 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiMask: Leveraging Epipolar Distance Based Masks in Cross-Attention for Satellite Image Matching
Mar 23, 2026The deep-learning based image matching networks can now handle significantly larger variations in viewpoints and illuminations while providing matched pairs of pixels with sub-pixel precision. These networks have been trained with ground-based image datasets and, implicitly, their performance is optimized for the pinhole camera geometry. Consequently, you get suboptimal performance when such networks are used to match satellite images since those images are synthesized as a moving satellite camera records one line at a time of the points on the ground. In this paper, we present EpiMask, a semi-dense image matching network for satellite images that (1) Incorporates patch-wise affine approximations to the camera modeling geometry; (2) Uses an epipolar distance-based attention mask to restrict cross-attention to geometrically plausible regions; and (3) That fine-tunes a foundational pretrained image encoder for robust feature extraction. Experiments on the SatDepth dataset demonstrate up to 30% improvement in matching accuracy compared to re-trained ground-based models.
SatDepth: A Novel Dataset for Satellite Image Matching
Mar 17, 2025



Recent advances in deep-learning based methods for image matching have demonstrated their superiority over traditional algorithms, enabling correspondence estimation in challenging scenes with significant differences in viewing angles, illumination and weather conditions. However, the existing datasets, learning frameworks, and evaluation metrics for the deep-learning based methods are limited to ground-based images recorded with pinhole cameras and have not been explored for satellite images. In this paper, we present ``SatDepth'', a novel dataset that provides dense ground-truth correspondences for training image matching frameworks meant specifically for satellite images. Satellites capture images from various viewing angles and tracks through multiple revisits over a region. To manage this variability, we propose a dataset balancing strategy through a novel image rotation augmentation procedure. This procedure allows for the discovery of corresponding pixels even in the presence of large rotational differences between the images. We benchmark four existing image matching frameworks using our dataset and carry out an ablation study that confirms that the models trained with our dataset with rotation augmentation outperform (up to 40% increase in precision) the models trained with other datasets, especially when there exist large rotational differences between the images.
Learning State-Invariant Representations of Objects from Image Collections with State, Pose, and Viewpoint Changes
Apr 09, 2024

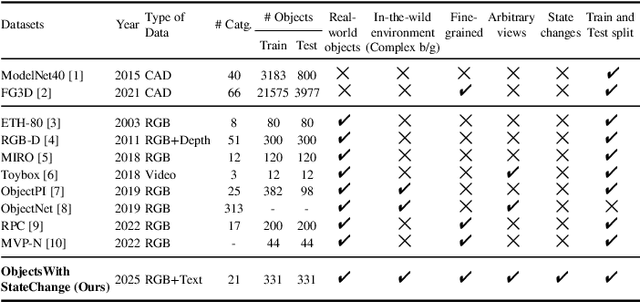
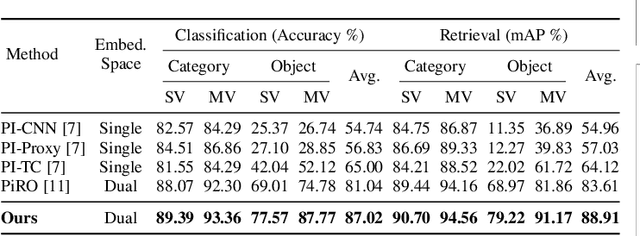
We add one more invariance - state invariance - to the more commonly used other invariances for learning object representations for recognition and retrieval. By state invariance, we mean robust with respect to changes in the structural form of the object, such as when an umbrella is folded, or when an item of clothing is tossed on the floor. Since humans generally have no difficulty in recognizing objects despite such state changes, we are naturally faced with the question of whether it is possible to devise a neural architecture with similar abilities. To that end, we present a novel dataset, ObjectsWithStateChange, that captures state and pose variations in the object images recorded from arbitrary viewpoints. We believe that this dataset will facilitate research in fine-grained object recognition and retrieval of objects that are capable of state changes. The goal of such research would be to train models capable of generating object embeddings that remain invariant to state changes while also staying invariant to transformations induced by changes in viewpoint, pose, illumination, etc. To demonstrate the usefulness of the ObjectsWithStateChange dataset, we also propose a curriculum learning strategy that uses the similarity relationships in the learned embedding space after each epoch to guide the training process. The model learns discriminative features by comparing visually similar objects within and across different categories, encouraging it to differentiate between objects that may be challenging to distinguish due to changes in their state. We believe that this strategy enhances the model's ability to capture discriminative features for fine-grained tasks that may involve objects with state changes, leading to performance improvements on object-level tasks not only on our new dataset, but also on two other challenging multi-view datasets such as ModelNet40 and ObjectPI.
