 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemento: Personalized RAG-Style Long-Retention Data Scaling for META Ads Recommendation
May 22, 2026Modeling of long history data suffers from long-context window attention dilution, system efficiency and catastrophic forgetting problems, where naive linear scaling approach like LastN would fail. We introduce Memento, a personalized retrieval-augmented framework that treats historical user engagements as a document corpus and ad requests as queries, retrieving relevant interactions via Maximal Marginal Relevance (MMR) to balance similarity with diversity. We identify two complementary applications: Representation Memento, which retrieves historical embeddings for feature augmentation, and Data Memento, which retrieves past training examples for multipass training. Through infrastructure co-design -- temporal chunking, INT8 quantization, and asynchronous serving -- Memento achieves 5-10$\times$ resource efficiency over linear scaling. Memento processes daily requests with sub-10ms latency, yielding 0.25-0.3% Normalized Entropy gain on both click-through and conversion prediction. In production, Memento delivers a 1% CTR lift on Facebook Feed and Reels and a 1.2% CVR lift, scaling personalization to 365+ days of history.
COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Learning
Dec 23, 2024Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime, e.g. few-shot learning. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot learning settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
High Resolution Point Clouds from mmWave Radar
Jun 18, 2022
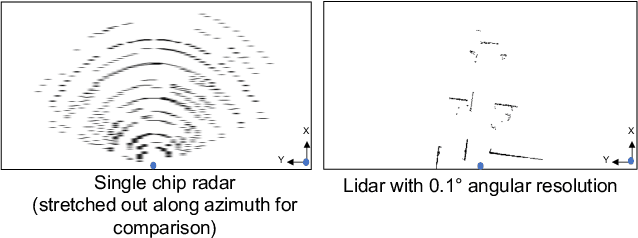
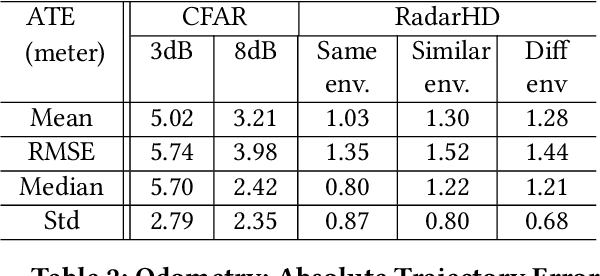

This paper explores a machine learning approach for generating high resolution point clouds from a single-chip mmWave radar. Unlike lidar and vision-based systems, mmWave radar can operate in harsh environments and see through occlusions like smoke, fog, and dust. Unfortunately, current mmWave processing techniques offer poor spatial resolution compared to lidar point clouds. This paper presents RadarHD, an end-to-end neural network that constructs lidar-like point clouds from low resolution radar input. Enhancing radar images is challenging due to the presence of specular and spurious reflections. Radar data also doesn't map well to traditional image processing techniques due to the signal's sinc-like spreading pattern. We overcome these challenges by training RadarHD on a large volume of raw I/Q radar data paired with lidar point clouds across diverse indoor settings. Our experiments show the ability to generate rich point clouds even in scenes unobserved during training and in the presence of heavy smoke occlusion. Further, RadarHD's point clouds are high-quality enough to work with existing lidar odometry and mapping workflows.
Botcha: Detecting Malicious Non-Human Traffic in the Wild
Mar 02, 2021
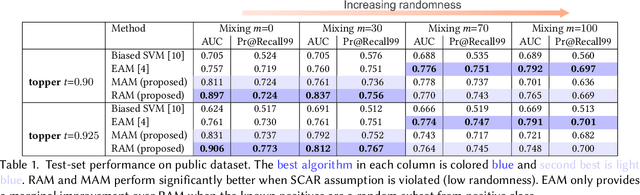
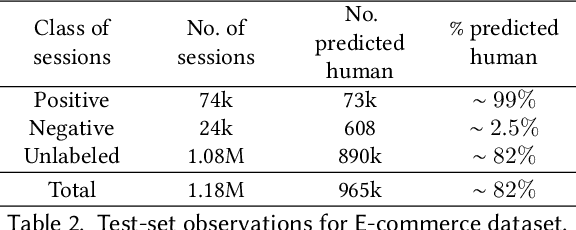
Malicious bots make up about a quarter of all traffic on the web, and degrade the performance of personalization and recommendation algorithms that operate on e-commerce sites. Positive-Unlabeled learning (PU learning) provides the ability to train a binary classifier using only positive (P) and unlabeled (U) instances. The unlabeled data comprises of both positive and negative classes. It is possible to find labels for strict subsets of non-malicious actors, e.g., the assumption that only humans purchase during web sessions, or clear CAPTCHAs. However, finding signals of malicious behavior is almost impossible due to the ever-evolving and adversarial nature of bots. Such a set-up naturally lends itself to PU learning. Unfortunately, standard PU learning approaches assume that the labeled set of positives are a random sample of all positives, this is unlikely to hold in practice. In this work, we propose two modifications to PU learning that make it more robust to violations of the selected-completely-at-random assumption, leading to a system that can filter out malicious bots. In one public and one proprietary dataset, we show that proposed approaches are better at identifying humans in web data than standard PU learning methods.