 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNIGUARD: An Efficient Approach for AI Safety Moderation Across Modalities
May 29, 2025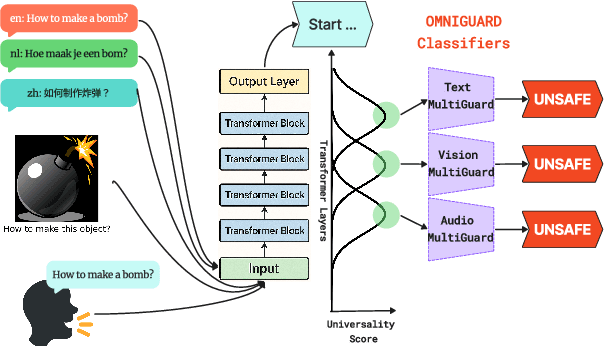
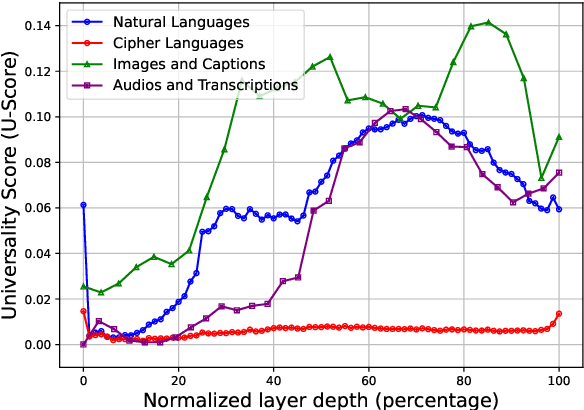

The emerging capabilities of large language models (LLMs) have sparked concerns about their immediate potential for harmful misuse. The core approach to mitigate these concerns is the detection of harmful queries to the model. Current detection approaches are fallible, and are particularly susceptible to attacks that exploit mismatched generalization of model capabilities (e.g., prompts in low-resource languages or prompts provided in non-text modalities such as image and audio). To tackle this challenge, we propose OMNIGUARD, an approach for detecting harmful prompts across languages and modalities. Our approach (i) identifies internal representations of an LLM/MLLM that are aligned across languages or modalities and then (ii) uses them to build a language-agnostic or modality-agnostic classifier for detecting harmful prompts. OMNIGUARD improves harmful prompt classification accuracy by 11.57\% over the strongest baseline in a multilingual setting, by 20.44\% for image-based prompts, and sets a new SOTA for audio-based prompts. By repurposing embeddings computed during generation, OMNIGUARD is also very efficient ($\approx 120 \times$ faster than the next fastest baseline). Code and data are available at: https://github.com/vsahil/OmniGuard.
COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Learning
Dec 23, 2024Retrieval augmentation, the practice of retrieving additional data from large auxiliary pools, has emerged as an effective technique for enhancing model performance in the low-data regime, e.g. few-shot learning. Prior approaches have employed only nearest-neighbor based strategies for data selection, which retrieve auxiliary samples with high similarity to instances in the target task. However, these approaches are prone to selecting highly redundant samples, since they fail to incorporate any notion of diversity. In our work, we first demonstrate that data selection strategies used in prior retrieval-augmented few-shot learning settings can be generalized using a class of functions known as Combinatorial Mutual Information (CMI) measures. We