 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pretraining for Partial Differential Equations
Jul 03, 2024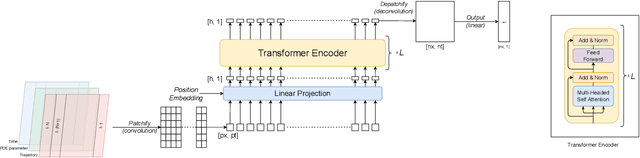
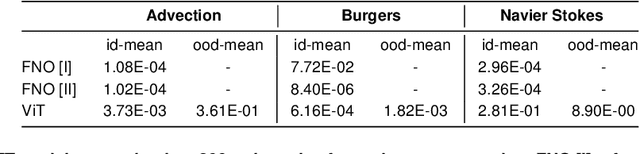
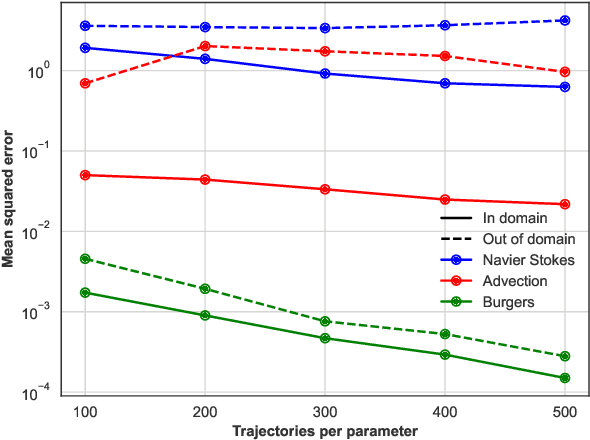

In this work, we describe a novel approach to building a neural PDE solver leveraging recent advances in transformer based neural network architectures. Our model can provide solutions for different values of PDE parameters without any need for retraining the network. The training is carried out in a self-supervised manner, similar to pretraining approaches applied in language and vision tasks. We hypothesize that the model is in effect learning a family of operators (for multiple parameters) mapping the initial condition to the solution of the PDE at any future time step t. We compare this approach with the Fourier Neural Operator (FNO), and demonstrate that it can generalize over the space of PDE parameters, despite having a higher prediction error for individual parameter values compared to the FNO. We show that performance on a specific parameter can be improved by finetuning the model with very small amounts of data. We also demonstrate that the model scales with data as well as model size.
Unveiling the Power of Self-Attention for Shipping Cost Prediction: The Rate Card Transformer
Nov 20, 2023Amazon ships billions of packages to its customers annually within the United States. Shipping cost of these packages are used on the day of shipping (day 0) to estimate profitability of sales. Downstream systems utilize these days 0 profitability estimates to make financial decisions, such as pricing strategies and delisting loss-making products. However, obtaining accurate shipping cost estimates on day 0 is complex for reasons like delay in carrier invoicing or fixed cost components getting recorded at monthly cadence. Inaccurate shipping cost estimates can lead to bad decision, such as pricing items too low or high, or promoting the wrong product to the customers. Current solutions for estimating shipping costs on day 0 rely on tree-based models that require extensive manual engineering efforts. In this study, we propose a novel architecture called the Rate Card Transformer (RCT) that uses self-attention to encode all package shipping information such as package attributes, carrier information and route plan. Unlike other transformer-based tabular models, RCT has the ability to encode a variable list of one-to-many relations of a shipment, allowing it to capture more information about a shipment. For example, RCT can encode properties of all products in a package. Our results demonstrate that cost predictions made by the RCT have 28.82% less error compared to tree-based GBDT model. Moreover, the RCT outperforms the state-of-the-art transformer-based tabular model, FTTransformer, by 6.08%. We also illustrate that the RCT learns a generalized manifold of the rate card that can improve the performance of tree-based models.
Clarifying Trust of Materials Property Predictions using Neural Networks with Distribution-Specific Uncertainty Quantification
Feb 06, 2023It is critical that machine learning (ML) model predictions be trustworthy for high-throughput catalyst discovery approaches. Uncertainty quantification (UQ) methods allow estimation of the trustworthiness of an ML model, but these methods have not been well explored in the field of heterogeneous catalysis. Herein, we investigate different UQ methods applied to a crystal graph convolutional neural network (CGCNN) to predict adsorption energies of molecules on alloys from the Open Catalyst 2020 (OC20) dataset, the largest existing heterogeneous catalyst dataset. We apply three UQ methods to the adsorption energy predictions, namely k-fold ensembling, Monte Carlo dropout, and evidential regression. The effectiveness of each UQ method is assessed based on accuracy, sharpness, dispersion, calibration, and tightness. Evidential regression is demonstrated to be a powerful approach for rapidly obtaining tunable, competitively trustworthy UQ estimates for heterogeneous catalysis applications when using neural networks. Recalibration of model uncertainties is shown to be essential in practical screening applications of catalysts using uncertainties.
