 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
Apr 24, 2025Subject-driven text-to-image (T2I) generation aims to produce images that align with a given textual description, while preserving the visual identity from a referenced subject image. Despite its broad downstream applicability -- ranging from enhanced personalization in image generation to consistent character representation in video rendering -- progress in this field is limited by the lack of reliable automatic evaluation. Existing methods either assess only one aspect of the task (i.e., textual alignment or subject preservation), misalign with human judgments, or rely on costly API-based evaluation. To address this, we introduce RefVNLI, a cost-effective metric that evaluates both textual alignment and subject preservation in a single prediction. Trained on a large-scale dataset derived from video-reasoning benchmarks and image perturbations, RefVNLI outperforms or matches existing baselines across multiple benchmarks and subject categories (e.g., \emph{Animal}, \emph{Object}), achieving up to 6.4-point gains in textual alignment and 8.5-point gains in subject consistency. It also excels with lesser-known concepts, aligning with human preferences at over 87\% accuracy.
GRADE: Quantifying Sample Diversity in Text-to-Image Models
Oct 29, 2024



Text-to-image (T2I) models are remarkable at generating realistic images based on textual descriptions. However, textual prompts are inherently underspecified: they do not specify all possible attributes of the required image. This raises two key questions: Do T2I models generate diverse outputs on underspecified prompts? How can we automatically measure diversity? We propose GRADE: Granular Attribute Diversity Evaluation, an automatic method for quantifying sample diversity. GRADE leverages the world knowledge embedded in large language models and visual question-answering systems to identify relevant concept-specific axes of diversity (e.g., ``shape'' and ``color'' for the concept ``cookie''). It then estimates frequency distributions of concepts and their attributes and quantifies diversity using (normalized) entropy. GRADE achieves over 90% human agreement while exhibiting weak correlation to commonly used diversity metrics. We use GRADE to measure the overall diversity of 12 T2I models using 400 concept-attribute pairs, revealing that all models display limited variation. Further, we find that these models often exhibit default behaviors, a phenomenon where the model consistently generates concepts with the same attributes (e.g., 98% of the cookies are round). Finally, we demonstrate that a key reason for low diversity is due to underspecified captions in training data. Our work proposes a modern, semantically-driven approach to measure sample diversity and highlights the stunning homogeneity in outputs by T2I models.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Visual Riddles: a Commonsense and World Knowledge Challenge for Large Vision and Language Models
Jul 28, 2024Imagine observing someone scratching their arm; to understand why, additional context would be necessary. However, spotting a mosquito nearby would immediately offer a likely explanation for the person's discomfort, thereby alleviating the need for further information. This example illustrates how subtle visual cues can challenge our cognitive skills and demonstrates the complexity of interpreting visual scenarios. To study these skills, we present Visual Riddles, a benchmark aimed to test vision and language models on visual riddles requiring commonsense and world knowledge. The benchmark comprises 400 visual riddles, each featuring a unique image created by a variety of text-to-image models, question, ground-truth answer, textual hint, and attribution. Human evaluation reveals that existing models lag significantly behind human performance, which is at 82\% accuracy, with Gemini-Pro-1.5 leading with 40\% accuracy. Our benchmark comes with automatic evaluation tasks to make assessment scalable. These findings underscore the potential of Visual Riddles as a valuable resource for enhancing vision and language models' capabilities in interpreting complex visual scenarios.
Evaluating D-MERIT of Partial-annotation on Information Retrieval
Jun 23, 2024