Dual Pose-invariant Embeddings: Learning Category and Object-specific Discriminative Representations for Recognition and Retrieval
Mar 01, 2024
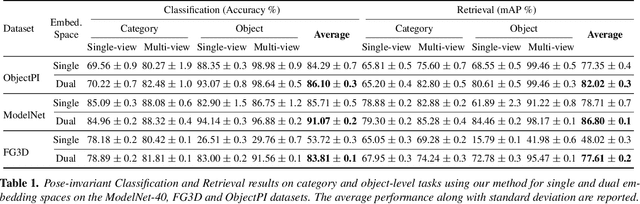

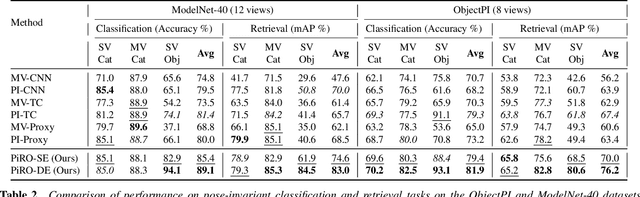
In the context of pose-invariant object recognition and retrieval, we demonstrate that it is possible to achieve significant improvements in performance if both the category-based and the object-identity-based embeddings are learned simultaneously during training. In hindsight, that sounds intuitive because learning about the categories is more fundamental than learning about the individual objects that correspond to those categories. However, to the best of what we know, no prior work in pose-invariant learning has demonstrated this effect. This paper presents an attention-based dual-encoder architecture with specially designed loss functions that optimize the inter- and intra-class distances simultaneously in two different embedding spaces, one for the category embeddings and the other for the object-level embeddings. The loss functions we have proposed are pose-invariant ranking losses that are designed to minimize the intra-class distances and maximize the inter-class distances in the dual representation spaces. We demonstrate the power of our approach with three challenging multi-view datasets, ModelNet-40, ObjectPI, and FG3D. With our dual approach, for single-view object recognition, we outperform the previous best by 20.0% on ModelNet40, 2.0% on ObjectPI, and 46.5% on FG3D. On the other hand, for single-view object retrieval, we outperform the previous best by 33.7% on ModelNet40, 18.8% on ObjectPI, and 56.9% on FG3D.
Incorporating Season and Solar Specificity into Renderings made by a NeRF Architecture using Satellite Images
Aug 02, 2023



As a result of Shadow NeRF and Sat-NeRF, it is possible to take the solar angle into account in a NeRF-based framework for rendering a scene from a novel viewpoint using satellite images for training. Our work extends those contributions and shows how one can make the renderings season-specific. Our main challenge was creating a Neural Radiance Field (NeRF) that could render seasonal features independently of viewing angle and solar angle while still being able to render shadows. We teach our network to render seasonal features by introducing one more input variable -- time of the year. However, the small training datasets typical of satellite imagery can introduce ambiguities in cases where shadows are present in the same location for every image of a particular season. We add additional terms to the loss function to discourage the network from using seasonal features for accounting for shadows. We show the performance of our network on eight Areas of Interest containing images captured by the Maxar WorldView-3 satellite. This evaluation includes tests measuring the ability of our framework to accurately render novel views, generate height maps, predict shadows, and specify seasonal features independently from shadows. Our ablation studies justify the choices made for network design parameters.