Deep Learning-based Spatially Explicit Emulation of an Agent-Based Simulator for Pandemic in a City
May 28, 2022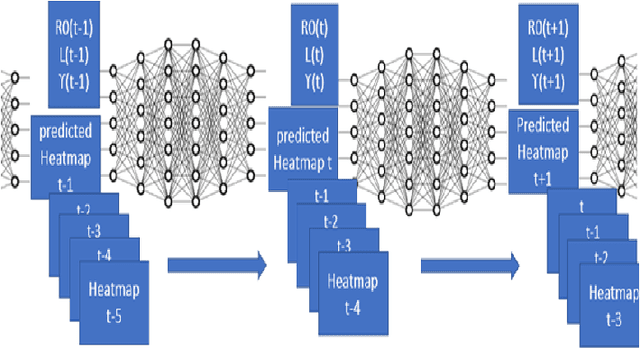

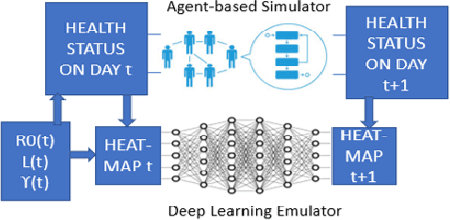

Agent-Based Models are very useful for simulation of physical or social processes, such as the spreading of a pandemic in a city. Such models proceed by specifying the behavior of individuals (agents) and their interactions, and parameterizing the process of infection based on such interactions based on the geography and demography of the city. However, such models are computationally very expensive, and the complexity is often linear in the total number of agents. This seriously limits the usage of such models for simulations, which often have to be run hundreds of times for policy planning and even model parameter estimation. An alternative is to develop an emulator, a surrogate model that can predict the Agent-Based Simulator's output based on its initial conditions and parameters. In this paper, we discuss a Deep Learning model based on Dilated Convolutional Neural Network that can emulate such an agent based model with high accuracy. We show that use of this model instead of the original Agent-Based Model provides us major gains in the speed of simulations, allowing much quicker calibration to observations, and more extensive scenario analysis. The models we consider are spatially explicit, as the locations of the infected individuals are simulated instead of the gross counts. Another aspect of our emulation framework is its divide-and-conquer approach that divides the city into several small overlapping blocks and carries out the emulation in them parallelly, after which these results are merged together. This ensures that the same emulator can work for a city of any size, and also provides significant improvement of time complexity of the emulator, compared to the original simulator.