Retrieval models are often evaluated on partially-annotated datasets. Each query is mapped to a few relevant texts and the remaining corpus is assumed to be irrelevant. As a result, models that successfully retrieve false negatives are punished in evaluation. Unfortunately, completely annotating all texts for every query is not resource efficient. In this work, we show that using partially-annotated datasets in evaluation can paint a distorted picture. We curate D-MERIT, a passage retrieval evaluation set from Wikipedia, aspiring to contain all relevant passages for each query. Queries describe a group (e.g., ``journals about linguistics'') and relevant passages are evidence that entities belong to the group (e.g., a passage indicating that Language is a journal about linguistics). We show that evaluating on a dataset containing annotations for only a subset of the relevant passages might result in misleading ranking of the retrieval systems and that as more relevant texts are included in the evaluation set, the rankings converge. We propose our dataset as a resource for evaluation and our study as a recommendation for balance between resource-efficiency and reliable evaluation when annotating evaluation sets for text retrieval.
Make It Count: Text-to-Image Generation with an Accurate Number of Objects
Jun 14, 2024Despite the unprecedented success of text-to-image diffusion models, controlling the number of depicted objects using text is surprisingly hard. This is important for various applications from technical documents, to children's books to illustrating cooking recipes. Generating object-correct counts is fundamentally challenging because the generative model needs to keep a sense of separate identity for every instance of the object, even if several objects look identical or overlap, and then carry out a global computation implicitly during generation. It is still unknown if such representations exist. To address count-correct generation, we first identify features within the diffusion model that can carry the object identity information. We then use them to separate and count instances of objects during the denoising process and detect over-generation and under-generation. We fix the latter by training a model that predicts both the shape and location of a missing object, based on the layout of existing ones, and show how it can be used to guide denoising with correct object count. Our approach, CountGen, does not depend on external source to determine object layout, but rather uses the prior from the diffusion model itself, creating prompt-dependent and seed-dependent layouts. Evaluated on two benchmark datasets, we find that CountGen strongly outperforms the count-accuracy of existing baselines.
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment
Jun 15, 2023Text-conditioned image generation models often generate incorrect associations between entities and their visual attributes. This reflects an impaired mapping between linguistic binding of entities and modifiers in the prompt and visual binding of the corresponding elements in the generated image. As one notable example, a query like ``a pink sunflower and a yellow flamingo'' may incorrectly produce an image of a yellow sunflower and a pink flamingo. To remedy this issue, we propose SynGen, an approach which first syntactically analyses the prompt to identify entities and their modifiers, and then uses a novel loss function that encourages the cross-attention maps to agree with the linguistic binding reflected by the syntax. Specifically, we encourage large overlap between attention maps of entities and their modifiers, and small overlap with other entities and modifier words. The loss is optimized during inference, without retraining or fine-tuning the model. Human evaluation on three datasets, including one new and challenging set, demonstrate significant improvements of SynGen compared with current state of the art methods. This work highlights how making use of sentence structure during inference can efficiently and substantially improve the faithfulness of text-to-image generation.
Conjunct Resolution in the Face of Verbal Omissions
May 26, 2023



Verbal omissions are complex syntactic phenomena in VP coordination structures. They occur when verbs and (some of) their arguments are omitted from subsequent clauses after being explicitly stated in an initial clause. Recovering these omitted elements is necessary for accurate interpretation of the sentence, and while humans easily and intuitively fill in the missing information, state-of-the-art models continue to struggle with this task. Previous work is limited to small-scale datasets, synthetic data creation methods, and to resolution methods in the dependency-graph level. In this work we propose a conjunct resolution task that operates directly on the text and makes use of a split-and-rephrase paradigm in order to recover the missing elements in the coordination structure. To this end, we first formulate a pragmatic framework of verbal omissions which describes the different types of omissions, and develop an automatic scalable collection method. Based on this method, we curate a large dataset, containing over 10K examples of naturally-occurring verbal omissions with crowd-sourced annotations of the resolved conjuncts. We train various neural baselines for this task, and show that while our best method obtains decent performance, it leaves ample space for improvement. We propose our dataset, metrics and models as a starting point for future research on this topic.
DALLE-2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
Oct 19, 2022
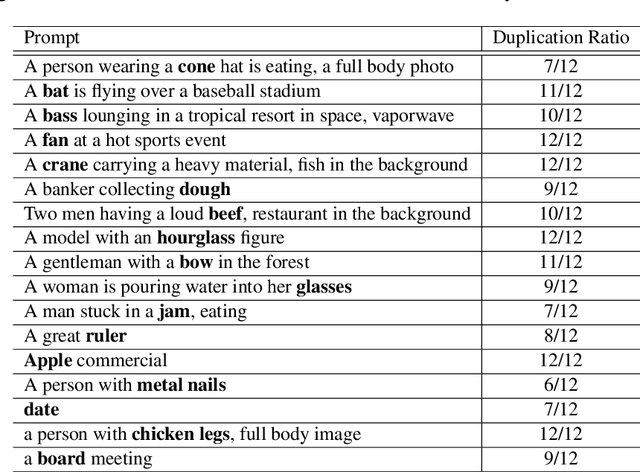

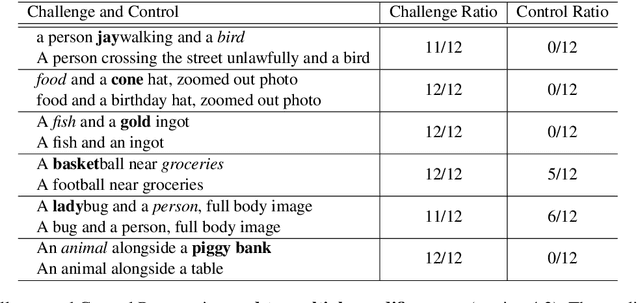
We study the way DALLE-2 maps symbols (words) in the prompt to their references (entities or properties of entities in the generated image). We show that in stark contrast to the way human process language, DALLE-2 does not follow the constraint that each word has a single role in the interpretation, and sometimes re-use the same symbol for different purposes. We collect a set of stimuli that reflect the phenomenon: we show that DALLE-2 depicts both senses of nouns with multiple senses at once; and that a given word can modify the properties of two distinct entities in the image, or can be depicted as one object and also modify the properties of another object, creating a semantic leakage of properties between entities. Taken together, our study highlights the differences between DALLE-2 and human language processing and opens an avenue for future study on the inductive biases of text-to-image models.