 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Feature Mapping Using a Collaborative Team of AUVs
Dec 27, 2024



We present the results of experiments performed using a team of small autonomous underwater vehicles (AUVs) to determine the location of an isobath. The primary contributions of this work are (1) the development of a novel objective function for level set estimation that utilizes a rigorous assessment of uncertainty, and (2) a description of the practical challenges and corresponding solutions needed to implement our approach in the field using a team of AUVs. We combine path planning techniques and an approach to decentralization from prior work that yields theoretical performance guarantees. Experimentation with a team of AUVs provides empirical evidence that the desirable performance guarantees can be preserved in practice even in the presence of limitations that commonly arise in underwater robotics, including slow and intermittent acoustic communications and limited computational resources.
Diffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.
ATHEENA: A Toolflow for Hardware Early-Exit Network Automation
Apr 17, 2023



The continued need for improvements in accuracy, throughput, and efficiency of Deep Neural Networks has resulted in a multitude of methods that make the most of custom architectures on FPGAs. These include the creation of hand-crafted networks and the use of quantization and pruning to reduce extraneous network parameters. However, with the potential of static solutions already well exploited, we propose to shift the focus to using the varying difficulty of individual data samples to further improve efficiency and reduce average compute for classification. Input-dependent computation allows for the network to make runtime decisions to finish a task early if the result meets a confidence threshold. Early-Exit network architectures have become an increasingly popular way to implement such behaviour in software. We create: A Toolflow for Hardware Early-Exit Network Automation (ATHEENA), an automated FPGA toolflow that leverages the probability of samples exiting early from such networks to scale the resources allocated to different sections of the network. The toolflow uses the data-flow model of fpgaConvNet, extended to support Early-Exit networks as well as Design Space Exploration to optimize the generated streaming architecture hardware with the goal of increasing throughput/reducing area while maintaining accuracy. Experimental results on three different networks demonstrate a throughput increase of $2.00\times$ to $2.78\times$ compared to an optimized baseline network implementation with no early exits. Additionally, the toolflow can achieve a throughput matching the same baseline with as low as $46\%$ of the resources the baseline requires.
Shape of You: Precise 3D shape estimations for diverse body types
Apr 14, 2023



This paper presents Shape of You (SoY), an approach to improve the accuracy of 3D body shape estimation for vision-based clothing recommendation systems. While existing methods have successfully estimated 3D poses, there remains a lack of work in precise shape estimation, particularly for diverse human bodies. To address this gap, we propose two loss functions that can be readily integrated into parametric 3D human reconstruction pipelines. Additionally, we propose a test-time optimization routine that further improves quality. Our method improves over the recent SHAPY method by 17.7% on the challenging SSP-3D dataset. We consider our work to be a step towards a more accurate 3D shape estimation system that works reliably on diverse body types and holds promise for practical applications in the fashion industry.
Experiments in Underwater Feature Tracking with Performance Guarantees Using a Small AUV
Oct 05, 2022