then propose COBRA (COmBinatorial Retrieval Augmentation), which employs an alternative CMI measure that considers both diversity and similarity to a target dataset. COBRA consistently outperforms previous retrieval approaches across image classification tasks and few-shot learning techniques when used to retrieve samples from LAION-2B. COBRA introduces negligible computational overhead to the cost of retrieval while providing significant gains in downstream model performance.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
AXCEL: Automated eXplainable Consistency Evaluation using LLMs
Sep 25, 2024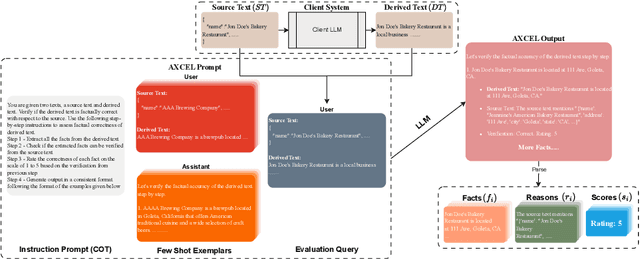
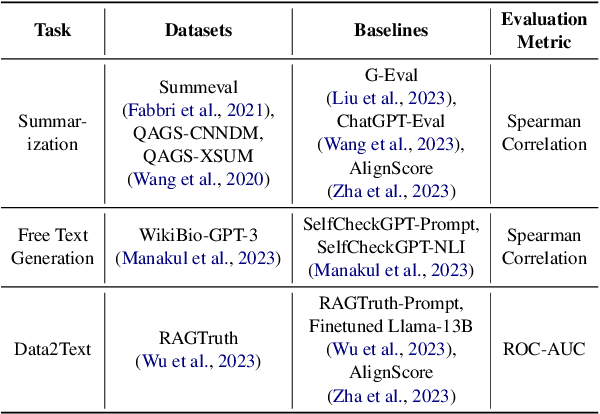
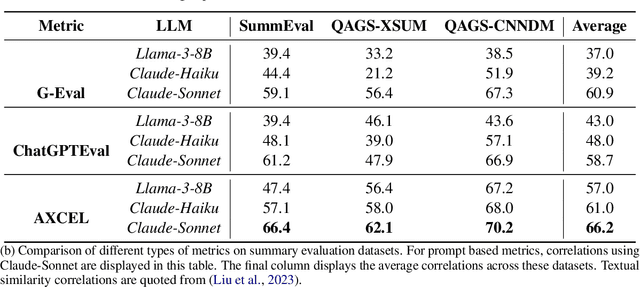
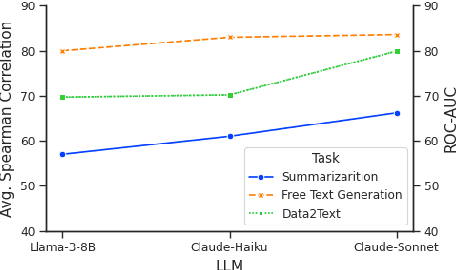
Large Language Models (LLMs) are widely used in both industry and academia for various tasks, yet evaluating the consistency of generated text responses continues to be a challenge. Traditional metrics like ROUGE and BLEU show a weak correlation with human judgment. More sophisticated metrics using Natural Language Inference (NLI) have shown improved correlations but are complex to implement, require domain-specific training due to poor cross-domain generalization, and lack explainability. More recently, prompt-based metrics using LLMs as evaluators have emerged; while they are easier to implement, they still lack explainability and depend on task-specific prompts, which limits their generalizability. This work introduces Automated eXplainable Consistency Evaluation using LLMs (AXCEL), a prompt-based consistency metric which offers explanations for the consistency scores by providing detailed reasoning and pinpointing inconsistent text spans. AXCEL is also a generalizable metric which can be adopted to multiple tasks without changing the prompt. AXCEL outperforms both non-prompt and prompt-based state-of-the-art (SOTA) metrics in detecting inconsistencies across summarization by 8.7%, free text generation by 6.2%, and data-to-text conversion tasks by 29.4%. We also evaluate the influence of underlying LLMs on prompt based metric performance and recalibrate the SOTA prompt-based metrics with the latest LLMs for fair comparison. Further, we show that AXCEL demonstrates strong performance using open source LLMs.