A Laplacian Pyramid Based Generative H&E Stain Augmentation Network
May 23, 2023



Hematoxylin and Eosin (H&E) staining is a widely used sample preparation procedure for enhancing the saturation of tissue sections and the contrast between nuclei and cytoplasm in histology images for medical diagnostics. However, various factors, such as the differences in the reagents used, result in high variability in the colors of the stains actually recorded. This variability poses a challenge in achieving generalization for machine-learning based computer-aided diagnostic tools. To desensitize the learned models to stain variations, we propose the Generative Stain Augmentation Network (G-SAN) -- a GAN-based framework that augments a collection of cell images with simulated yet realistic stain variations. At its core, G-SAN uses a novel and highly computationally efficient Laplacian Pyramid (LP) based generator architecture, that is capable of disentangling stain from cell morphology. Through the task of patch classification and nucleus segmentation, we show that using G-SAN-augmented training data provides on average 15.7% improvement in F1 score and 7.3% improvement in panoptic quality, respectively. Our code is available at https://github.com/lifangda01/GSAN-Demo.
Adaptive Supervised PatchNCE Loss for Learning H&E-to-IHC Stain Translation with Inconsistent Groundtruth Image Pairs
Mar 10, 2023


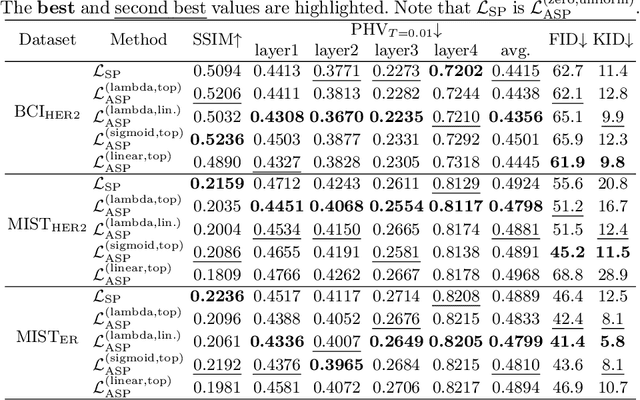
Immunohistochemical (IHC) staining highlights the molecular information critical to diagnostics in tissue samples. However, compared to H&E staining, IHC staining can be much more expensive in terms of both labor and the laboratory equipment required. This motivates recent research that demonstrates that the correlations between the morphological information present in the H&E-stained slides and the molecular information in the IHC-stained slides can be used for H&E-to-IHC stain translation. However, due to a lack of pixel-perfect H&E-IHC groundtruth pairs, most existing methods have resorted to relying on expert annotations. To remedy this situation, we present a new loss function, Adaptive Supervised PatchNCE (ASP), to directly deal with the input to target inconsistencies in a proposed H&E-to-IHC image-to-image translation framework. The ASP loss is built upon a patch-based contrastive learning criterion, named Supervised PatchNCE (SP), and augments it further with weight scheduling to mitigate the negative impact of noisy supervision. Lastly, we introduce