 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQ Test for LLMs: An Evaluation Framework for Uncovering Core Skills in LLMs
Jul 27, 2025Current evaluations of large language models (LLMs) rely on benchmark scores, but it is difficult to interpret what these individual scores reveal about a model's overall skills. Specifically, as a community we lack understanding of how tasks relate to one another, what they measure in common, how they differ, or which ones are redundant. As a result, models are often assessed via a single score averaged across benchmarks, an approach that fails to capture the models' wholistic strengths and limitations. Here, we propose a new evaluation paradigm that uses factor analysis to identify latent skills driving performance across benchmarks. We apply this method to a comprehensive new leaderboard showcasing the performance of 60 LLMs on 44 tasks, and identify a small set of latent skills that largely explain performance. Finally, we turn these insights into practical tools that identify redundant tasks, aid in model selection, and profile models along each latent skill.
Visual Riddles: a Commonsense and World Knowledge Challenge for Large Vision and Language Models
Jul 28, 2024Imagine observing someone scratching their arm; to understand why, additional context would be necessary. However, spotting a mosquito nearby would immediately offer a likely explanation for the person's discomfort, thereby alleviating the need for further information. This example illustrates how subtle visual cues can challenge our cognitive skills and demonstrates the complexity of interpreting visual scenarios. To study these skills, we present Visual Riddles, a benchmark aimed to test vision and language models on visual riddles requiring commonsense and world knowledge. The benchmark comprises 400 visual riddles, each featuring a unique image created by a variety of text-to-image models, question, ground-truth answer, textual hint, and attribution. Human evaluation reveals that existing models lag significantly behind human performance, which is at 82\% accuracy, with Gemini-Pro-1.5 leading with 40\% accuracy. Our benchmark comes with automatic evaluation tasks to make assessment scalable. These findings underscore the potential of Visual Riddles as a valuable resource for enhancing vision and language models' capabilities in interpreting complex visual scenarios.
Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Jun 29, 2024Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of "long-context", defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.
CoheSentia: A Novel Benchmark of Incremental versus Holistic Assessment of Coherence in Generated Texts
Oct 25, 2023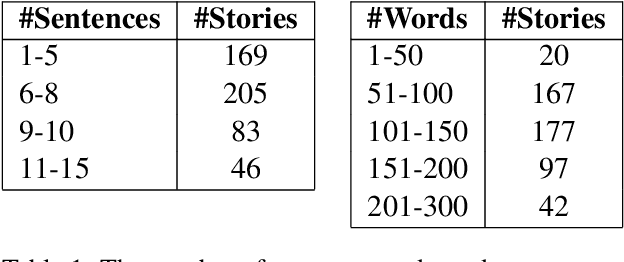


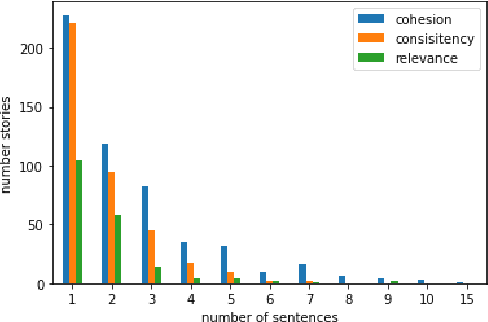
Coherence is a linguistic term that refers to the relations between small textual units (sentences, propositions), which make the text logically consistent and meaningful to the reader. With the advances of generative foundational models in NLP, there is a pressing need to automatically assess the human-perceived coherence of automatically generated texts. Up until now, little work has been done on explicitly assessing the coherence of generated texts and analyzing the factors contributing to (in)coherence. Previous work on the topic used other tasks, e.g., sentence reordering, as proxies of coherence, rather than approaching coherence detection heads on. In this paper, we introduce {\sc CoheSentia}, a novel benchmark of human-perceived coherence of automatically generated texts. Our annotation protocol reflects two perspectives; one is global, assigning a single coherence score, and the other is incremental, scoring sentence by sentence. The incremental method produces an (in)coherence score for each text fragment and also pinpoints reasons for incoherence at that point. Our benchmark contains 500 automatically-generated and human-annotated paragraphs, each annotated in both methods, by multiple raters. Our analysis shows that the inter-annotator agreement in the incremental mode is higher than in the holistic alternative, and our experiments show that standard LMs fine-tuned for coherence detection show varied performance on the different factors contributing to (in)coherence. All in all, these models yield unsatisfactory performance, emphasizing the need for developing more reliable methods for coherence assessment.
A Novel Computational and Modeling Foundation for Automatic Coherence Assessment
Oct 01, 2023Coherence is an essential property of well-written texts, that refers to the way textual units relate to one another. In the era of generative AI, coherence assessment is essential for many NLP tasks; summarization, generation, long-form question-answering, and more. However, in NLP {coherence} is an ill-defined notion, not having a formal definition or evaluation metrics, that would allow for large-scale automatic and systematic coherence assessment. To bridge this gap, in this work we employ the formal linguistic definition of \citet{Reinhart:1980} of what makes a discourse coherent, consisting of three conditions -- {\em cohesion, consistency} and {\em relevance} -- and formalize these conditions as respective computational tasks. We hypothesize that (i) a model trained on all of these tasks will learn the features required for coherence detection, and that (ii) a joint model for all tasks will exceed the performance of models trained on each task individually. On two benchmarks for coherence scoring rated by humans, one containing 500 automatically-generated short stories and another containing 4k real-world texts, our experiments confirm that jointly training on the proposed tasks leads to better performance on each task compared with task-specific models, and to better performance on assessing coherence overall, compared with strong baselines. We conclude that the formal and computational setup of coherence as proposed here provides a solid foundation for advanced methods of large-scale automatic assessment of coherence.