 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Evaluation of SGM Variants for Dense Stereo Matching
Nov 22, 2019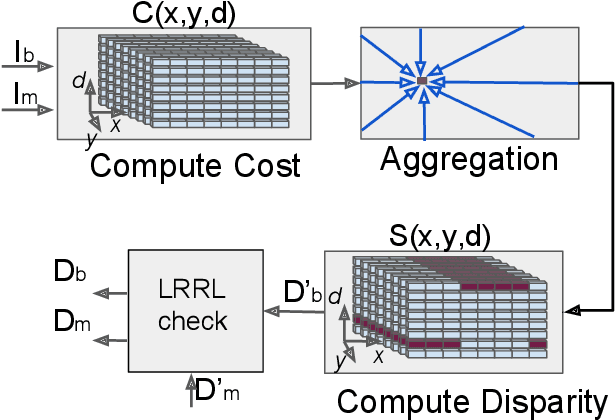

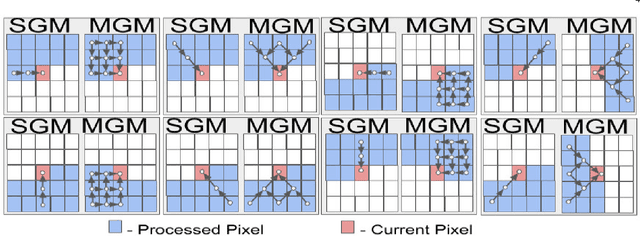
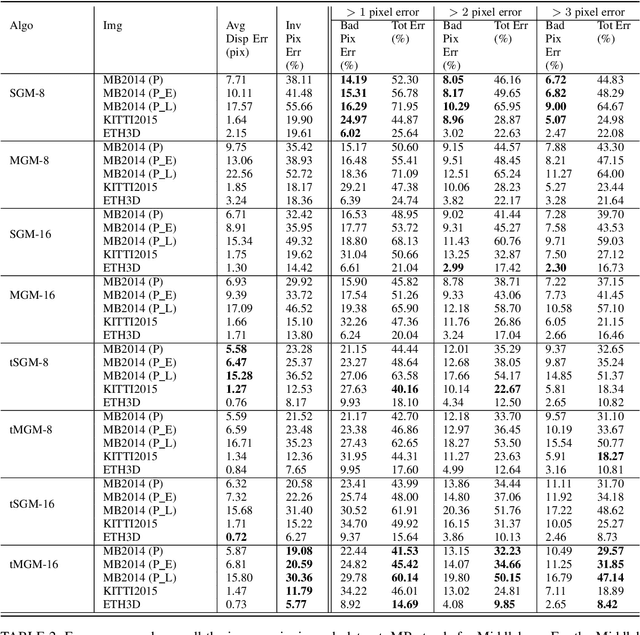
Our goal here is threefold: [1] To present a new dense-stereo matching algorithm, tMGM, that by combining the hierarchical logic of tSGM with the support structure of MGM achieves 6-8\% performance improvement over the baseline SGM (these performance numbers are posted under tMGM-16 in the Middlebury Benchmark V3 ); and [2] Through an exhaustive quantitative and qualitative comparative study, to compare how the major variants of the SGM approach to dense stereo matching, including the new tMGM, perform in the presence of: (a) illumination variations and shadows, (b) untextured or weakly textured regions, (c) repetitive patterns in the scene in the presence of large stereo rectification errors. [3] To present a novel DEM-Sculpting approach for estimating initial disparity search bounds for multi-date satellite stereo pairs. Based on our study, we have found that tMGM generally performs best with respect to all these data conditions. Both tSGM and MGM improve the density of stereo disparity maps and combining the two in tMGM makes it possible to accurately estimate the disparities at a significant number of pixels that would otherwise be declared invalid by SGM. The datasets we have used in our comparative evaluation include the Middlebury2014, KITTI2015, and ETH3D datasets and the satellite images over the San Fernando area from the MVS Challenge dataset.