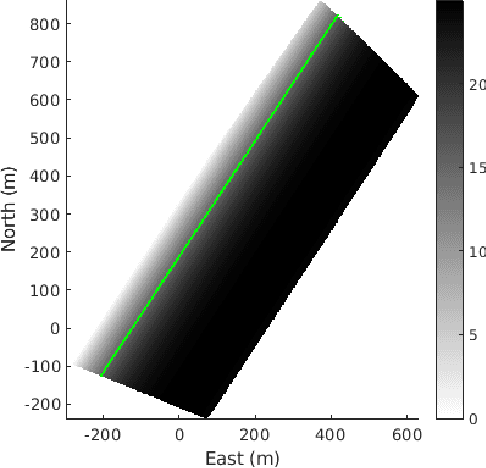
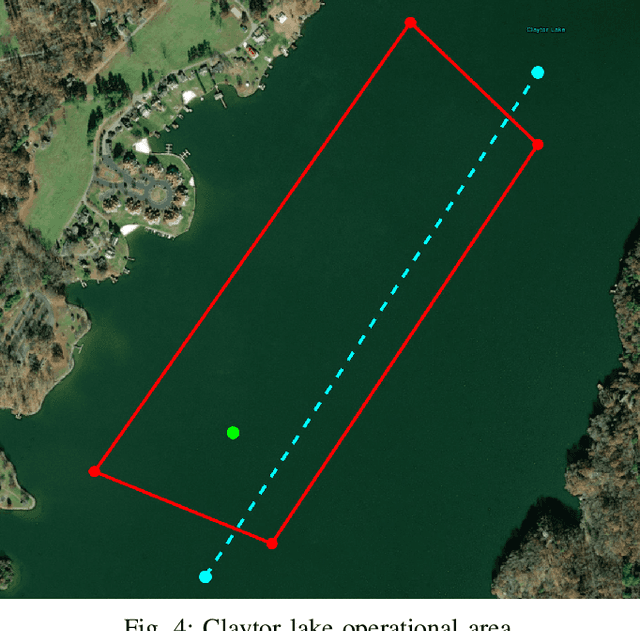
We present the results of experiments performed using a small autonomous underwater vehicle to determine the location of an isobath within a bounded area. The primary contribution of this work is to implement and integrate several recent developments real-time planning for environmental mapping, and to demonstrate their utility in a challenging practical example. We model the bathymetry within the operational area using a Gaussian process and propose a reward function that represents the task of mapping a desired isobath. As is common in applications where plans must be continually updated based on real-time sensor measurements, we adopt a receding horizon framework where the vehicle continually computes near-optimal paths. The sequence of paths does not, in general, inherit the optimality properties of each individual path. Our real-time planning implementation incorporates recent results that lead to performance guarantees for receding-horizon planning.
3D Multi-bodies: Fitting Sets of Plausible 3D Human Models to Ambiguous Image Data
Nov 02, 2020
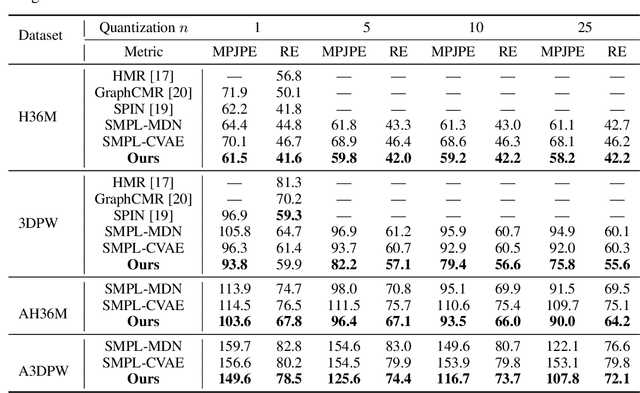

