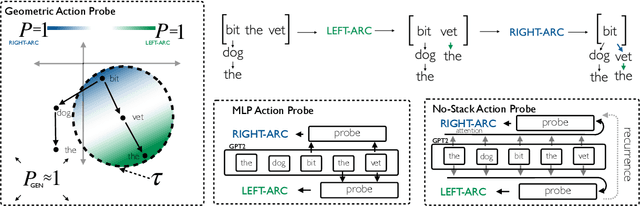
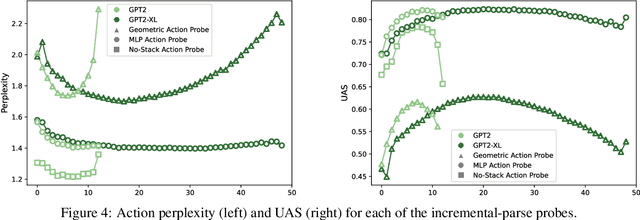
Next-word predictions from autoregressive neural language models show remarkable sensitivity to syntax. This work evaluates the extent to which this behavior arises as a result of a learned ability to maintain implicit representations of incremental syntactic structures. We extend work in syntactic probing to the incremental setting and present several probes for extracting incomplete syntactic structure (operationalized through parse states from a stack-based parser) from autoregressive language models. We find that our probes can be used to predict model preferences on ambiguous sentence prefixes and causally intervene on model representations and steer model behavior. This suggests implicit incremental syntactic inferences underlie next-word predictions in autoregressive neural language models.