A New Stereo Benchmarking Dataset for Satellite Images
Jul 09, 2019
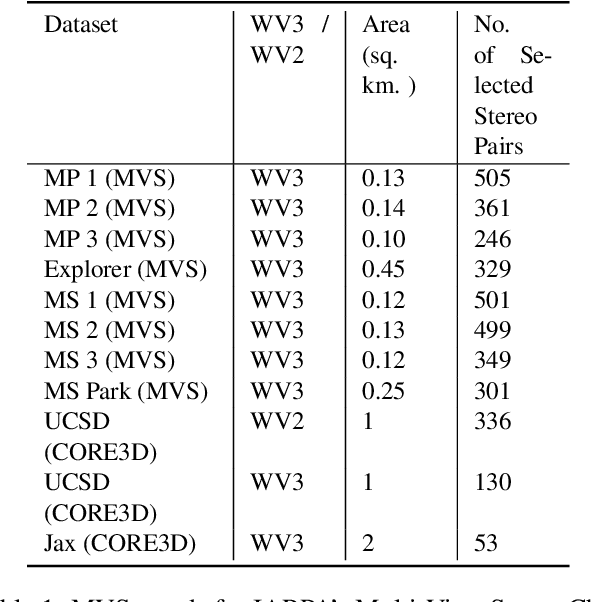

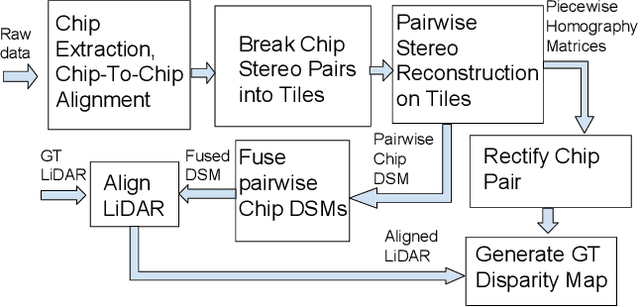
In order to facilitate further research in stereo reconstruction with multi-date satellite images, the goal of this paper is to provide a set of stereo-rectified images and the associated groundtruthed disparities for 10 AOIs (Area of Interest) drawn from two sources: 8 AOIs from IARPA's MVS Challenge dataset and 2 AOIs from the CORE3D-Public dataset. The disparities were groundtruthed by first constructing a fused DSM from the stereo pairs and by aligning 30 cm LiDAR with the fused DSM. Unlike the existing benckmarking datasets, we have also carried out a quantitative evaluation of our groundtruthed disparities using human annotated points in two of the AOIs. Additionally, the rectification accuracy in our dataset is comparable to the same in the existing state-of-the-art stereo datasets. In general, we have used the WorldView-3 (WV3) images for the dataset, the exception being the UCSD area for which we have used both WV3 and WorldView-2 (WV2) images. All of the dataset images are now in the public domain. Since multi-date satellite images frequently include images acquired in different seasons (which creates challenges in finding corresponding pairs of pixels for stereo), our dataset also includes for each image a building mask over which the disparities estimated by stereo should prove reliable. Additional metadata included in the dataset includes information about each image's acquisition date and time, the azimuth and elevation angles of the camera, and the intersection angles for the two views in a stereo pair. Also included in the dataset are both quantitative and qualitative analyses of the accuracy of the groundtruthed disparity maps. Our dataset is available for download at \url{https://engineering.purdue.edu/RVL/Database/SatStereo/index.html}
A Splitting-Based Iterative Algorithm for GPU-Accelerated Statistical Dual-Energy X-Ray CT Reconstruction
May 02, 2019
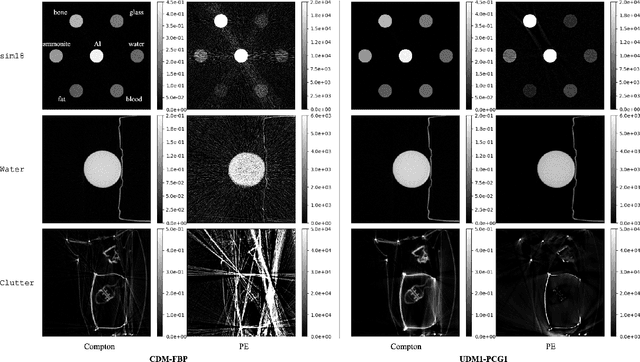
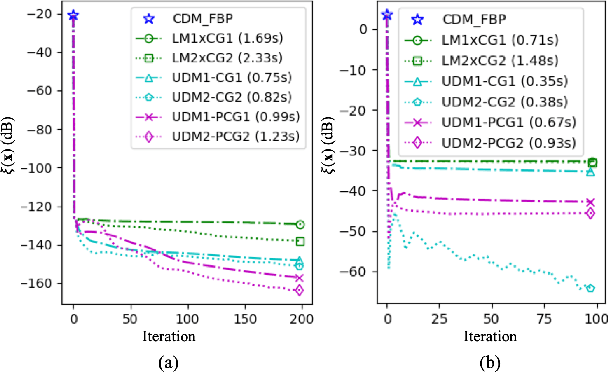
When dealing with material classification in baggage at airports, Dual-Energy Computed Tomography (DECT) allows characterization of any given material with coefficients based on two attenuative effects: Compton scattering and photoelectric absorption. However, straightforward projection-domain decomposition methods for this characterization often yield poor reconstructions due to the high dynamic range of material properties encountered in an actual luggage scan. Hence, for better reconstruction quality under a timing constraint, we propose a splitting-based, GPU-accelerated, statistical DECT reconstruction algorithm. Compared to prior art, our main contribution lies in the significant acceleration made possible by separating reconstruction and decomposition within an ADMM framework. Experimental results, on both synthetic and real-world baggage phantoms, demonstrate a significant reduction in time required for convergence.