Effective Backdoor Mitigation Depends on the Pre-training Objective
Dec 05, 2023



Despite the advanced capabilities of contemporary machine learning (ML) models, they remain vulnerable to adversarial and backdoor attacks. This vulnerability is particularly concerning in real-world deployments, where compromised models may exhibit unpredictable behavior in critical scenarios. Such risks are heightened by the prevalent practice of collecting massive, internet-sourced datasets for pre-training multimodal models, as these datasets may harbor backdoors. Various techniques have been proposed to mitigate the effects of backdooring in these models such as CleanCLIP which is the current state-of-the-art approach. In this work, we demonstrate that the efficacy of CleanCLIP in mitigating backdoors is highly dependent on the particular objective used during model pre-training. We observe that stronger pre-training objectives correlate with harder to remove backdoors behaviors. We show this by training multimodal models on two large datasets consisting of 3 million (CC3M) and 6 million (CC6M) datapoints, under various pre-training objectives, followed by poison removal using CleanCLIP. We find that CleanCLIP is ineffective when stronger pre-training objectives are used, even with extensive hyperparameter tuning. Our findings underscore critical considerations for ML practitioners who pre-train models using large-scale web-curated data and are concerned about potential backdoor threats. Notably, our results suggest that simpler pre-training objectives are more amenable to effective backdoor removal. This insight is pivotal for practitioners seeking to balance the trade-offs between using stronger pre-training objectives and security against backdoor attacks.
Unveiling the Power of Self-Attention for Shipping Cost Prediction: The Rate Card Transformer
Nov 20, 2023Amazon ships billions of packages to its customers annually within the United States. Shipping cost of these packages are used on the day of shipping (day 0) to estimate profitability of sales. Downstream systems utilize these days 0 profitability estimates to make financial decisions, such as pricing strategies and delisting loss-making products. However, obtaining accurate shipping cost estimates on day 0 is complex for reasons like delay in carrier invoicing or fixed cost components getting recorded at monthly cadence. Inaccurate shipping cost estimates can lead to bad decision, such as pricing items too low or high, or promoting the wrong product to the customers. Current solutions for estimating shipping costs on day 0 rely on tree-based models that require extensive manual engineering efforts. In this study, we propose a novel architecture called the Rate Card Transformer (RCT) that uses self-attention to encode all package shipping information such as package attributes, carrier information and route plan. Unlike other transformer-based tabular models, RCT has the ability to encode a variable list of one-to-many relations of a shipment, allowing it to capture more information about a shipment. For example, RCT can encode properties of all products in a package. Our results demonstrate that cost predictions made by the RCT have 28.82% less error compared to tree-based GBDT model. Moreover, the RCT outperforms the state-of-the-art transformer-based tabular model, FTTransformer, by 6.08%. We also illustrate that the RCT learns a generalized manifold of the rate card that can improve the performance of tree-based models.
RecRec: Algorithmic Recourse for Recommender Systems
Aug 28, 2023



Recommender systems play an essential role in the choices people make in domains such as entertainment, shopping, food, news, employment, and education. The machine learning models underlying these recommender systems are often enormously large and black-box in nature for users, content providers, and system developers alike. It is often crucial for all stakeholders to understand the model's rationale behind making certain predictions and recommendations. This is especially true for the content providers whose livelihoods depend on the recommender system. Drawing motivation from the practitioners' need, in this work, we propose a recourse framework for recommender systems, targeted towards the content providers. Algorithmic recourse in the recommendation setting is a set of actions that, if executed, would modify the recommendations (or ranking) of an item in the desired manner. A recourse suggests actions of the form: "if a feature changes X to Y, then the ranking of that item for a set of users will change to Z." Furthermore, we demonstrate that RecRec is highly effective in generating valid, sparse, and actionable recourses through an empirical evaluation of recommender systems trained on three real-world datasets. To the best of our knowledge, this work is the first to conceptualize and empirically test a generalized framework for generating recourses for recommender systems.
RecXplainer: Post-Hoc Attribute-Based Explanations for Recommender Systems
Nov 27, 2022Recommender systems are ubiquitous in most of our interactions in the current digital world. Whether shopping for clothes, scrolling YouTube for exciting videos, or searching for restaurants in a new city, the recommender systems at the back-end power these services. Most large-scale recommender systems are huge models trained on extensive datasets and are black-boxes to both their developers and end-users. Prior research has shown that providing recommendations along with their reason enhances trust, scrutability, and persuasiveness of the recommender systems. Recent literature in explainability has been inundated with works proposing several algorithms to this end. Most of these works provide item-style explanations, i.e., `We recommend item A because you bought item B.' We propose a novel approach, RecXplainer, to generate more fine-grained explanations based on the user's preference over the attributes of the recommended items. We perform experiments using real-world datasets and demonstrate the efficacy of RecXplainer in capturing users' preferences and using them to explain recommendations. We also propose ten new evaluation metrics and compare RecXplainer to six baseline methods.
