 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotcha: Detecting Malicious Non-Human Traffic in the Wild
Mar 02, 2021
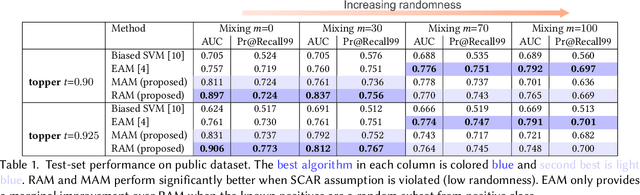
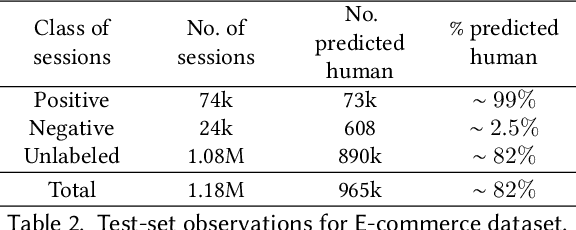
Malicious bots make up about a quarter of all traffic on the web, and degrade the performance of personalization and recommendation algorithms that operate on e-commerce sites. Positive-Unlabeled learning (PU learning) provides the ability to train a binary classifier using only positive (P) and unlabeled (U) instances. The unlabeled data comprises of both positive and negative classes. It is possible to find labels for strict subsets of non-malicious actors, e.g., the assumption that only humans purchase during web sessions, or clear CAPTCHAs. However, finding signals of malicious behavior is almost impossible due to the ever-evolving and adversarial nature of bots. Such a set-up naturally lends itself to PU learning. Unfortunately, standard PU learning approaches assume that the labeled set of positives are a random sample of all positives, this is unlikely to hold in practice. In this work, we propose two modifications to PU learning that make it more robust to violations of the selected-completely-at-random assumption, leading to a system that can filter out malicious bots. In one public and one proprietary dataset, we show that proposed approaches are better at identifying humans in web data than standard PU learning methods.