Adaptive Target Recognition: A Case Study Involving Airport Baggage Screening
Nov 30, 2018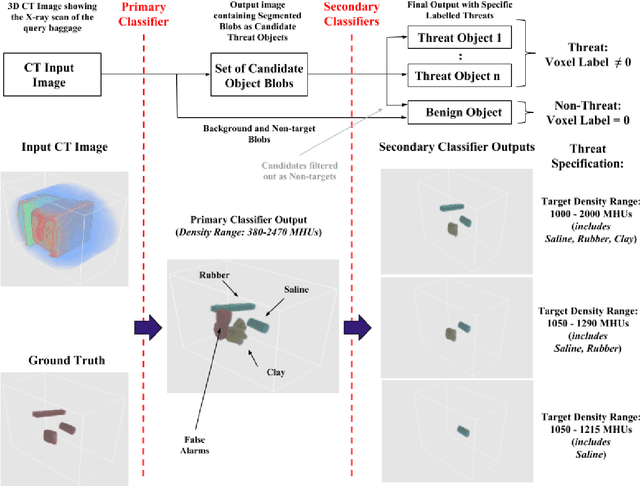
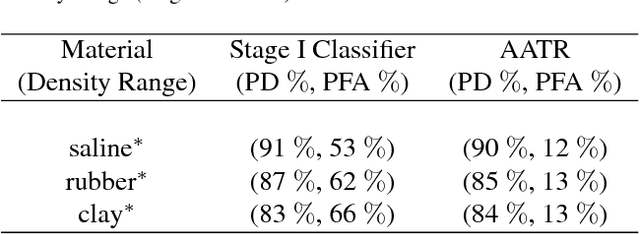
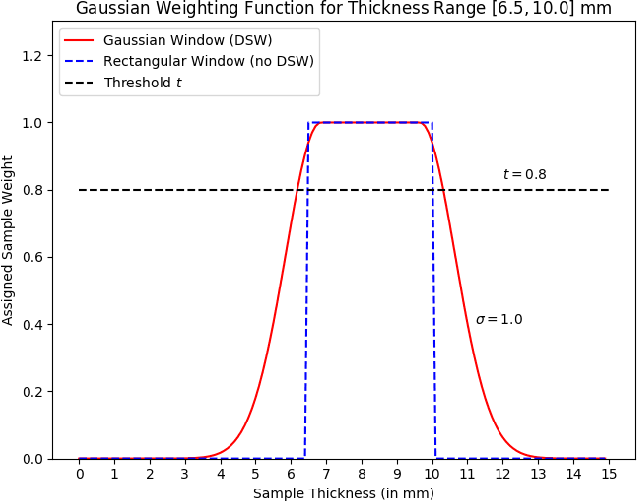
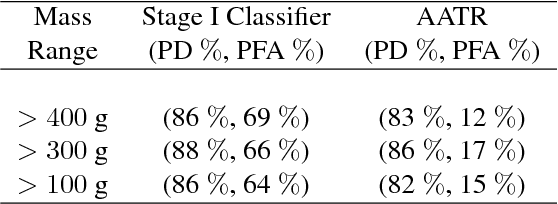
This work addresses the question whether it is possible to design a computer-vision based automatic threat recognition (ATR) system so that it can adapt to changing specifications of a threat without having to create a new ATR each time. The changes in threat specifications, which may be warranted by intelligence reports and world events, are typically regarding the physical characteristics of what constitutes a threat: its material composition, its shape, its method of concealment, etc. Here we present our design of an AATR system (Adaptive ATR) that can adapt to changing specifications in materials characterization (meaning density, as measured by its x-ray attenuation coefficient), its mass, and its thickness. Our design uses a two-stage cascaded approach, in which the first stage is characterized by a high recall rate over the entire range of possibilities for the threat parameters that are allowed to change. The purpose of the second stage is to then fine-tune the performance of the overall system for the current threat specifications. The computational effort for this fine-tuning for achieving a desired PD/PFA rate is far less than what it would take to create a new classifier with the same overall performance for the new set of threat specifications.