AI Poincaré 2.0: Machine Learning Conservation Laws from Differential Equations
Mar 23, 2022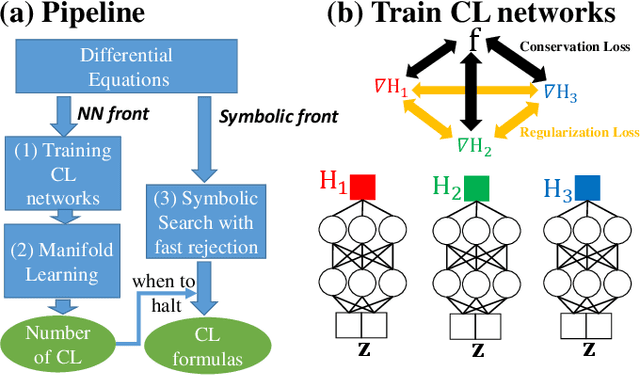
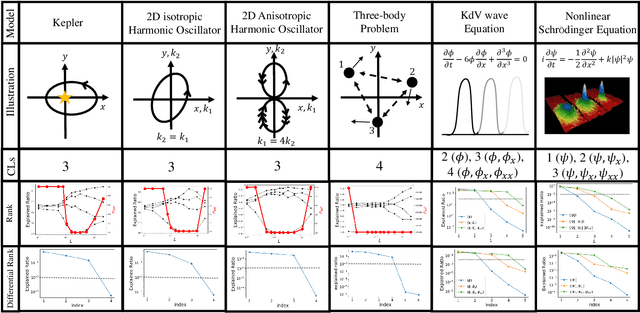
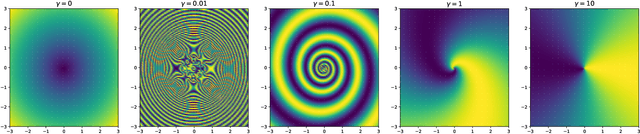
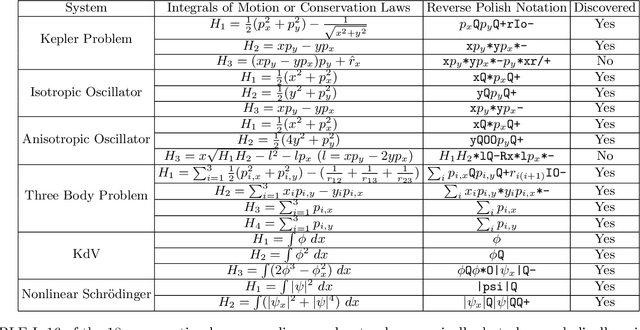
We present a machine learning algorithm that discovers conservation laws from differential equations, both numerically (parametrized as neural networks) and symbolically, ensuring their functional independence (a non-linear generalization of linear independence). Our independence module can be viewed as a nonlinear generalization of singular value decomposition. Our method can readily handle inductive biases for conservation laws. We validate it with examples including the 3-body problem, the KdV equation and nonlinear Schr\"odinger equation.
Team Enigma at ArgMining-EMNLP 2021: Leveraging Pre-trained Language Models for Key Point Matching
Oct 24, 2021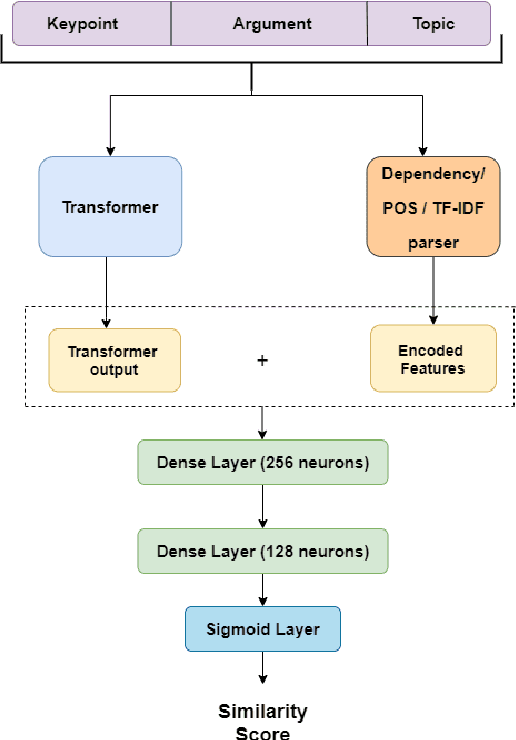
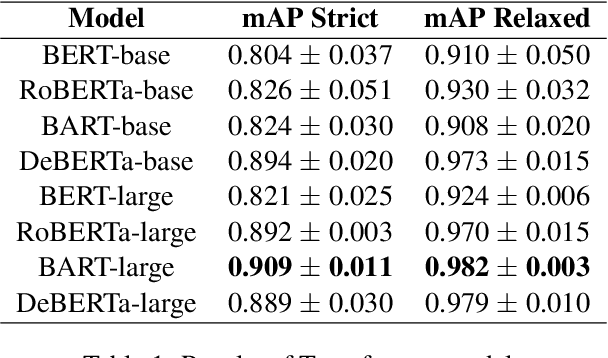
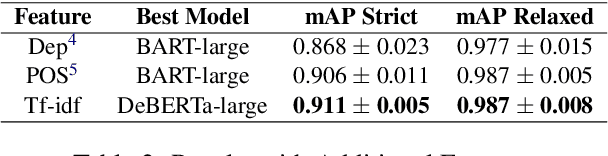
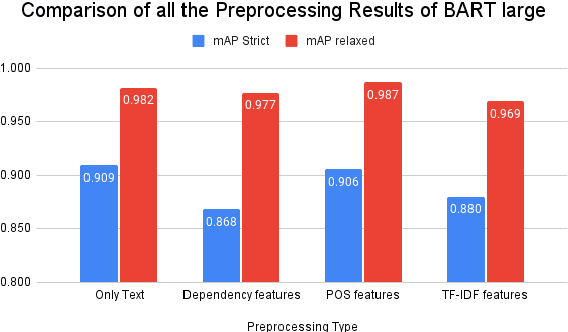
We present the system description for our submission towards the Key Point Analysis Shared Task at ArgMining 2021. Track 1 of the shared task requires participants to develop methods to predict the match score between each pair of arguments and keypoints, provided they belong to the same topic under the same stance. We leveraged existing state of the art pre-trained language models along with incorporating additional data and features extracted from the inputs (topics, key points, and arguments) to improve performance. We were able to achieve mAP strict and mAP relaxed score of 0.872 and 0.966 respectively in the evaluation phase, securing 5th place on the leaderboard. In the post evaluation phase, we achieved a mAP strict and mAP relaxed score of 0.921 and 0.982 respectively. All the codes to generate reproducible results on our models are available on Github.
