 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Deep Submodular Peripteral Networks
Mar 16, 2024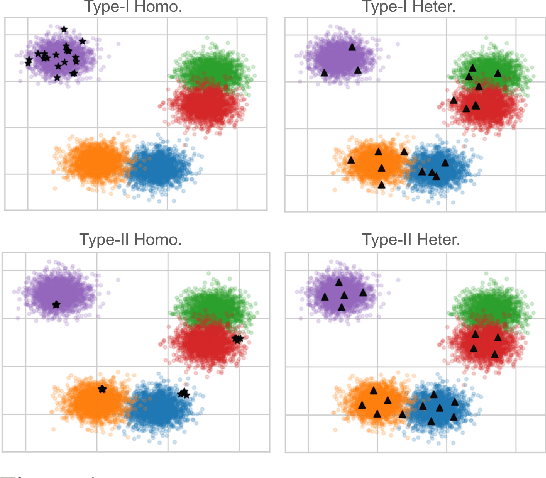
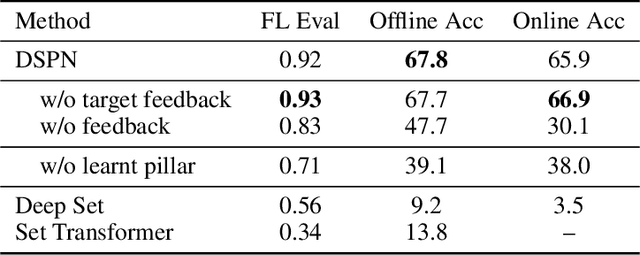
Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a contrastive-learning inspired GPC-ready strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style "peripteral" loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function showing superiority in downstream tasks such as experimental design and streaming applications.
Accelerating Batch Active Learning Using Continual Learning Techniques
May 10, 2023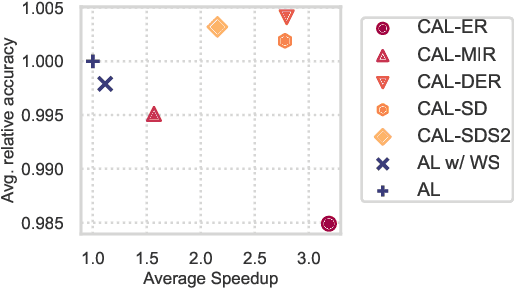
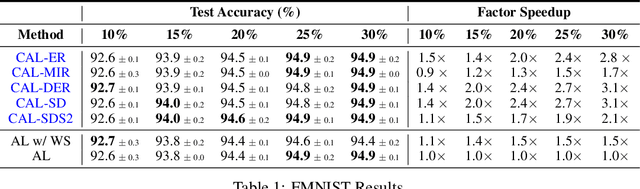
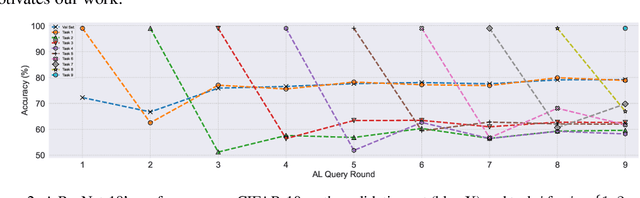
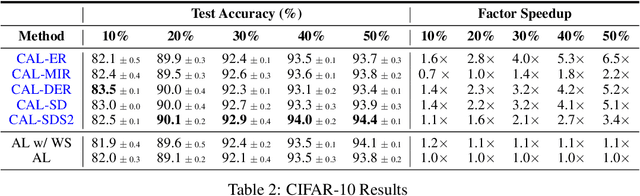
A major problem with Active Learning (AL) is high training costs since models are typically retrained from scratch after every query round. We start by demonstrating that standard AL on neural networks with warm starting fails, both to accelerate training and to avoid catastrophic forgetting when using fine-tuning over AL query rounds. We then develop a new class of techniques, circumventing this problem, by biasing further training towards previously labeled sets. We accomplish this by employing existing, and developing novel, replay-based Continual Learning (CL) algorithms that are effective at quickly learning the new without forgetting the old, especially when data comes from an evolving distribution. We call this paradigm Continual Active Learning (CAL). We show CAL achieves significant speedups using a plethora of replay schemes that use model distillation and that select diverse, uncertain points from the history. We conduct experiments across many data domains, including natural language, vision, medical imaging, and computational biology, each with different neural architectures and dataset sizes. CAL consistently provides a 3x reduction in training time, while retaining performance.
