 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State-Invariant Representations of Objects from Image Collections with State, Pose, and Viewpoint Changes
Apr 09, 2024

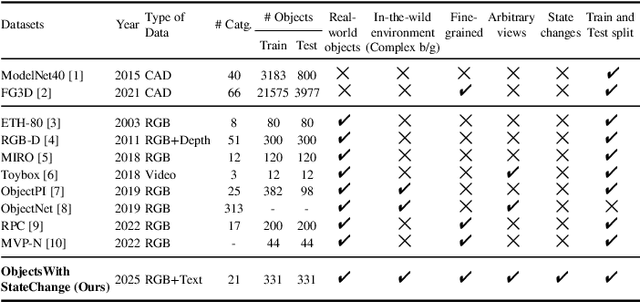
We add one more invariance - state invariance - to the more commonly used other invariances for learning object representations for recognition and retrieval. By state invariance, we mean robust with respect to changes in the structural form of the object, such as when an umbrella is folded, or when an item of clothing is tossed on the floor. Since humans generally have no difficulty in recognizing objects despite such state changes, we are naturally faced with the question of whether it is possible to devise a neural architecture with similar abilities. To that end, we present a novel dataset, ObjectsWithStateChange, that captures state and pose variations in the object images recorded from arbitrary viewpoints. We believe that this dataset will facilitate research in fine-grained object recognition and retrieval of objects that are capable of state changes. The goal of such research would be to train models capable of generating object embeddings that remain invariant to state changes while also staying invariant to transformations induced by changes in viewpoint, pose, illumination, etc. To demonstrate the usefulness of the ObjectsWithStateChange dataset, we also propose a curriculum learning strategy that uses the similarity relationships in the learned embedding space after each epoch to guide the training process. The model learns discriminative features by comparing visually similar objects within and across different categories, encouraging it to differentiate between objects that may be challenging to distinguish due to changes in their state. We believe that this strategy enhances the model's ability to capture discriminative features for fine-grained tasks that may involve objects with state changes, leading to performance improvements on object-level tasks not only on our new dataset, but also on two other challenging multi-view datasets such as ModelNet40 and ObjectPI.
Dual Pose-invariant Embeddings: Learning Category and Object-specific Discriminative Representations for Recognition and Retrieval
Mar 01, 2024
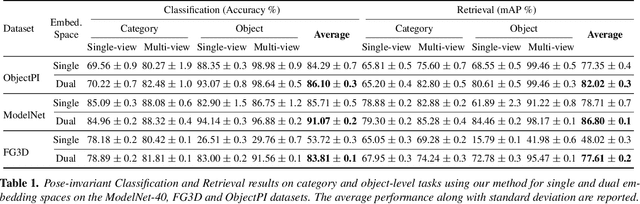

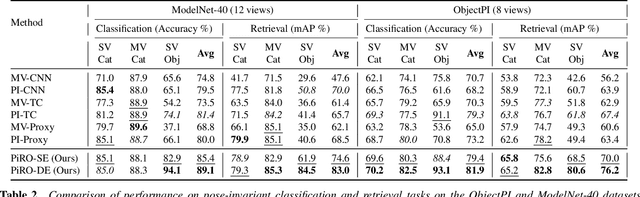
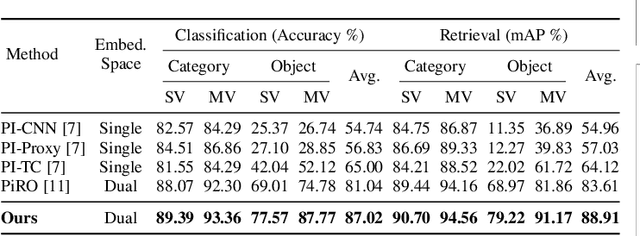
In the context of pose-invariant object recognition and retrieval, we demonstrate that it is possible to achieve significant improvements in performance if both the category-based and the object-identity-based embeddings are learned simultaneously during training. In hindsight, that sounds intuitive because learning about the categories is more fundamental than learning about the individual objects that correspond to those categories. However, to the best of what we know, no prior work in pose-invariant learning has demonstrated this effect. This paper presents an attention-based dual-encoder architecture with specially designed loss functions that optimize the inter- and intra-class distances simultaneously in two different embedding spaces, one for the category embeddings and the other for the object-level embeddings. The loss functions we have proposed are pose-invariant ranking losses that are designed to minimize the intra-class distances and maximize the inter-class distances in the dual representation spaces. We demonstrate the power of our approach with three challenging multi-view datasets, ModelNet-40, ObjectPI, and FG3D. With our dual approach, for single-view object recognition, we outperform the previous best by 20.0% on ModelNet40, 2.0% on ObjectPI, and 46.5% on FG3D. On the other hand, for single-view object retrieval, we outperform the previous best by 33.7% on ModelNet40, 18.8% on ObjectPI, and 56.9% on FG3D.
Shape of You: Precise 3D shape estimations for diverse body types
Apr 14, 2023



This paper presents Shape of You (SoY), an approach to improve the accuracy of 3D body shape estimation for vision-based clothing recommendation systems. While existing methods have successfully estimated 3D poses, there remains a lack of work in precise shape estimation, particularly for diverse human bodies. To address this gap, we propose two loss functions that can be readily integrated into parametric 3D human reconstruction pipelines. Additionally, we propose a test-time optimization routine that further improves quality. Our method improves over the recent SHAPY method by 17.7% on the challenging SSP-3D dataset. We consider our work to be a step towards a more accurate 3D shape estimation system that works reliably on diverse body types and holds promise for practical applications in the fashion industry.
OutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022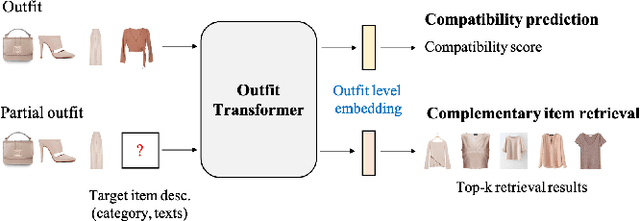