the Multi-IHC Stain Translation (MIST) dataset, which contains aligned H&E-IHC patches for 4 different IHC stains critical to breast cancer diagnosis. In our experiment, we demonstrate that our proposed method outperforms existing image-to-image translation methods for stain translation to multiple IHC stains. All of our code and datasets are available at https://github.com/lifangda01/AdaptiveSupervisedPatchNCE.
Homography Estimation with Convolutional Neural Networks Under Conditions of Variance
Oct 22, 2020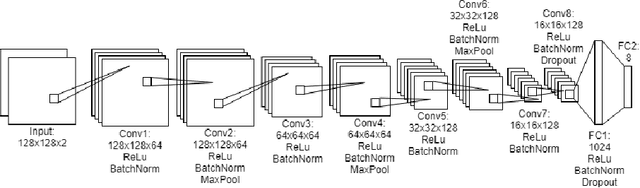
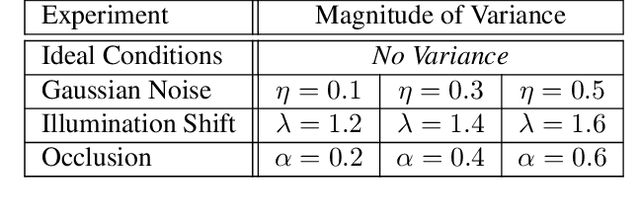
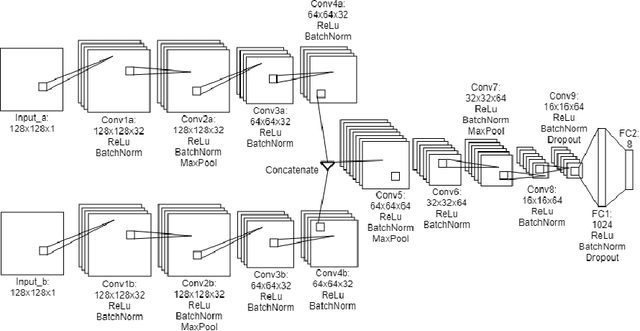
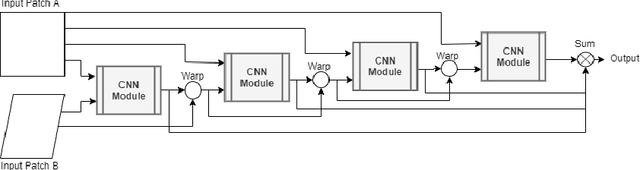
Planar homography estimation is foundational to many computer vision problems, such as Simultaneous Localization and Mapping (SLAM) and Augmented Reality (AR). However, conditions of high variance confound even the state-of-the-art algorithms. In this report, we analyze the performance of two recently published methods using Convolutional Neural Networks (CNNs) that are meant to replace the more traditional feature-matching based approaches to the estimation of homography. Our evaluation of the CNN based methods focuses particularly on measuring the performance under conditions of significant noise, illumination shift, and occlusion. We also measure the benefits of training CNNs to varying degrees of noise. Additionally, we compare the effect of using color images instead of grayscale images for inputs to CNNs. Finally, we compare the results against baseline feature-matching based homography estimation methods using SIFT, SURF, and ORB. We find that CNNs can be trained to be more robust against noise, but at a small cost to accuracy in the noiseless case. Additionally, CNNs perform significantly better in conditions of extreme variance than their feature-matching based counterparts. With regard to color inputs, we conclude that with no change in the CNN architecture to take advantage of the additional information in the color planes, the difference in performance using color inputs or grayscale inputs is negligible. About the CNNs trained with noise-corrupted inputs, we show that training a CNN to a specific magnitude of noise leads to a "Goldilocks Zone" with regard to the noise levels where that CNN performs best.
A Comparative Evaluation of SGM Variants for Dense Stereo Matching
Nov 22, 2019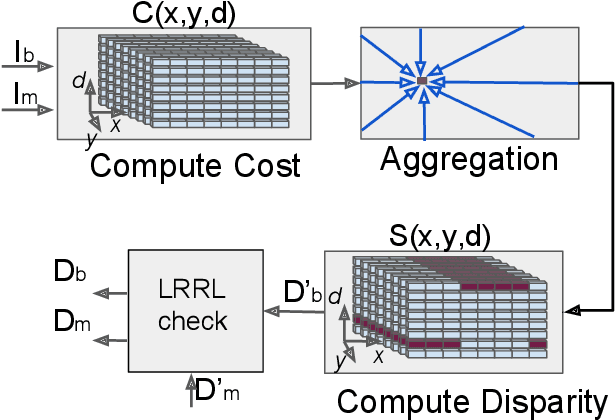

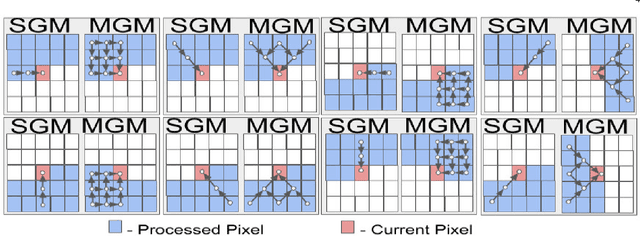
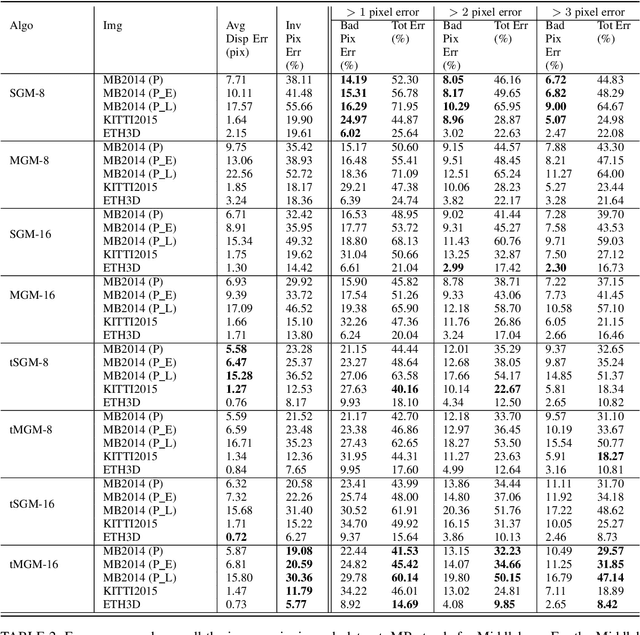