High Resolution Point Clouds from mmWave Radar
Jun 18, 2022
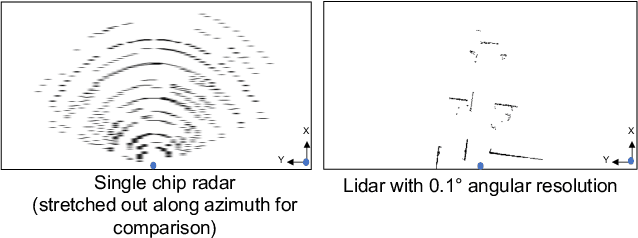
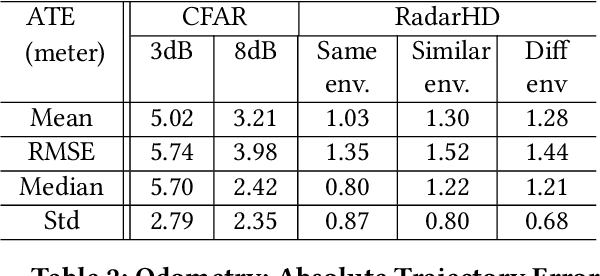

This paper explores a machine learning approach for generating high resolution point clouds from a single-chip mmWave radar. Unlike lidar and vision-based systems, mmWave radar can operate in harsh environments and see through occlusions like smoke, fog, and dust. Unfortunately, current mmWave processing techniques offer poor spatial resolution compared to lidar point clouds. This paper presents RadarHD, an end-to-end neural network that constructs lidar-like point clouds from low resolution radar input. Enhancing radar images is challenging due to the presence of specular and spurious reflections. Radar data also doesn't map well to traditional image processing techniques due to the signal's sinc-like spreading pattern. We overcome these challenges by training RadarHD on a large volume of raw I/Q radar data paired with lidar point clouds across diverse indoor settings. Our experiments show the ability to generate rich point clouds even in scenes unobserved during training and in the presence of heavy smoke occlusion. Further, RadarHD's point clouds are high-quality enough to work with existing lidar odometry and mapping workflows.
Physics-inspired deep learning to characterize the signal manifold of quasi-circular, spinning, non-precessing binary black hole mergers
Apr 20, 2020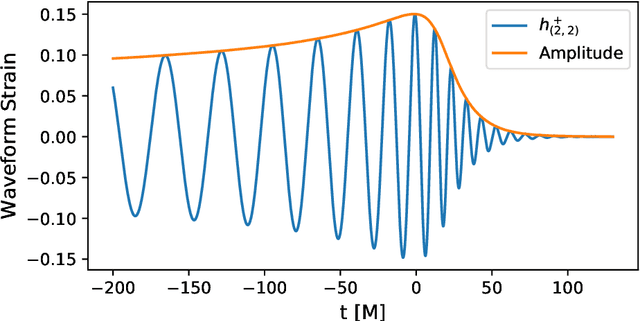
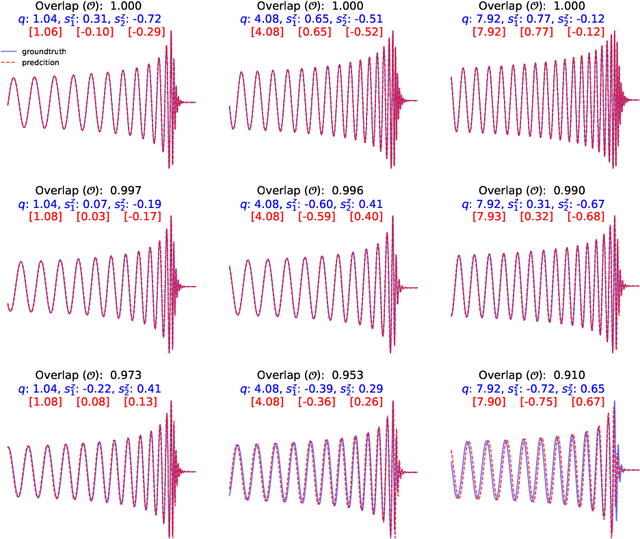
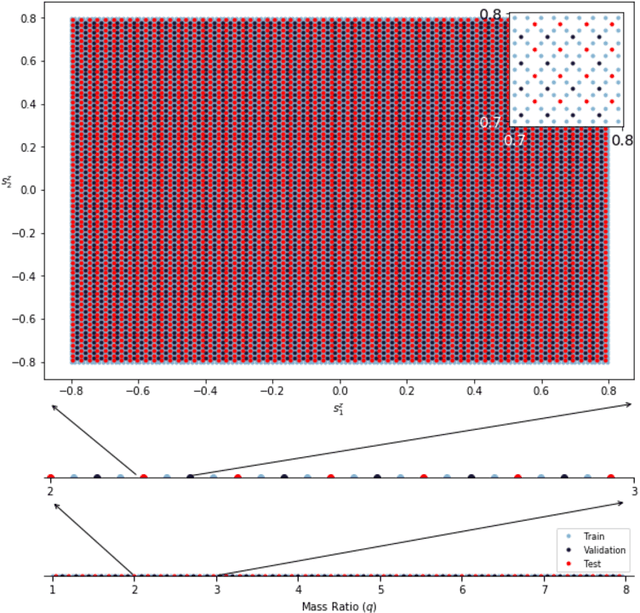
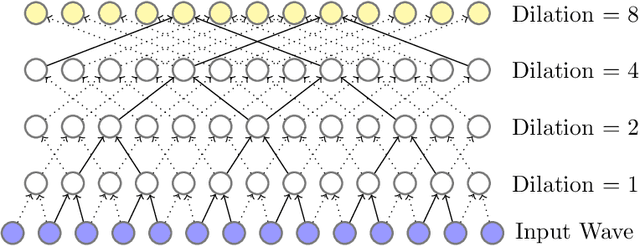
The spin distribution of binary black hole mergers contains key information concerning the formation channels of these objects, and the astrophysical environments where they form, evolve and coalesce. To quantify the suitability of deep learning to characterize the signal manifold of quasi-circular, spinning, non-precessing binary black hole mergers, we introduce a modified version of WaveNet trained with a novel optimization scheme that incorporates general relativistic constraints of the spin properties of astrophysical black holes. The neural network model is trained, validated and tested with 1.5 million $\ell=|m|=2$ waveforms generated within the regime of validity of NRHybSur3dq8, i.e., mass-ratios $q\leq8$ and individual black hole spins $ | s^z_{\{1,\,2\}} | \leq 0.8$. Using this neural network model, we quantify how accurately we can infer the astrophysical parameters of black hole mergers in the absence of noise. We do this by computing the overlap between waveforms in the testing data set and the corresponding signals whose mass-ratio and individual spins are predicted by our neural network. We find that the convergence of high performance computing and physics-inspired optimization algorithms enable an accurate reconstruction of the mass-ratio and individual spins of binary black hole mergers across the parameter space under consideration. This is a significant step towards an informed utilization of physics-inspired deep learning models to reconstruct the spin distribution of binary black hole mergers in realistic detection scenarios.