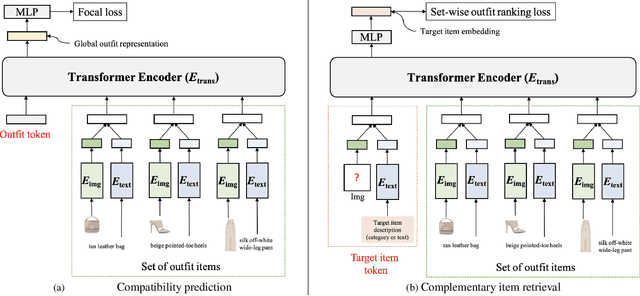
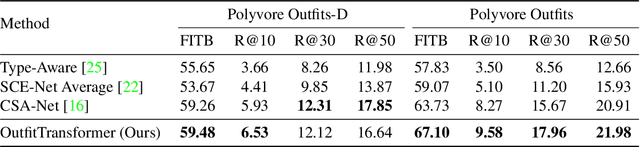
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.
CheckSoft : A Scalable Event-Driven Software Architecture for Keeping Track of People and Things in People-Centric Spaces
Feb 21, 2021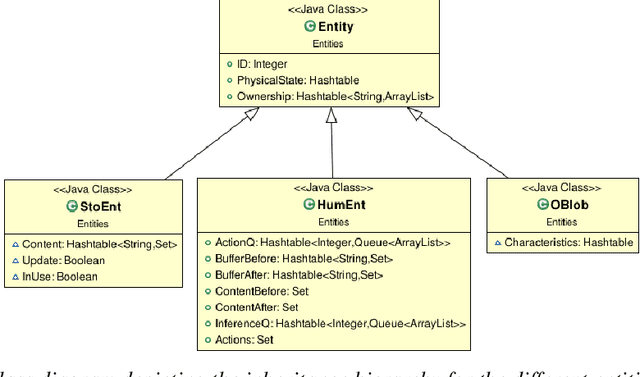
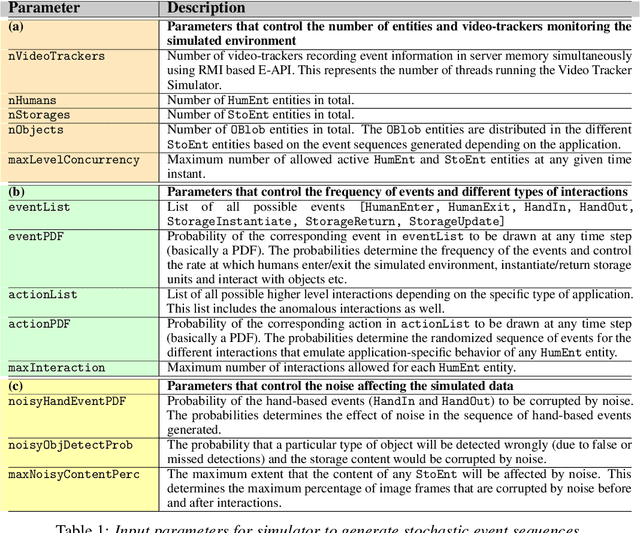
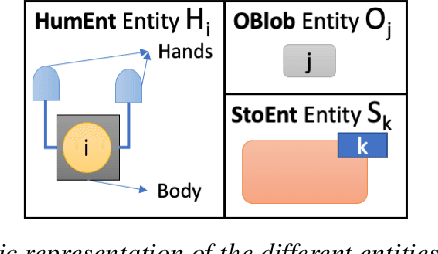
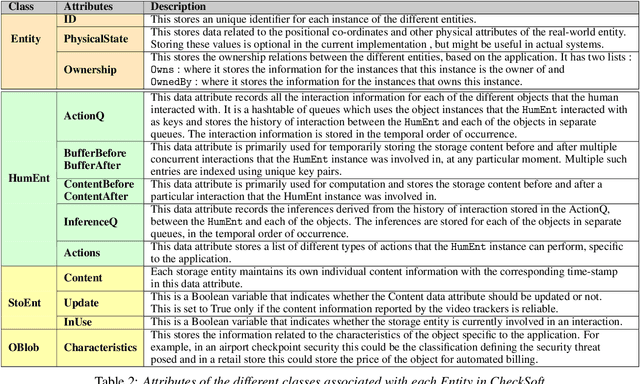
We present CheckSoft, a scalable event-driven software architecture for keeping track of people-object interactions in people-centric applications such as airport checkpoint security areas, automated retail stores, smart libraries, and so on. The architecture works off the video data generated in real time by a network of surveillance cameras. Although there are many different aspects to automating these applications, the most difficult part of the overall problem is keeping track of the interactions between the people and the objects. CheckSoft uses finite-state-machine (FSM) based logic for keeping track of such interactions which allows the system to quickly reject any false detections of the interactions by the video cameras. CheckSoft is easily scalable since the architecture is based on multi-processing in which a separate process is assigned to each human and to each "storage container" for the objects. A storage container may be a shelf on which the objects are displayed or a bin in which the objects are stored, depending on the specific application in which CheckSoft is deployed.