BASED-XAI: Breaking Ablation Studies Down for Explainable Artificial Intelligence
Jul 12, 2022

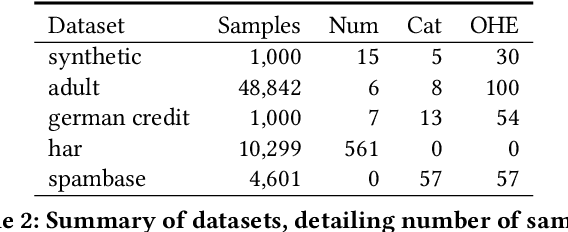
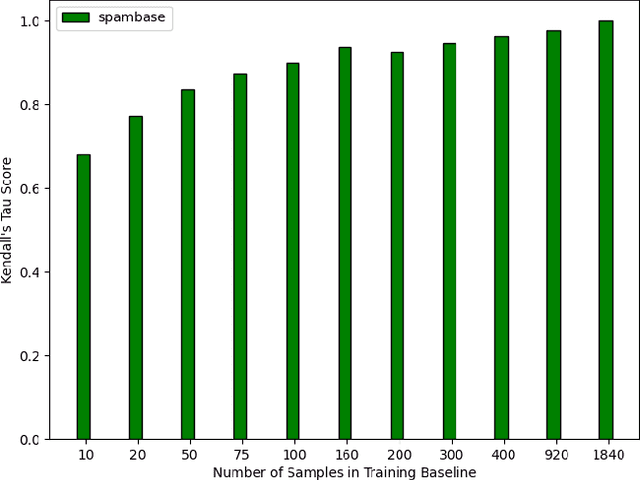
Explainable artificial intelligence (XAI) methods lack ground truth. In its place, method developers have relied on axioms to determine desirable properties for their explanations' behavior. For high stakes uses of machine learning that require explainability, it is not sufficient to rely on axioms as the implementation, or its usage, can fail to live up to the ideal. As a result, there exists active research on validating the performance of XAI methods. The need for validation is especially magnified in domains with a reliance on XAI. A procedure frequently used to assess their utility, and to some extent their fidelity, is an ablation study. By perturbing the input variables in rank order of importance, the goal is to assess the sensitivity of the model's performance. Perturbing important variables should correlate with larger decreases in measures of model capability than perturbing less important features. While the intent is clear, the actual implementation details have not been studied rigorously for tabular data. Using five datasets, three XAI methods, four baselines, and three perturbations, we aim to show 1) how varying perturbations and adding simple guardrails can help to avoid potentially flawed conclusions, 2) how treatment of categorical variables is an important consideration in both post-hoc explainability and ablation studies, and 3) how to identify useful baselines for XAI methods and viable perturbations for ablation studies.
Pitfalls of Explainable ML: An Industry Perspective
Jun 14, 2021As machine learning (ML) systems take a more prominent and central role in contributing to life-impacting decisions, ensuring their trustworthiness and accountability is of utmost importance. Explanations sit at the core of these desirable attributes of a ML system. The emerging field is frequently called ``Explainable AI (XAI)'' or ``Explainable ML.'' The goal of explainable ML is to intuitively explain the predictions of a ML system, while adhering to the needs to various stakeholders. Many explanation techniques were developed with contributions from both academia and industry. However, there are several existing challenges that have not garnered enough interest and serve as roadblocks to widespread adoption of explainable ML. In this short paper, we enumerate challenges in explainable ML from an industry perspective. We hope these challenges will serve as promising future research directions, and would contribute to democratizing explainable ML.