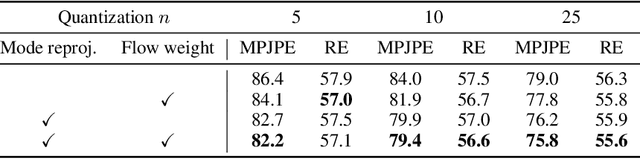
We consider the problem of obtaining dense 3D reconstructions of humans from single and partially occluded views. In such cases, the visual evidence is usually insufficient to identify a 3D reconstruction uniquely, so we aim at recovering several plausible reconstructions compatible with the input data. We suggest that ambiguities can be modelled more effectively by parametrizing the possible body shapes and poses via a suitable 3D model, such as SMPL for humans. We propose to learn a multi-hypothesis neural network regressor using a best-of-M loss, where each of the M hypotheses is constrained to lie on a manifold of plausible human poses by means of a generative model. We show that our method outperforms alternative approaches in ambiguous pose recovery on standard benchmarks for 3D humans, and in heavily occluded versions of these benchmarks.
Who Left the Dogs Out? 3D Animal Reconstruction with Expectation Maximization in the Loop
Jul 21, 2020
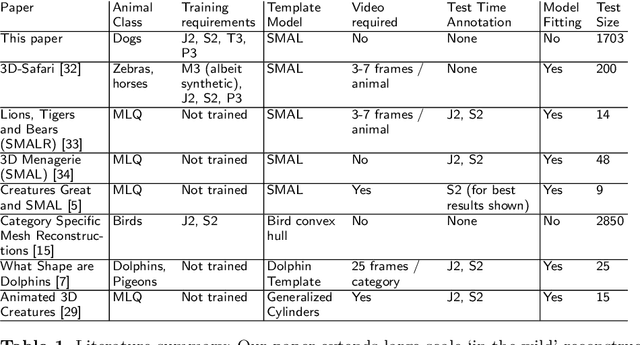
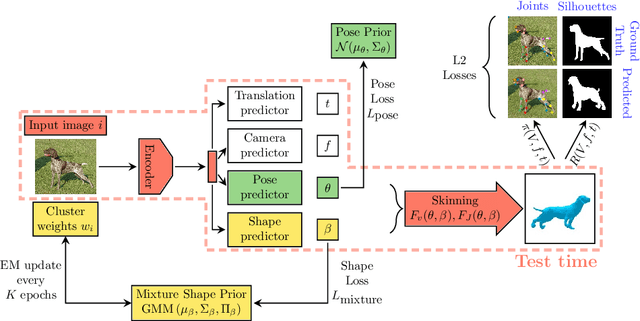
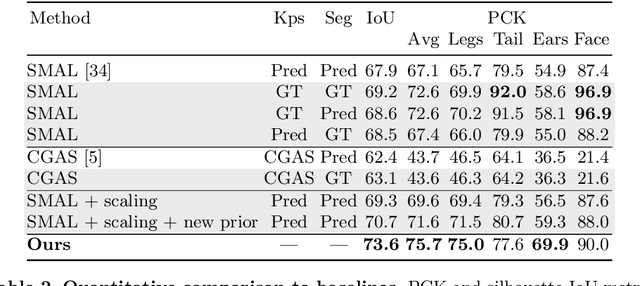
We introduce an automatic, end-to-end method for recovering the 3D pose and shape of dogs from monocular internet images. The large variation in shape between dog breeds, significant occlusion and low quality of internet images makes this a challenging problem. We learn a richer prior over shapes than previous work, which helps regularize parameter estimation. We demonstrate results on the Stanford Dog dataset, an 'in the wild' dataset of 20,580 dog images for which we have collected 2D joint and silhouette annotations to split for training and evaluation. In order to capture the large shape variety of dogs, we show that the natural variation in the 2D dataset is enough to learn a detailed 3D prior through expectation maximization (EM). As a by-product of training, we generate a new parameterized model (including limb scaling) SMBLD which we release alongside our new annotation dataset StanfordExtra to the research community.
Creatures great and SMAL: Recovering the shape and motion of animals from video
Nov 14, 2018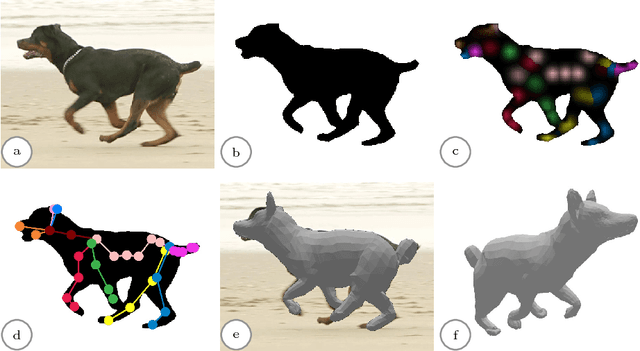

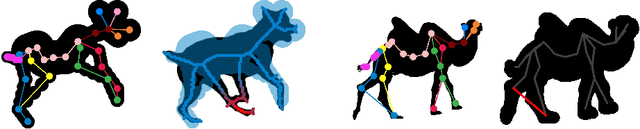
We present a system to recover the 3D shape and motion of a wide variety of quadrupeds from video. The system comprises a machine learning front-end which predicts candidate 2D joint positions, a discrete optimization which finds kinematically plausible joint correspondences, and an energy minimization stage which fits a detailed 3D model to the image. In order to overcome the limited availability of motion capture training data from animals, and the difficulty of generating realistic synthetic training images, the system is designed to work on silhouette data. The joint candidate predictor is trained on synthetically generated silhouette images, and at test time, deep learning methods or standard video segmentation tools are used to extract silhouettes from real data. The system is tested on animal videos from several species, and shows accurate reconstructions of 3D shape and pose.