 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB'MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory
Jul 08, 2024We describe a family of architectures to support transductive inference by allowing memory to grow to a finite but a-priori unknown bound while making efficient use of finite resources for inference. Current architectures use such resources to represent data either eidetically over a finite span ("context" in Transformers), or fading over an infinite span (in State Space Models, or SSMs). Recent hybrid architectures have combined eidetic and fading memory, but with limitations that do not allow the designer or the learning process to seamlessly modulate the two, nor to extend the eidetic memory span. We leverage ideas from Stochastic Realization Theory to develop a class of models called B'MOJO to seamlessly combine eidetic and fading memory within an elementary composable module. The overall architecture can be used to implement models that can access short-term eidetic memory "in-context," permanent structural memory "in-weights," fading memory "in-state," and long-term eidetic memory "in-storage" by natively incorporating retrieval from an asynchronously updated memory. We show that Transformers, existing SSMs such as Mamba, and hybrid architectures such as Jamba are special cases of B'MOJO and describe a basic implementation, to be open sourced, that can be stacked and scaled efficiently in hardware. We test B'MOJO on transductive inference tasks, such as associative recall, where it outperforms existing SSMs and Hybrid models; as a baseline, we test ordinary language modeling where B'MOJO achieves perplexity comparable to similarly-sized Transformers and SSMs up to 1.4B parameters, while being up to 10% faster to train. Finally, we show that B'MOJO's ability to modulate eidetic and fading memory results in better inference on longer sequences tested up to 32K tokens, four-fold the length of the longest sequences seen during training.
Diffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.
Re-visiting Skip-Gram Negative Sampling: Dimension Regularization for More Efficient Dissimilarity Preservation in Graph Embeddings
Apr 30, 2024



A wide range of graph embedding objectives decompose into two components: one that attracts the embeddings of nodes that are perceived as similar, and another that repels embeddings of nodes that are perceived as dissimilar. Because real-world graphs are sparse and the number of dissimilar pairs grows quadratically with the number of nodes, Skip-Gram Negative Sampling (SGNS) has emerged as a popular and efficient repulsion approach. SGNS repels each node from a sample of dissimilar nodes, as opposed to all dissimilar nodes. In this work, we show that node-wise repulsion is, in aggregate, an approximate re-centering of the node embedding dimensions. Such dimension operations are much more scalable than node operations. The dimension approach, in addition to being more efficient, yields a simpler geometric interpretation of the repulsion. Our result extends findings from the self-supervised learning literature to the skip-gram model, establishing a connection between skip-gram node contrast and dimension regularization. We show that in the limit of large graphs, under mild regularity conditions, the original node repulsion objective converges to optimization with dimension regularization. We use this observation to propose an algorithm augmentation framework that speeds up any existing algorithm, supervised or unsupervised, using SGNS. The framework prioritizes node attraction and replaces SGNS with dimension regularization. We instantiate this generic framework for LINE and node2vec and show that the augmented algorithms preserve downstream performance while dramatically increasing efficiency.
Learning Rich Rankings
Dec 22, 2023
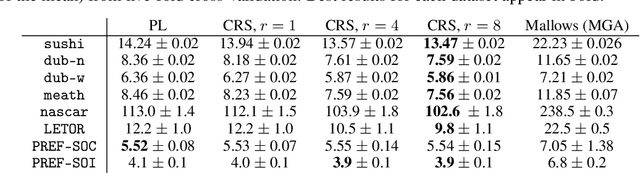
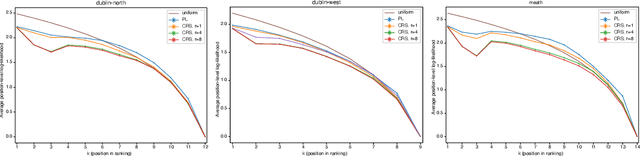
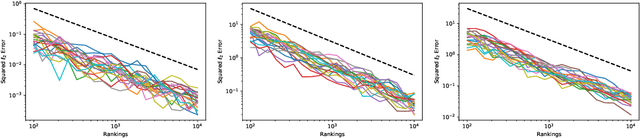
Although the foundations of ranking are well established, the ranking literature has primarily been focused on simple, unimodal models, e.g. the Mallows and Plackett-Luce models, that define distributions centered around a single total ordering. Explicit mixture models have provided some tools for modelling multimodal ranking data, though learning such models from data is often difficult. In this work, we contribute a contextual repeated selection (CRS) model that leverages recent advances in choice modeling to bring a natural multimodality and richness to the rankings space. We provide rigorous theoretical guarantees for maximum likelihood estimation under the model through structure-dependent tail risk and expected risk bounds. As a by-product, we also furnish the first tight bounds on the expected risk of maximum likelihood estimators for the multinomial logit (MNL) choice model and the Plackett-Luce (PL) ranking model, as well as the first tail risk bound on the PL ranking model. The CRS model significantly outperforms existing methods for modeling real world ranking data in a variety of settings, from racing to rank choice voting.