Our goal here is threefold: [1] To present a new dense-stereo matching algorithm, tMGM, that by combining the hierarchical logic of tSGM with the support structure of MGM achieves 6-8\% performance improvement over the baseline SGM (these performance numbers are posted under tMGM-16 in the Middlebury Benchmark V3 ); and [2] Through an exhaustive quantitative and qualitative comparative study, to compare how the major variants of the SGM approach to dense stereo matching, including the new tMGM, perform in the presence of: (a) illumination variations and shadows, (b) untextured or weakly textured regions, (c) repetitive patterns in the scene in the presence of large stereo rectification errors. [3] To present a novel DEM-Sculpting approach for estimating initial disparity search bounds for multi-date satellite stereo pairs. Based on our study, we have found that tMGM generally performs best with respect to all these data conditions. Both tSGM and MGM improve the density of stereo disparity maps and combining the two in tMGM makes it possible to accurately estimate the disparities at a significant number of pixels that would otherwise be declared invalid by SGM. The datasets we have used in our comparative evaluation include the Middlebury2014, KITTI2015, and ETH3D datasets and the satellite images over the San Fernando area from the MVS Challenge dataset.
A Splitting-Based Iterative Algorithm for GPU-Accelerated Statistical Dual-Energy X-Ray CT Reconstruction
May 02, 2019
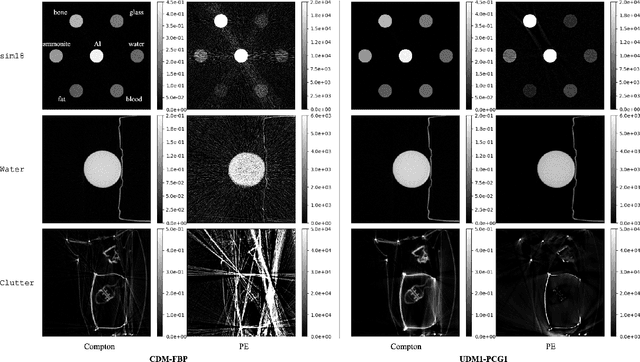
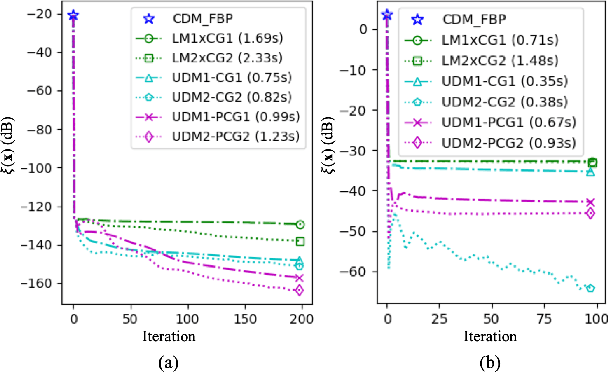
When dealing with material classification in baggage at airports, Dual-Energy Computed Tomography (DECT) allows characterization of any given material with coefficients based on two attenuative effects: Compton scattering and photoelectric absorption. However, straightforward projection-domain decomposition methods for this characterization often yield poor reconstructions due to the high dynamic range of material properties encountered in an actual luggage scan. Hence, for better reconstruction quality under a timing constraint, we propose a splitting-based, GPU-accelerated, statistical DECT reconstruction algorithm. Compared to prior art, our main contribution lies in the significant acceleration made possible by separating reconstruction and decomposition within an ADMM framework. Experimental results, on both synthetic and real-world baggage phantoms, demonstrate a significant reduction in time required for convergence.