Leveraging recent advances in Pre-Trained Language Models forEye-Tracking Prediction
Oct 09, 2021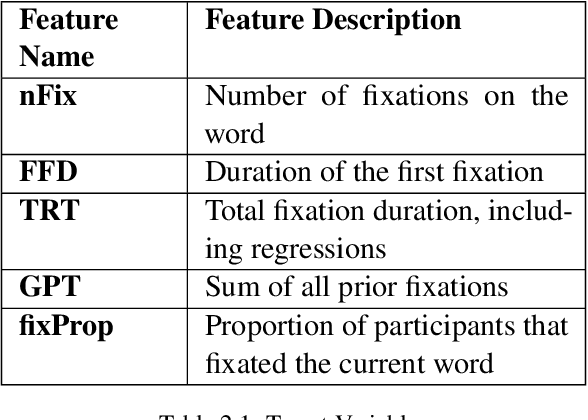
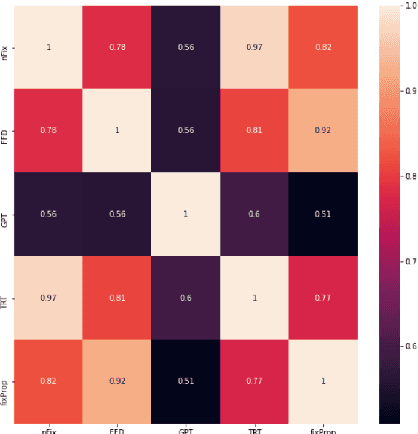
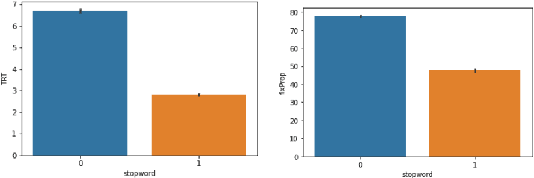
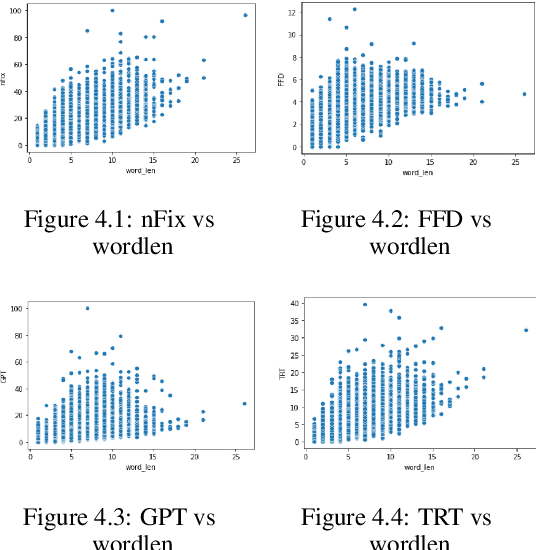
Cognitively inspired Natural Language Pro-cessing uses human-derived behavioral datalike eye-tracking data, which reflect the seman-tic representations of language in the humanbrain to augment the neural nets to solve arange of tasks spanning syntax and semanticswith the aim of teaching machines about lan-guage processing mechanisms. In this paper,we use the ZuCo 1.0 and ZuCo 2.0 dataset con-taining the eye-gaze features to explore differ-ent linguistic models to directly predict thesegaze features for each word with respect to itssentence. We tried different neural networkmodels with the words as inputs to predict thetargets. And after lots of experimentation andfeature engineering finally devised a novel ar-chitecture consisting of RoBERTa Token Clas-sifier with a dense layer on top for languagemodeling and a stand-alone model consistingof dense layers followed by a transformer layerfor the extra features we engineered. Finally,we took the mean of the outputs of both thesemodels to make the final predictions. We eval-uated the models using mean absolute error(MAE) and the R2 score for each target.