HandsOff: Labeled Dataset Generation With No Additional Human Annotations
Dec 24, 2022Recent work leverages the expressive power of generative adversarial networks (GANs) to generate labeled synthetic datasets. These dataset generation methods often require new annotations of synthetic images, which forces practitioners to seek out annotators, curate a set of synthetic images, and ensure the quality of generated labels. We introduce the HandsOff framework, a technique capable of producing an unlimited number of synthetic images and corresponding labels after being trained on less than 50 pre-existing labeled images. Our framework avoids the practical drawbacks of prior work by unifying the field of GAN inversion with dataset generation. We generate datasets with rich pixel-wise labels in multiple challenging domains such as faces, cars, full-body human poses, and urban driving scenes. Our method achieves state-of-the-art performance in semantic segmentation, keypoint detection, and depth estimation compared to prior dataset generation approaches and transfer learning baselines. We additionally showcase its ability to address broad challenges in model development which stem from fixed, hand-annotated datasets, such as the long-tail problem in semantic segmentation.
RecXplainer: Post-Hoc Attribute-Based Explanations for Recommender Systems
Nov 27, 2022Recommender systems are ubiquitous in most of our interactions in the current digital world. Whether shopping for clothes, scrolling YouTube for exciting videos, or searching for restaurants in a new city, the recommender systems at the back-end power these services. Most large-scale recommender systems are huge models trained on extensive datasets and are black-boxes to both their developers and end-users. Prior research has shown that providing recommendations along with their reason enhances trust, scrutability, and persuasiveness of the recommender systems. Recent literature in explainability has been inundated with works proposing several algorithms to this end. Most of these works provide item-style explanations, i.e., `We recommend item A because you bought item B.' We propose a novel approach, RecXplainer, to generate more fine-grained explanations based on the user's preference over the attributes of the recommended items. We perform experiments using real-world datasets and demonstrate the efficacy of RecXplainer in capturing users' preferences and using them to explain recommendations. We also propose ten new evaluation metrics and compare RecXplainer to six baseline methods.
Contrastive Learning for Interactive Recommendation in Fashion
Jul 25, 2022
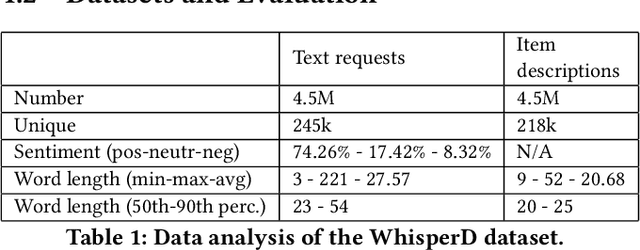
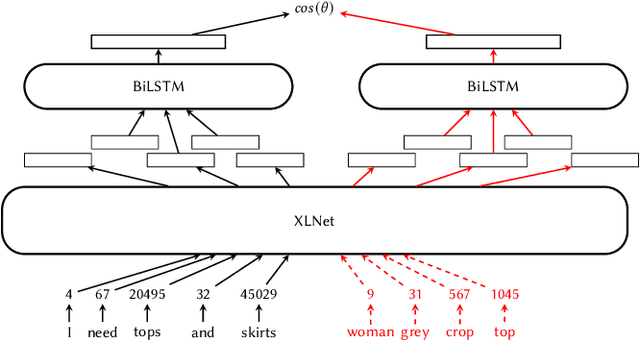
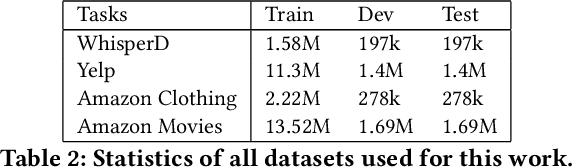
Recommender systems and search are both indispensable in facilitating personalization and ease of browsing in online fashion platforms. However, the two tools often operate independently, failing to combine the strengths of recommender systems to accurately capture user tastes with search systems' ability to process user queries. We propose a novel remedy to this problem by automatically recommending personalized fashion items based on a user-provided text request. Our proposed model, WhisperLite, uses contrastive learning to capture user intent from natural language text and improves the recommendation quality of fashion products. WhisperLite combines the strength of CLIP embeddings with additional neural network layers for personalization, and is trained using a composite loss function based on binary cross entropy and contrastive loss. The model demonstrates a significant improvement in offline recommendation retrieval metrics when tested on a real-world dataset collected from an online retail fashion store, as well as widely used open-source datasets in different e-commerce domains, such as restaurants, movies and TV shows, clothing and shoe reviews. We additionally conduct a user study that captures user judgements on the relevance of the model's recommended items, confirming the relevancy of WhisperLite's recommendations in an online setting.
