 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State-Invariant Representations of Objects from Image Collections with State, Pose, and Viewpoint Changes
Paper and Code


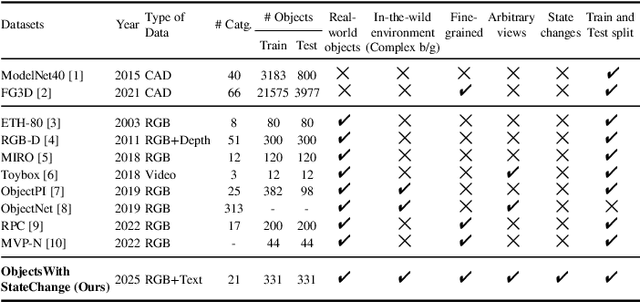
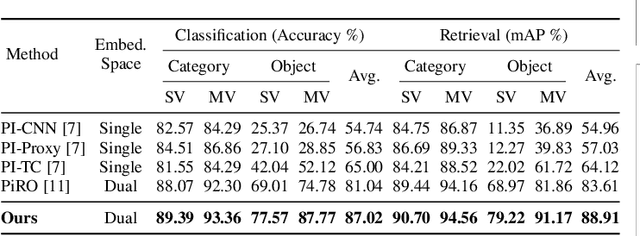
We add one more invariance - state invariance - to the more commonly used other invariances for learning object representations for recognition and retrieval. By state invariance, we mean robust with respect to changes in the structural form of the object, such as when an umbrella is folded, or when an item of clothing is tossed on the floor. Since humans generally have no difficulty in recognizing objects despite such state changes, we are naturally faced with the question of whether it is possible to devise a neural architecture with similar abilities. To that end, we present a novel dataset, ObjectsWithStateChange, that captures state and pose variations in the object images recorded from arbitrary viewpoints. We believe that this dataset will facilitate research in fine-grained object recognition and retrieval of objects that are capable of state changes. The goal of such research would be to train models capable of generating object embeddings that remain invariant to state changes while also staying invariant to transformations induced by changes in viewpoint, pose, illumination, etc. To demonstrate the usefulness of the ObjectsWithStateChange dataset, we also propose a curriculum learning strategy that uses the similarity relationships in the learned embedding space after each epoch to guide the training process. The model learns discriminative features by comparing visually similar objects within and across different categories, encouraging it to differentiate between objects that may be challenging to distinguish due to changes in their state. We believe that this strategy enhances the model's ability to capture discriminative features for fine-grained tasks that may involve objects with state changes, leading to performance improvements on object-level tasks not only on our new dataset, but also on two other challenging multi-view datasets such as ModelNet40 and ObjectPI.