Fundamental Limits of Testing the Independence of Irrelevant Alternatives in Discrete Choice
Jan 20, 2020The Multinomial Logit (MNL) model and the axiom it satisfies, the Independence of Irrelevant Alternatives (IIA), are together the most widely used tools of discrete choice. The MNL model serves as the workhorse model for a variety of fields, but is also widely criticized, with a large body of experimental literature claiming to document real-world settings where IIA fails to hold. Statistical tests of IIA as a modelling assumption have been the subject of many practical tests focusing on specific deviations from IIA over the past several decades, but the formal size properties of hypothesis testing IIA are still not well understood. In this work we replace some of the ambiguity in this literature with rigorous pessimism, demonstrating that any general test for IIA with low worst-case error would require a number of samples exponential in the number of alternatives of the choice problem. A major benefit of our analysis over previous work is that it lies entirely in the finite-sample domain, a feature crucial to understanding the behavior of tests in the common data-poor settings of discrete choice. Our lower bounds are structure-dependent, and as a potential cause for optimism, we find that if one restricts the test of IIA to violations that can occur in a specific collection of choice sets (e.g., pairs), one obtains structure-dependent lower bounds that are much less pessimistic. Our analysis of this testing problem is unorthodox in being highly combinatorial, counting Eulerian orientations of cycle decompositions of a particular bipartite graph constructed from a data set of choices. By identifying fundamental relationships between the comparison structure of a given testing problem and its sample efficiency, we hope these relationships will help lay the groundwork for a rigorous rethinking of the IIA testing problem as well as other testing problems in discrete choice.
Discovering Context Effects from Raw Choice Data
Feb 08, 2019
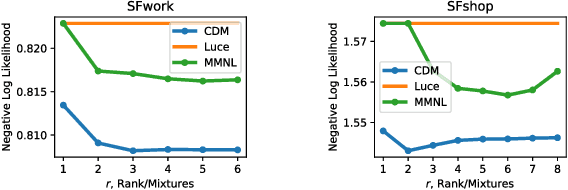
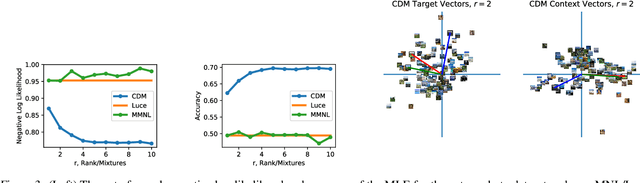
Many applications in preference learning assume that decisions come from the maximization of a stable utility function. Yet a large experimental literature shows that individual choices and judgements can be affected by "irrelevant" aspects of the context in which they are made. An important class of such contexts is the composition of the choice set. In this work, our goal is to discover such choice set effects from raw choice data. We introduce an extension of the Multinomial Logit (MNL) model, called the context dependent random utility model (CDM), which allows for a particular class of choice set effects. We show that the CDM can be thought of as a second-order approximation to a general choice system, can be inferred optimally using maximum likelihood and, importantly, is easily interpretable. We apply the CDM to both real and simulated choice data to perform principled exploratory analyses for the presence of choice set effects.